Il y a quelques jours, j'ai présenté notre solution, qui a remporté la première place du défi BEHAVIOR 2025, lors de la conférence @NeurIPSConf. Nous avons maintenant publié le code source de notre solution : le code, les pondérations du modèle et un rapport technique détaillé. Laissez-moi vous expliquer ce que nous avons fait 👇
Qu’est-ce que le défi du comportement ? Dans le cadre de cette compétition, nous devions entraîner une politique capable d'effectuer 50 tâches ménagères robotisées dans une simulation de haute qualité. Cette politique contrôle un robot humanoïde bimanuel doté d'une base mobile, et les tâches durent de 1 à 14 minutes. Pour en savoir plus, consultez le post de @drfeifei : https://t.co/jDviv5d6pB
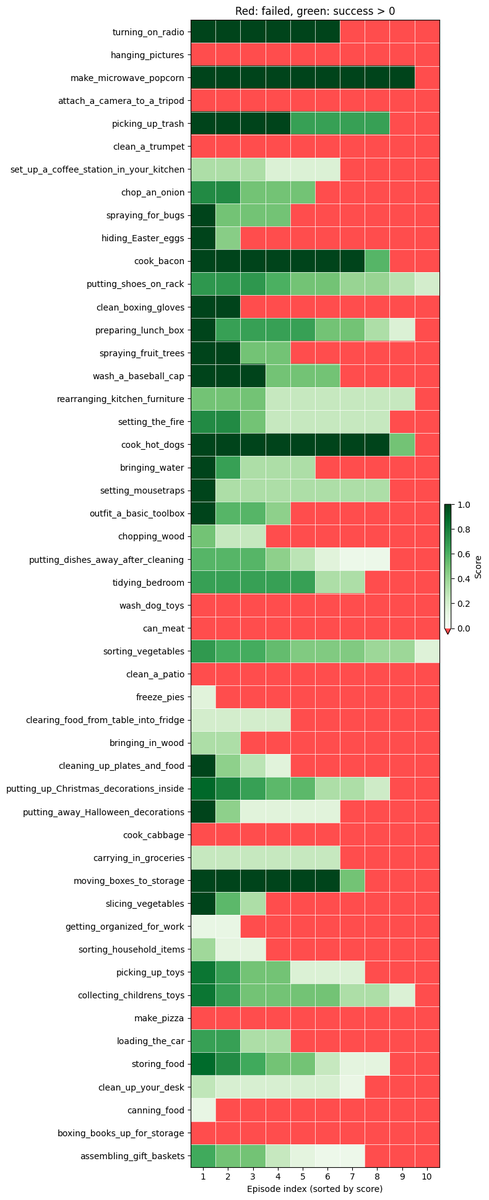
Notre équipe indépendante, composée de moi-même, @zaringleb et @akashkarnatak, a obtenu la 1ère place avec un score Q de 26 % (en incluant les succès complets et partiels).
