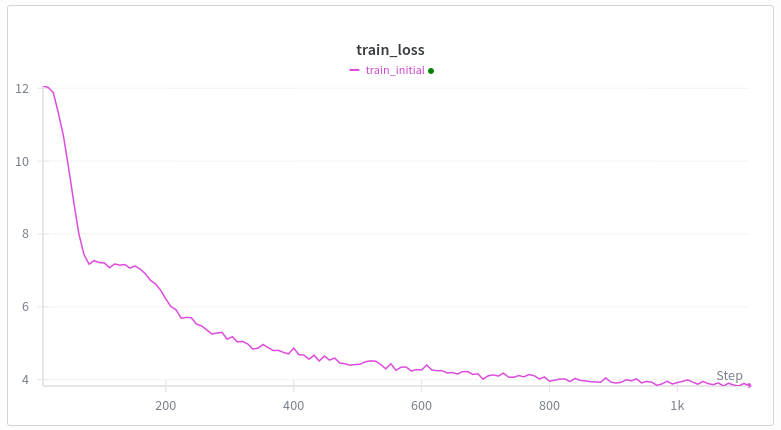
Chaque fois que j'ai entraîné un transformeur à partir de zéro sur du texte web, la courbe de perte ressemble à ceci. La première chute est logique, mais pourquoi la seconde ? Gemini me raconte des bêtises. Architecture identique à celle de GPT-2, à l'exception de Swiglu, Rope et des plongements non liés. entraînement: muon + adam échauffement linéaire (jusqu'à 500 pas) Ma meilleure hypothèse est le mème de la formation de la tête d'induction, mais si j'ai bien compris, cela se produit assez tard, après plusieurs milliers d'étapes d'entraînement ou environ un milliard de jetons, et j'ai 100 000 jetons par lot. Y a-t-il des spécialistes de la formation aux transformateurs qui savent pourquoi cela se produit ?