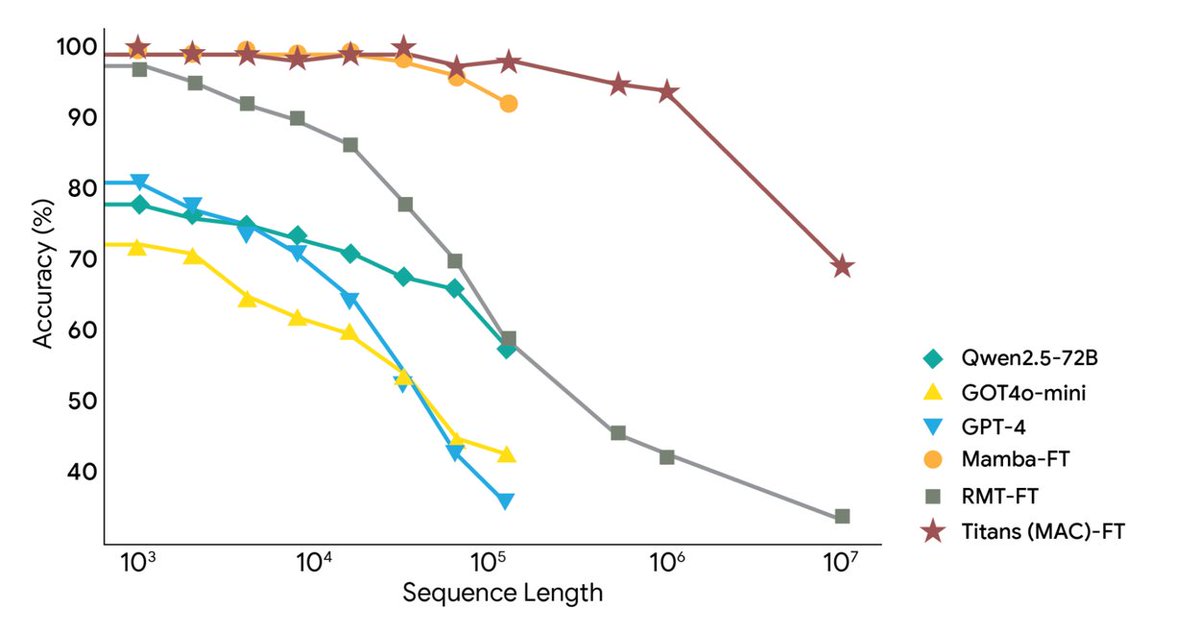
Google Research a publié aujourd'hui deux nouveaux frameworks : l'architecture Titans et le framework MIRAS, qui répondent aux défis posés par le contexte extrêmement long et la mémoire à long terme de l'IA, étendant le contexte à plus de 2 millions de jetons. Il utilise une mémoire neuronale profonde pour l'apprentissage en temps réel, permettant aux grands modèles de mettre à jour leur mémoire à long terme en temps réel pendant leur exécution, atteignant ainsi la vitesse des RNN et la précision des Transformers. Titans permet à l'IA de mettre à jour son module de mémoire à long terme en temps réel pendant son exécution. MIRAS fournit un modèle théorique pour un système de mémoire unifié. Titans utilise un perceptron multicouche (MLP) pour créer une mémoire à long terme, contrairement aux vecteurs fixes d'un RNN traditionnel. Pour chaque nouveau mot lu, le « niveau de surprise » est calculé ; les mots sans intérêt sont ignorés, tandis que ceux qui sont remarquables sont enregistrés dans la mémoire à long terme et les paramètres du MLP sont mis à jour en conséquence. Pour contrôler la capacité, une fonction de dégradation du poids a été ajoutée, effaçant automatiquement les informations anciennes non pertinentes. En définitive, la couche d'attention peut récupérer la mémoire à long terme « à la demande » ou ne prendre en compte que le contexte le plus récent. MiRAS propose une perspective unifiée, arguant que les modèles séquentiels classiques résolvent fondamentalement le même problème : comment combiner efficacement les nouvelles informations aux anciens souvenirs sans oublier les informations importantes. Ce sont tous des formes différentes de systèmes de « mémoire associative ». Il décompose le système de mémoire d'un modèle d'IA en quatre parties clés : la structure de la mémoire, le biais d'attention, les portes de rétention et l'algorithme de mémoire. En outre, elle propose d'utiliser des méthodes mathématiques de jugement plus complexes et sophistiquées, ce qui permettrait de concevoir un système de mémoire plus puissant et plus robuste. Les expériences montrent que Titans surpasse Transformer++, Mamba-2 et Gated DeltaNet de taille similaire dans la modélisation du langage, le raisonnement de bon sens, la modélisation de l'ADN, la prédiction de séries temporelles et la tâche BABILong de 2 millions de jetons, et surpasse même GPT-4. #Mémoire IA #Titans