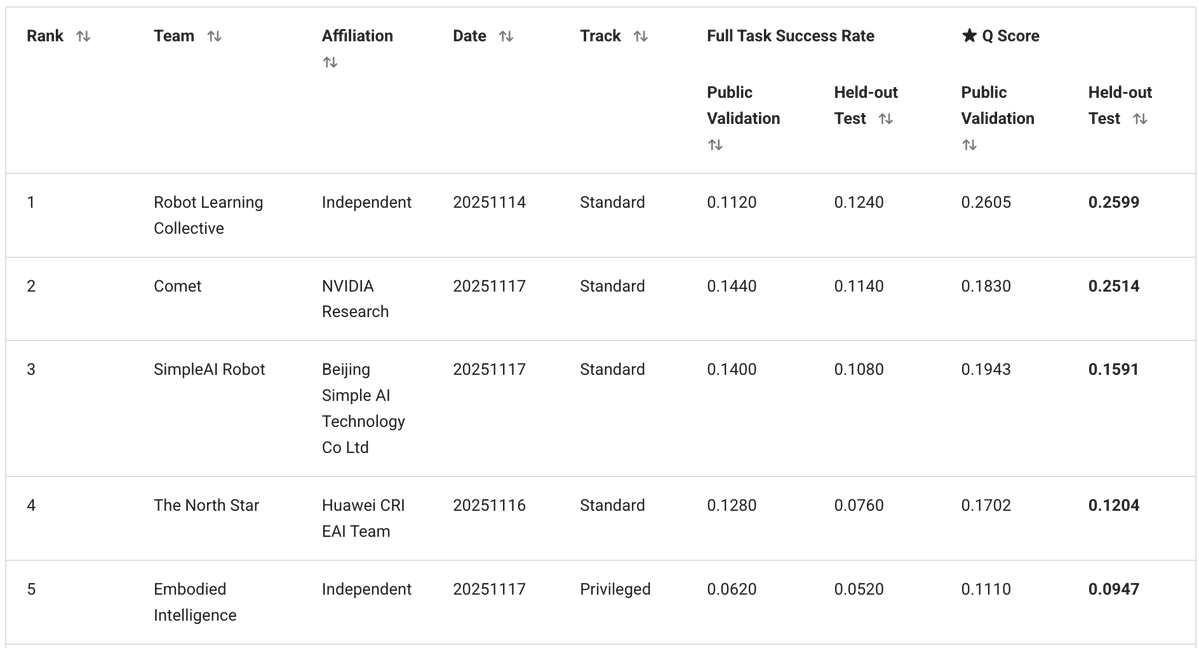
Notre solution est basée sur le VLA Pi0.5 de @physical_int et construite sur le dépôt openpi. Nous avons fortement modifié le modèle, ainsi que les processus d'entraînement et d'inférence.
- Le modèle BEHAVIOR comporte un ensemble fixe de 50 tâches. N'ayant pas besoin de généraliser à de nouvelles invites textuelles, nous avons entièrement supprimé le texte et l'avons remplacé par 50 représentations vectorielles de tâches entraînables (une par tâche). - L'ensemble de données d'entraînement contenait plusieurs modalités (RGB, profondeur, segmentation) ainsi que des annotations de sous-tâches supplémentaires, mais nous nous en sommes tenus à l'approche simple : images RGB + état du robot uniquement. - Nous prévoyons des blocs d'actions de 30 étapes (1s) et utilisons des actions delta avec une normalisation par horodatage.
De nombreuses images se ressemblent, mais correspondent à des sous-tâches très différentes. Par exemple, sur ces deux images : sur la première, le micro-ondes est vide et le robot doit d’abord l’ouvrir ; sur la seconde, le pop-corn est déjà à l’intérieur et il doit allumer le micro-ondes. Saurez-vous deviner laquelle est laquelle ? Cela perturbe également le robot. Par défaut, les VLA n'ont pas de mémoire, ils ne savent donc pas exactement quoi faire ensuite.


