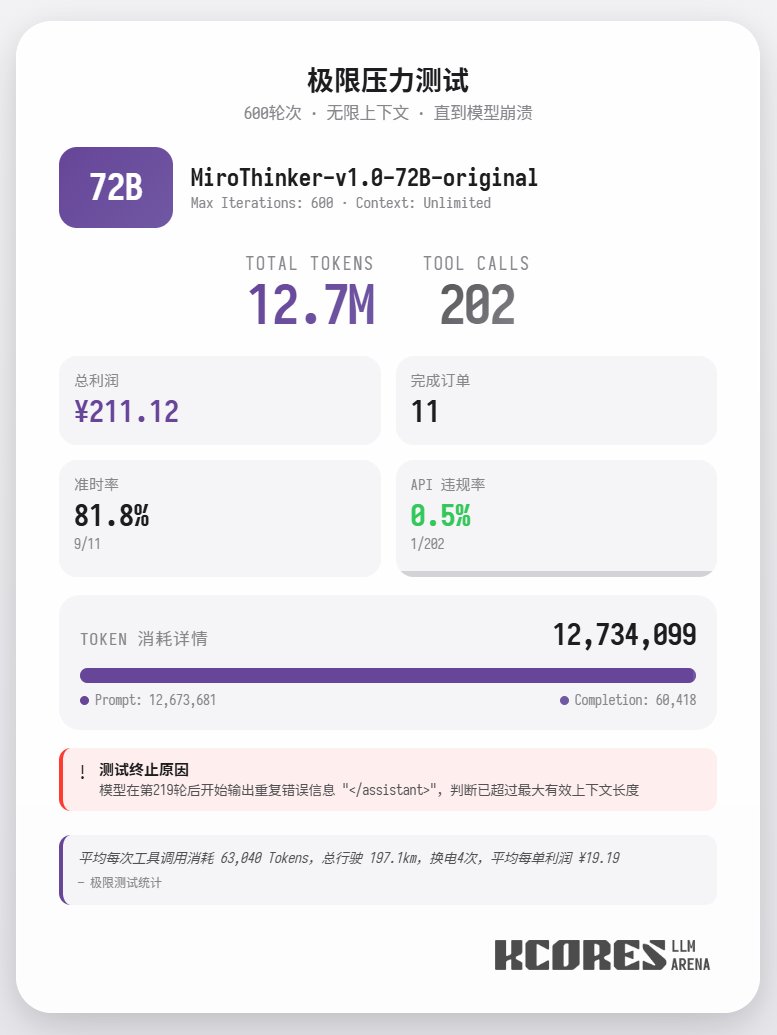
De plus, un test extrême a été mené avec le modèle 72B, sans restriction de contexte, pour la livraison de repas. Le modèle a effectué 202 appels d'outils, consommant 12,7 millions de jetons, traitant 11 commandes et générant 211,12 points. Un seul de ces 202 appels a entraîné une violation d'API (appel de méthode incorrect), démontrant ainsi que le modèle 72B conserve d'excellentes performances de rappel et une grande capacité d'appel d'outils, même dans des contextes très longs. En résumé, 72B excelle dans les tâches complexes d'agents, 8B se distingue par son efficacité en matière de ressources, et 30B nécessite des améliorations au niveau de l'exécution. Si vous devez utiliser un grand nombre d'outils, notamment dans le cadre de scénarios de recherche d'agents, la suite de modèles MiroThinker pourrait vous convenir.