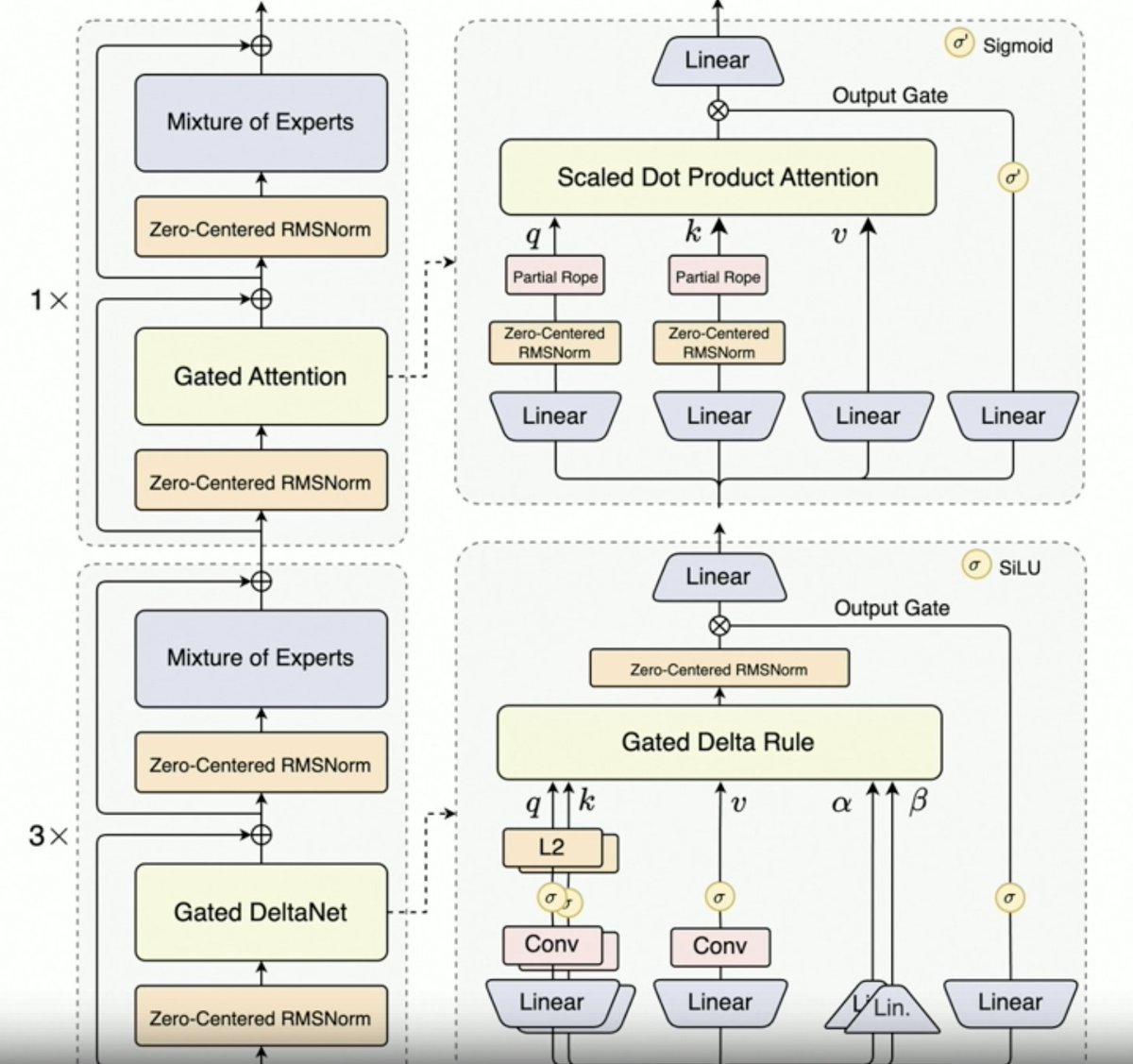
Per, @JustinLin610 (Qwen 3 Coder) parle de données synthétiques, d'apprentissage par renforcement, de mise à l'échelle, d'attention de Gates et de direction future. - La réflexion ne se prête pas bien à la programmation. La longueur du contexte est de 256 Ko, mais 128 Ko suffisent pour les agents de codage, car le code est filtré avant d'être ajouté au contexte. L'API prend en charge 1 million de jetons. Qwen 2.5 Coder a permis de générer des données synthétiques avec Qwen 3 Coder. Cela impliquait de prendre des données bruitées, de les nettoyer et de les réécrire. L'environnement à grande échelle de l'équipe Qwen pour l'apprentissage par renforcement utilise le planificateur MegaFlow. Ils emploient plusieurs structures/agents pour générer des trajectoires (intéressant). - Les performances en RL s'améliorent considérablement, les efforts en valent donc largement la peine. Qwen3-Max a permis à Alibaba de se développer à une échelle bien plus importante. L'innovation y est peu présente, mais l'échelle est considérablement plus grande. Tout cela est dû à la mise à l'échelle. La prochaine génération de LLM Qwen intégrera l'attention delta à porte, compte tenu du succès de Qwen3-Next. Elle pourrait également combiner des techniques d'attention parcimonieuse (DSA ?). - Orientation future 1. Nouvelle architecture pour le long terme 2. Fonctionnalités de recherche intégrées 3. Intégration de la vision dans les modèles de codage pour les agents d'utilisation informatique 4. Techniques pour les tâches à long terme (24 heures ou plus)