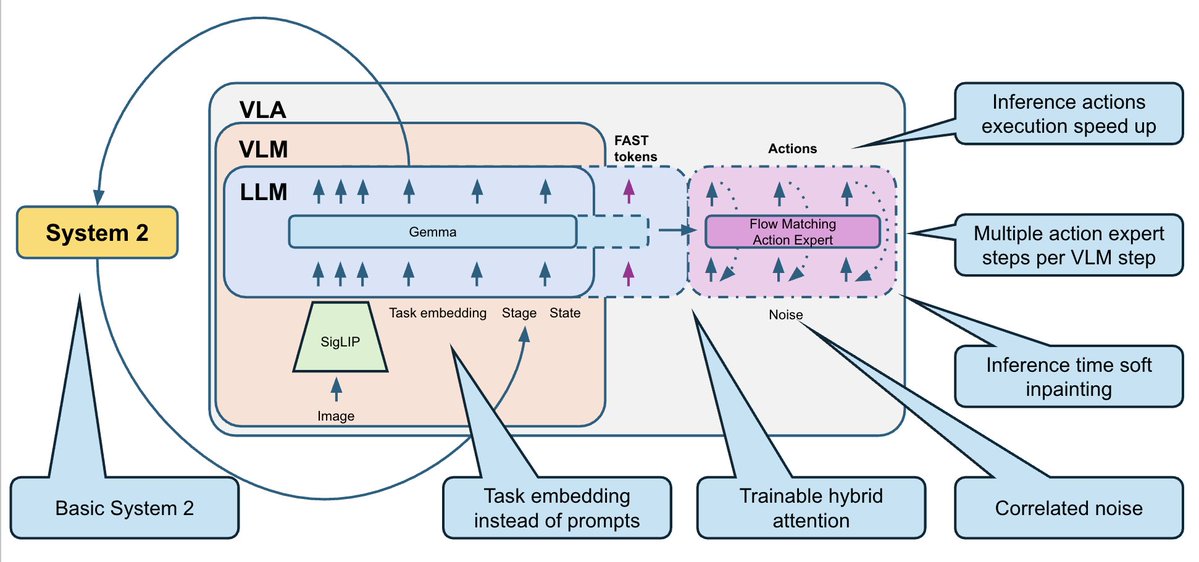
Pour remédier à cela, nous avons ajouté une logique système 2 très basique qui suit la progression de l'exécution des tâches : - Nous entraînons le VLA à prédire l'étape actuelle en tant que tête auxiliaire. - Parallèlement, elle peut utiliser cette étape pour lever les ambiguïtés dans le cadre actuel. - Lors de l'inférence, nous lissons les prédictions d'étape avec une logique de vote : les étapes ne peuvent progresser que par étapes (0, 1, 2, 3, ...). - Nous réintégrons l'étape dans le modèle comme entrée supplémentaire. Cela apporte à la politique un contexte supplémentaire sur l'avancement des tâches et corrige de nombreux échecs du type « J'ai oublié où j'en suis ».
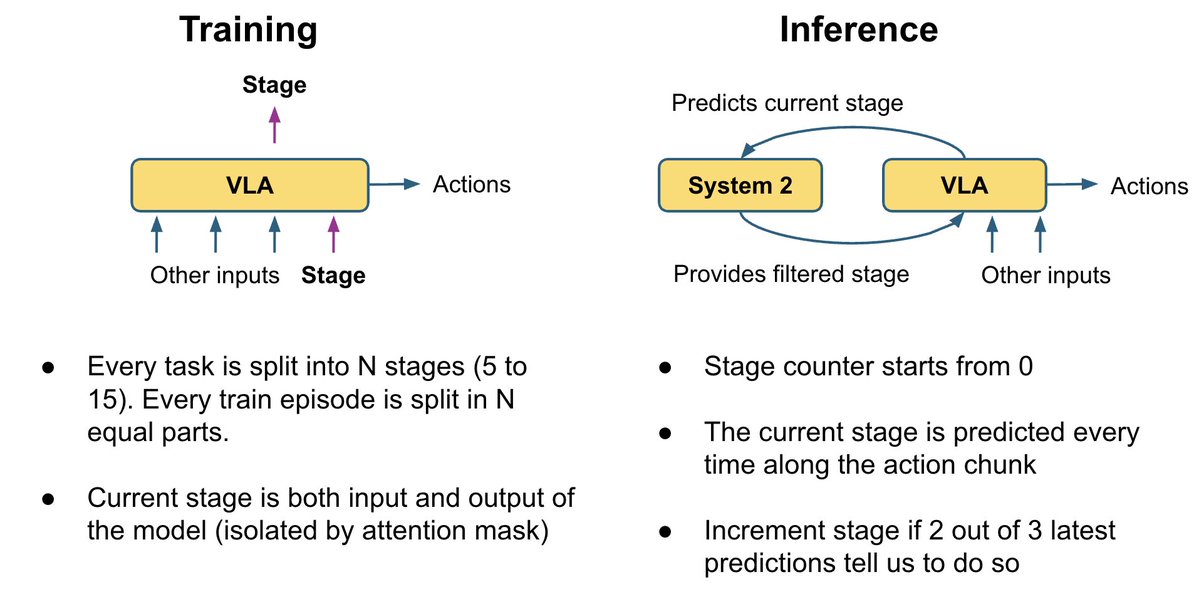
Les différents articles sur l'analyse de la couche d'action (VLA) décrivent de diverses manières la connexion entre la tête d'action et les couches VLM : certains s'intéressent à toutes les couches VLM, d'autres en ignorent la moitié, et d'autres encore ne s'intéressent qu'à la dernière ; parfois, l'attention croisée et l'auto-attention sont utilisées séparément, et parfois elles sont combinées. Au lieu de choisir et de coder en dur une de ces options, nous laissons le modèle apprendre la meilleure combinaison pour chaque couche d'action. Notre expert en actions s'appuie sur une combinaison linéaire entraînable de toutes les couches VLM, lui permettant d'apprendre le mélange optimal pour chaque couche d'action.
