Le système de mémoire de ChatGPT est excellent, mais les systèmes de mémoire consomment généralement beaucoup de ressources. Comment OpenAI a-t-il réussi à faire en sorte que son système de mémoire puisse servir 800 millions d'utilisateurs ? Quelqu'un a procédé à une ingénierie inverse du système de mémoire de ChatGPT et a découvert qu'il était beaucoup plus simple que prévu. Il n'existe pas de base de données vectorielles, et les journaux de discussion ne sont pas traités par RAG. Il utilise plutôt quatre niveaux distincts : Métadonnées de session adaptées à votre environnement Des faits clairs conservés pendant longtemps, Un résumé léger des conversations récentes. Et la fenêtre coulissante de la conversation en cours. Cet article de blog détaillera le fonctionnement de chaque couche et expliquera pourquoi cette approche peut surpasser les systèmes de recherche traditionnels.

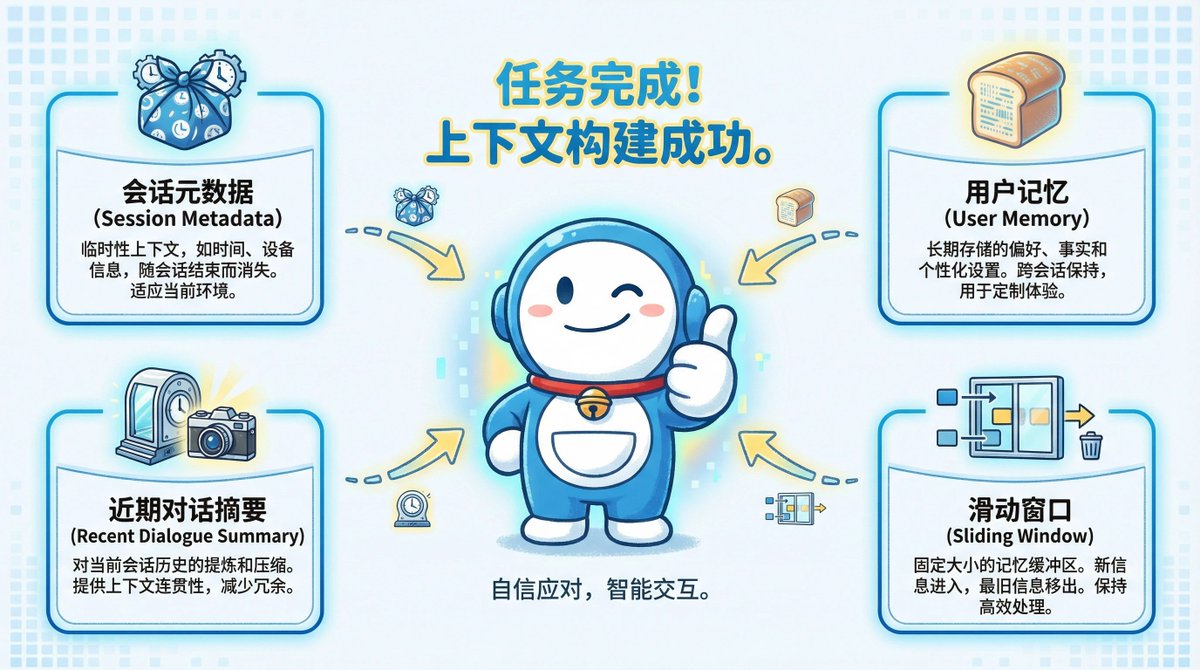
Son noyau est une pile de contexte à quatre couches. À chaque conversation, l'IA construira ce « portail » et injectera simultanément toutes les informations clés vous concernant dans le modèle. Il se compose de quatre couches qui fonctionnent ensemble.

La première couche contient des informations environnementales temporaires, telles que votre appareil et votre localisation, qui disparaissent à la fin de la session. La deuxième couche est votre profil personnel permanent, qui stocke les informations clés que vous lui demandez de mémoriser.

La troisième couche est une « carte sommaire » de vos centres d'intérêt récents, ne contenant qu'un résumé des titres des discussions, et non le texte intégral. La couche inférieure contient un enregistrement complet de la conversation en cours, comme une fenêtre coulissante, assurant une continuité instantanée. Que se passe-t-il si la fenêtre est pleine ?

La fenêtre coulissante signifie que même si la fenêtre de discussion actuelle « glisse » parce qu'elle a atteint sa limite de longueur et que le message le plus ancien est supprimé, votre mémoire permanente et le résumé de vos centres d'intérêt récents seront toujours conservés. Cela garantit que même lors de longues conversations, l'IA ne vous « oubliera » pas.
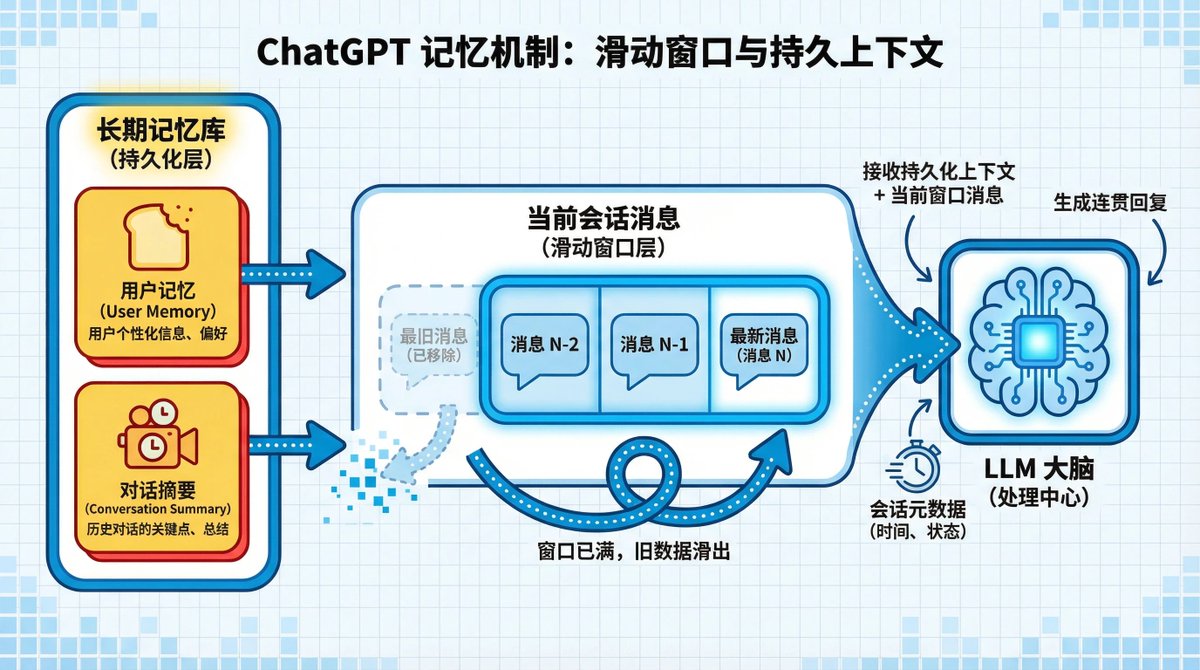
Cette architecture à quatre couches est un véritable tour de force d'ingénierie. Elle atteint un équilibre parfait entre personnalisation, performance et coût de calcul, offrant ainsi une expérience utilisateur optimale sans nécessiter les systèmes les plus complexes.

Ainsi, vous disposez d'un assistant intelligent capable dex.com/manthanguptaa/… qui semble vous comprendre de mieux en mieux. Image accompagnant l'article : Présentation PowerPoint ListenHub Lien d'origine :