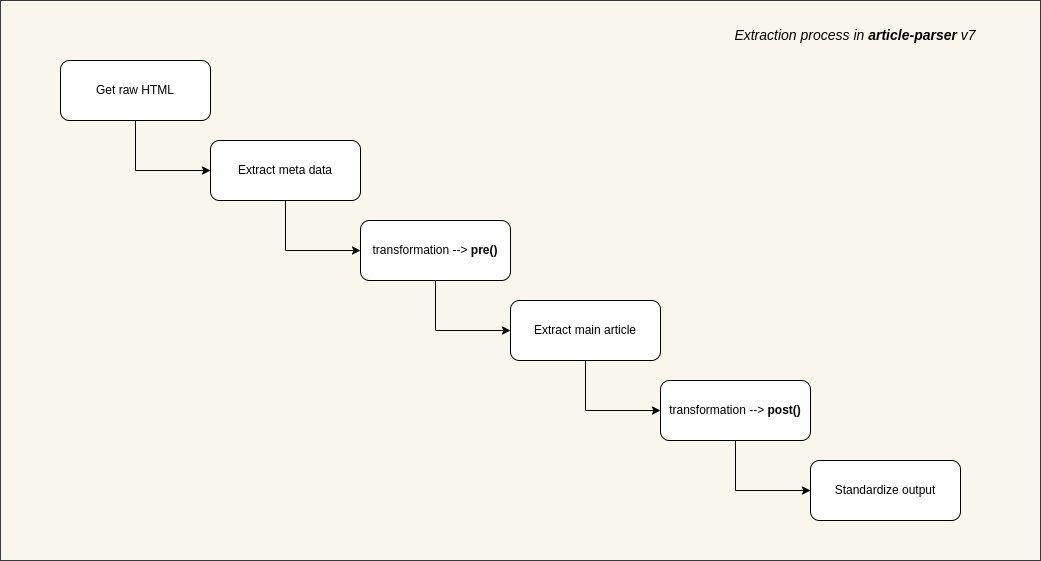
Lorsque vous souhaitez extraire le contenu d'une page Web pour alimenter une IA ou créer une application de lecture ultérieure, le principal obstacle n'est souvent pas les requêtes réseau, mais la manière d'extraire avec précision le texte principal d'un écran rempli de publicités, de barres latérales et d'éléments de navigation. J'ai récemment découvert la bibliothèque open-source article-extractor, conçue spécifiquement pour résoudre ce problème. Elle permet d'identifier et d'extraire intelligemment les données essentielles d'un article à partir d'URL complexes. Il peut automatiquement supprimer les éléments superflus de la page et restituer les titres structurés, le texte principal, les images de couverture, les auteurs et même le temps de lecture. GitHub : https://t.co/bF0hvCYr8I Il prend en charge une logique de transformation personnalisée, vous permettant d'écrire des règles de prétraitement ou de post-traitement pour des domaines spécifiques, ce qui améliore considérablement la précision de l'extraction. Il est compatible avec les environnements Node.js, Bundle et navigateurs, et prend en charge la configuration des proxys et des en-têtes personnalisés pour faire face facilement aux stratégies anti-scraping. Si vous développez des agrégateurs de contenu, des lecteurs RSS ou si vous avez besoin de nettoyer des données de pages Web pour l'entraînement de grands modèles, cette bibliothèque mérite amplement sa place dans votre boîte à outils.