La méthode standard d'appariement de flux utilise un bruit gaussien indépendant et identiquement distribué. Cependant, les actions du robot sont fortement corrélées dans le temps et entre les articulations. Cela a pour conséquence que les étapes de correspondance des flux présentent une difficulté inégale : les premières étapes sont beaucoup plus difficiles, tandis que les suivantes sont beaucoup plus faciles car le modèle peut utiliser les corrélations connues comme raccourci. Nous utilisons plutôt un bruit suivant une loi normale N(0, 0,5 Σ + 0,5 I) au lieu de N(0, I), où Σ est la matrice de covariance des actions estimée à partir des données. Ceci vise à uniformiser la difficulté de toutes les étapes.
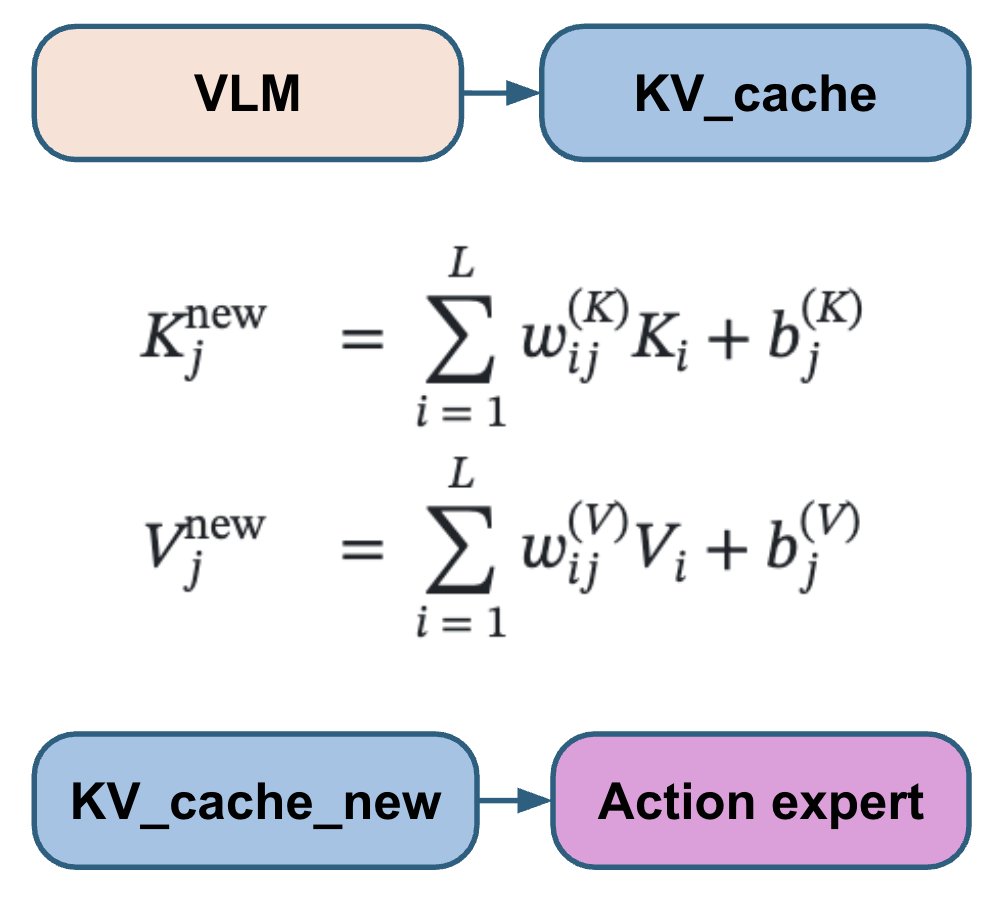
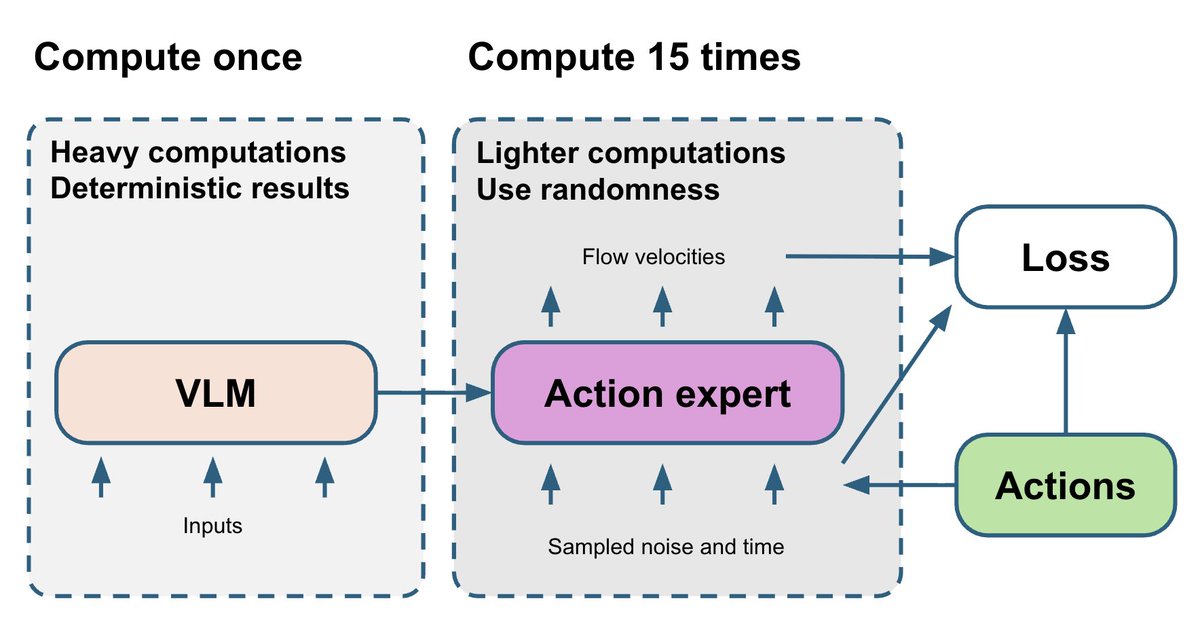
La partie VLM est la plus lourde et déterministe. L'expert d'action de correspondance de flux est relativement plus petit, mais son apprentissage dépend de deux variables aléatoires : t et le bruit. Finalement, le gradient bruité de l'expert d'action est renvoyé à la partie VLM. Pour améliorer ce résultat, nous générons 15 paires (t, bruit) différentes et exécutons l'expert d'action 15 fois pour chaque passage avant du VLM. Cela ne nécessite qu'un faible surcoût de calcul, mais stabilise le gradient issu de l'expert d'action.
