Dans l'épisode d'aujourd'hui de l'horreur de la programmation... Dans la documentation Python de la fonction random.seed(), on nous dit "Si a est un int, il est utilisé directement." [1] Mais si vous initialisez avec 3 ou -3, vous obtenez exactement le même objet RNG, produisant les mêmes flux. (Je viens de l'apprendre). Dans NanoChat, j'utilisais le signe comme une méthode (que je croyais) astucieuse pour obtenir des séquences RNG différentes pour les ensembles d'entraînement et de test. D'où ce bug épineux, car maintenant, entraînement = test. J'ai trouvé le code CPython responsable dans cpython/Modules/_randommodule.c [2], où à la ligne 321, on voit dans un commentaire : « Cet algorithme repose sur le fait que le nombre n'est pas signé. Donc : si l'argument est un PyLong, utilisez sa valeur absolue. » suivi de n = PyNumber_Absolute(arg); qui appelle explicitement abs() sur votre graine pour la rendre positive, en ignorant le bit de signe. Mais ce commentaire est lui aussi erroné, voire trompeur. En interne, Python utilise l'algorithme Mersenne Twister MT19937, qui, dans le cas général, possède 19 937 bits d'état (non nuls). Python prend votre entier (ou autre objet) et répartit cette information sur ces bits. En principe, le bit de signe aurait pu être utilisé pour augmenter le nombre de bits d'état. L'algorithme ne nécessite en aucun cas que le nombre soit non signé. Il a été décidé de ne pas intégrer le bit de signe (ce qui, à mon avis, était une erreur). Un exemple simple aurait pu consister à appliquer la transformation suivante : n → 2*abs(n) + int(n même séquence. Mais rien ne garantit que des graines différentes produisent des séquences différentes. En principe, Python ne promet donc pas que, par exemple, `seed(5)` et `seed(6)` soient des flux de génération de nombres aléatoires différents (même si cela est souvent implicitement admis dans de nombreuses applications). En effet, on constate que `seed(5)` et `seed(-5)` sont des flux identiques. Il est donc déconseillé de les utiliser pour séparer les comportements d'entraînement et de test en apprentissage automatique. Un des pièges les plus amusants et les plus déroutants que j'aie rencontrés récemment en programmation. Rendez-vous dans le prochain épisode ! [1] https://t.co/srv1ZBlDsi [2]
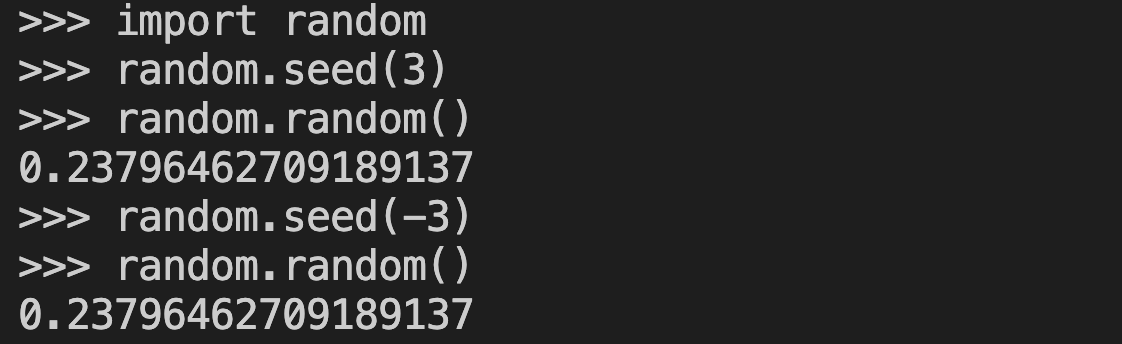
Merci à ericsilberstein1 sur github d'avoir repéré le bgithub.com/karpathy/nanoc…iivgN (Ce n'est pas un bug important et il n'apparaît que lors de l'évaluation de la tâche synthétique SpellingBee, mais quand même).