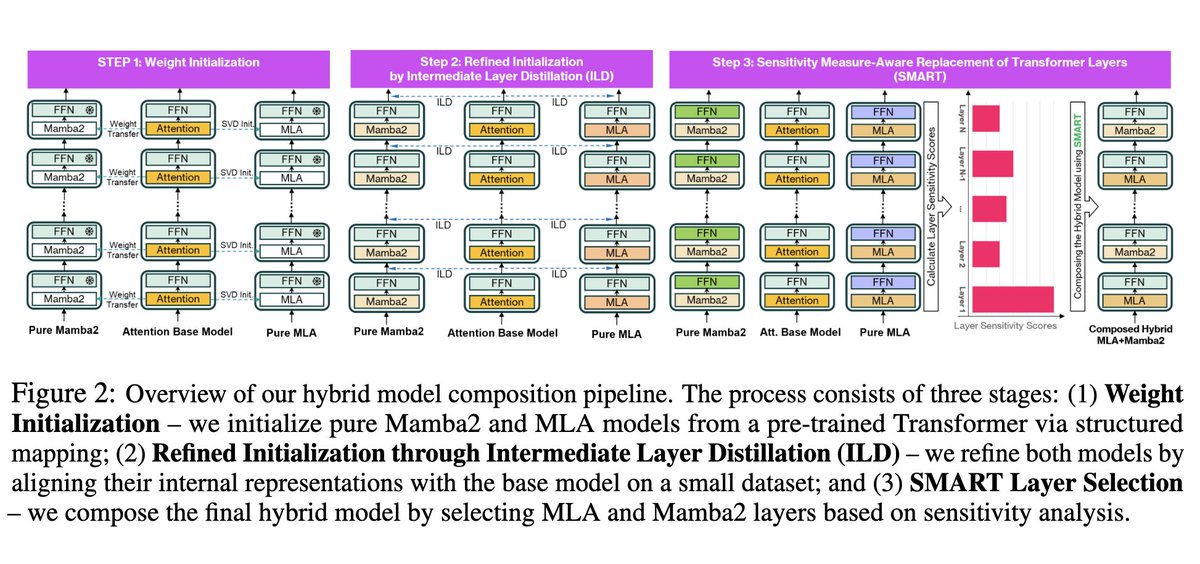
Passé inaperçu : un hybride Mamba-2 + MLA, *post-entraîné* à partir de Llama 3. Nous savions que la conversion GQA vers MLA complet était possible. Kimi a prouvé qu'il était possible de combiner MLA et attentions linéaires (KDA est toutefois plus sophistiqué que Mamba-2), mais ils ont été entraînés à partir de zéro. C'est techniquement impressionnant.