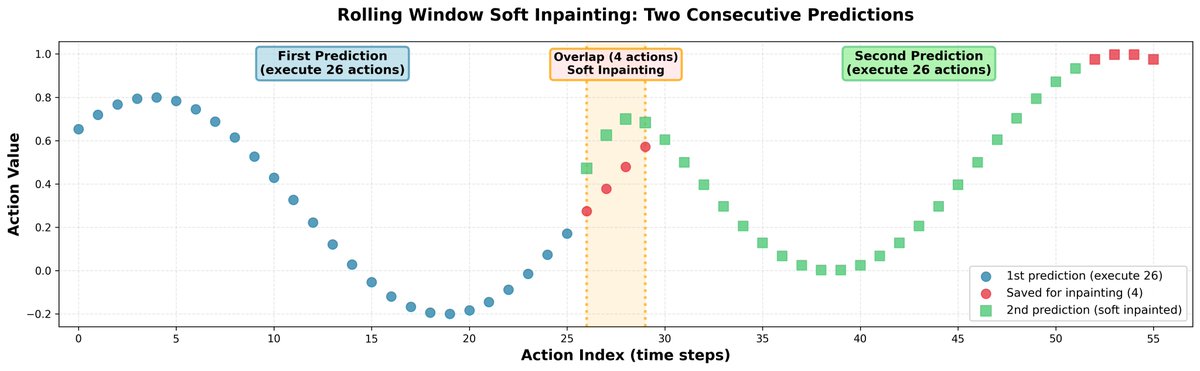
Lors de l'inférence, la prédiction de segments d'actions totalement indépendants peut entraîner des ruptures dans les trajectoires et un comportement indécis de la part de la politique. Pour remédier à cela, nous avons connecté tous les segments par remplissage : - Nous prévoyons 30 actions à la fois, mais n'en exécutons que 26. - Les 4 restants sont utilisés comme données d'entrée initiales pour la prédiction suivante. - Lors de la prédiction des 30 prochaines actions, nous intégrons légèrement les 4 premières actions afin qu'elles soient très proches de celles précédemment enregistrées. - Afin de préserver la corrélation entre les actions, nous propageons la correction au reste de l'horizon en utilisant la matrice de corrélation apprise. Résultat : trajectoires de robot fluides, sans discontinuités marquées.
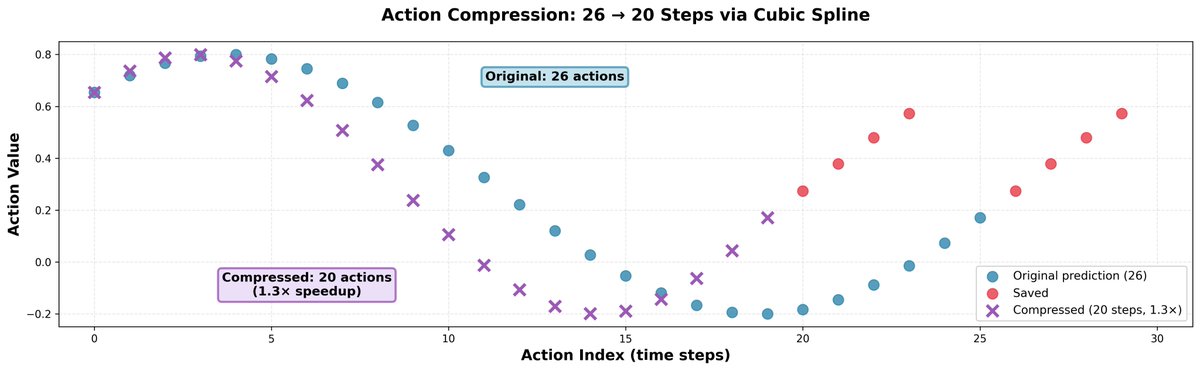
Nous avons constaté qu'aller un peu plus vite que les prédictions du modèle est souvent utile ; cela ne réduit pas la précision des mouvements, mais rend le robot plus rapide et lui permet d'en faire plus dans le même laps de temps. L'astuce est simple : on prend 26 actions et on les compresse en 20 grâce à l'interpolation par spline cubique, puis on les exécute en 20 étapes. On obtient ainsi un gain de vitesse de 1,3x.
L'ensemble de données d'entraînement pour ce problème est extrêmement propre : il ne comporte ni échecs ni exemples de récupération. Ceci pose problème pour les politiques de robotique, car elles ne peuvent pas apprendre à se remettre même d'erreurs simples. Un scénario fréquent : le robot tente de saisir l’objet, mais échoue et referme la pince. Il reste alors immobile, ignorant qu’il peut rouvrir la pince et réessayer. Nous avons implémenté une heuristique simple qui ouvre la pince si elle est fermée dans une configuration où elle ne l'a jamais été lors des démonstrations de cette tâche et de cette étape. Cette règle simple a quasiment doublé le score Q sur un sous-ensemble de tâches dans notre étude préliminaire.
Mais parfois, les comportements de récupération émergeaient naturellement de l'entraînement multitâche. Dans la première vidéo, vous pouvez observer le comportement typique en cas d'échec d'une politique entraînée sur une ou quelques tâches seulement. Si elle commet une erreur (par exemple, si elle laisse tomber l'image par terre), elle s'arrête complètement et ne fait rien, car une telle situation ne s'est jamais produite dans les données d'entraînement. Dans la deuxième vidéo, vous pouvez observer le comportement de récupération de la politique entraînée sur les 50 tâches. Ayant déjà rencontré des tâches consistant à ramasser des objets au sol, elle généralise à cette situation et récupère l'image tombée.
Les ressources de calcul étaient essentielles pour cette compétition. L'ensemble des données d'entraînement comprend plus de 1 000 heures de données de téléopération, et une époque sur 8 GPU H200 prend environ deux semaines. Nous avons entraîné la politique pendant environ 30 jours, soit approximativement deux époques. Nous sommes très reconnaissants à @nebiusai de nous avoir sponsorisés avec des crédits GPU qui ont rendu cela possible.
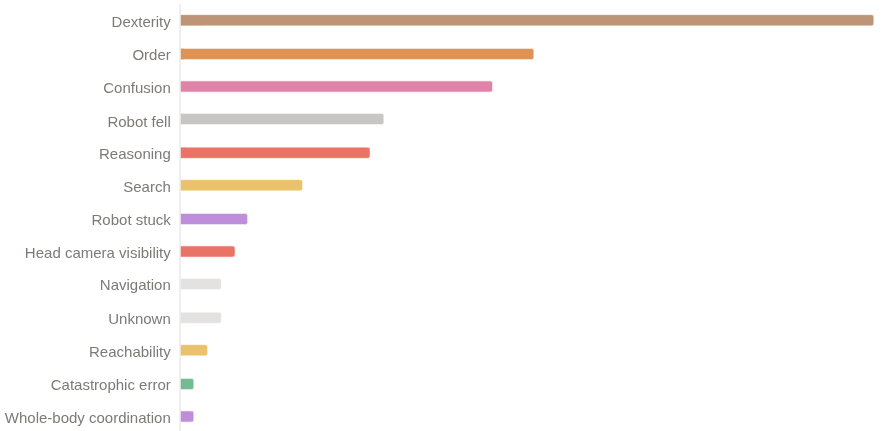
Même si nous avons remporté la première place, nous pensons qu'il existe encore une marge de progression considérable. Nous avons obtenu un score q de 26 % et un taux de réussite binaire de 11 à 12 %. Les principales raisons pour lesquelles cette politique échoue encore sont les suivantes : - Problèmes de dextérité (saisie, relâchement) - Erreurs de progression dans les longues séquences - Se sentir désorienté après être entré dans des états hors distribution
Nous avons rendu open source l'intégralité de notre solution : le code, les pondérations du modèle et ungithub.com/IliaLarchenko/…illé. Codhuggingface.co/IliaLarchenko/…tbaE Poids : arxiv.org/abs/2512.06951 Rapport technologique : https://t.co/TeFiiTha0d Je publierai également une vidéo de présentation plus détaillée ultérieurement. Restez connectés 🎥