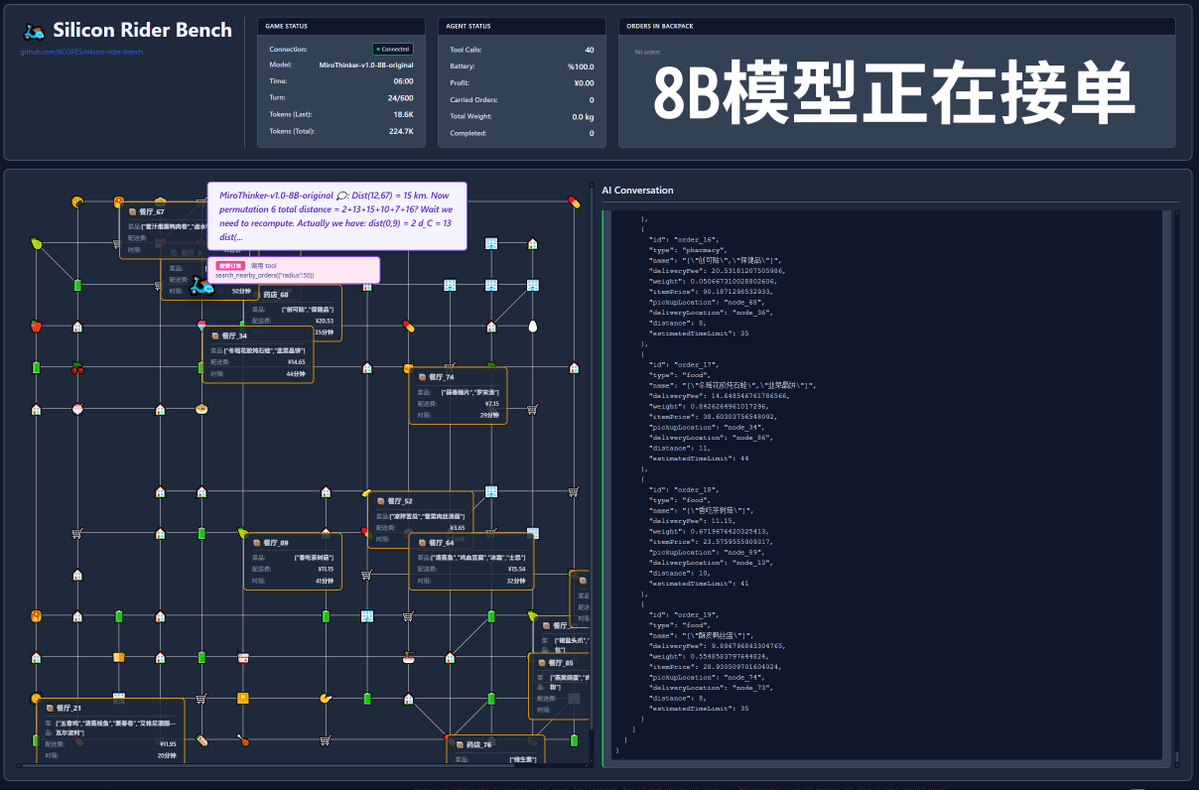
600 appels d'outils ? Voyons le test en conditions réelles avec le modèle MiroThinker-v1.0 ! MiroMind AI a lancé son nouveau modèle, MiroThinker-v1.0, une série de modèles optimisés pour les agents de recherche, disponibles en versions 72B, 30B et 8B. Son principal atout réside dans ses capacités améliorées de raisonnement assisté par outils et de recherche d'informations, permettant jusqu'à 600 appels d'outils dans un contexte maximal ! Il est donc temps que mon projet original soit mis en avant : si ce modèle devait proposer des plats à emporter, pourrait-il réussir ? Ce test a utilisé le modèle officiel, disponible à l'adresse : https://t.co/5Eyuq3f8be. Le matériel utilisé était un H100 80G SXM *4 et le moteur d'inférence était SGLang. Pour ce test, j'ai développé un nouveau framework de test appelé SiliconRiderBench. Ce framework génère aléatoirement des commandes de livraison de repas, et l'IA doit se comporter comme un livreur, en utilisant des fonctions logicielles pour accepter les commandes, récupérer et livrer les repas, et même changer les batteries de scooters électriques. Nous utilisons ce framework pour tester la rentabilité maximale du modèle lorsqu'il exploite efficacement ces fonctions logicielles ! #MiroThinker #MiroMindAI #ToolCall #KCORES Large Model Arena



Commençons par examiner le test de performance. Le modèle a exécuté 100 dialogues, la fenêtre de contexte conservant les 20 dialogues les plus récents. Conclusion : le modèle 72B a obtenu les meilleurs résultats, effectuant 155 appels d'outils en 100 dialogues, livrant 4 commandes de repas et générant un profit de 65,31. Vient ensuite le modèle 8B, qui a effectué un total de 102 interventions, livré un total de 4 commandes à emporter et généré 49,17. Puis est venu le modèle 30B, qui a effectué un total de 145 interventions, livré un total de 1 commande à emporter et généré 22,57.
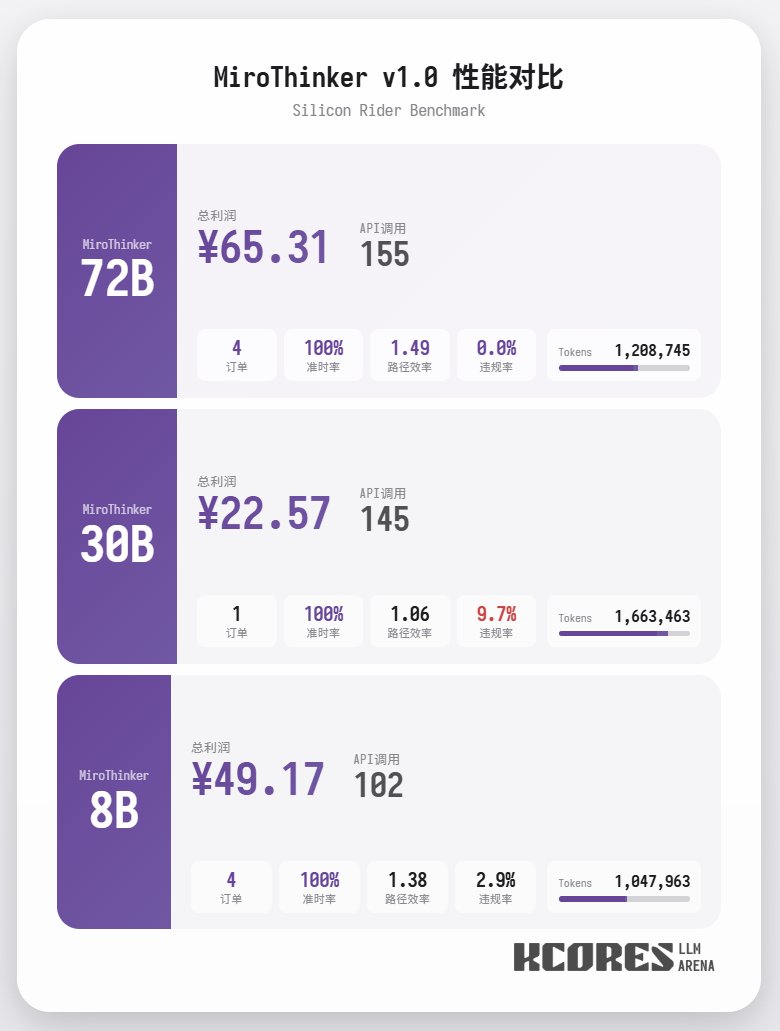
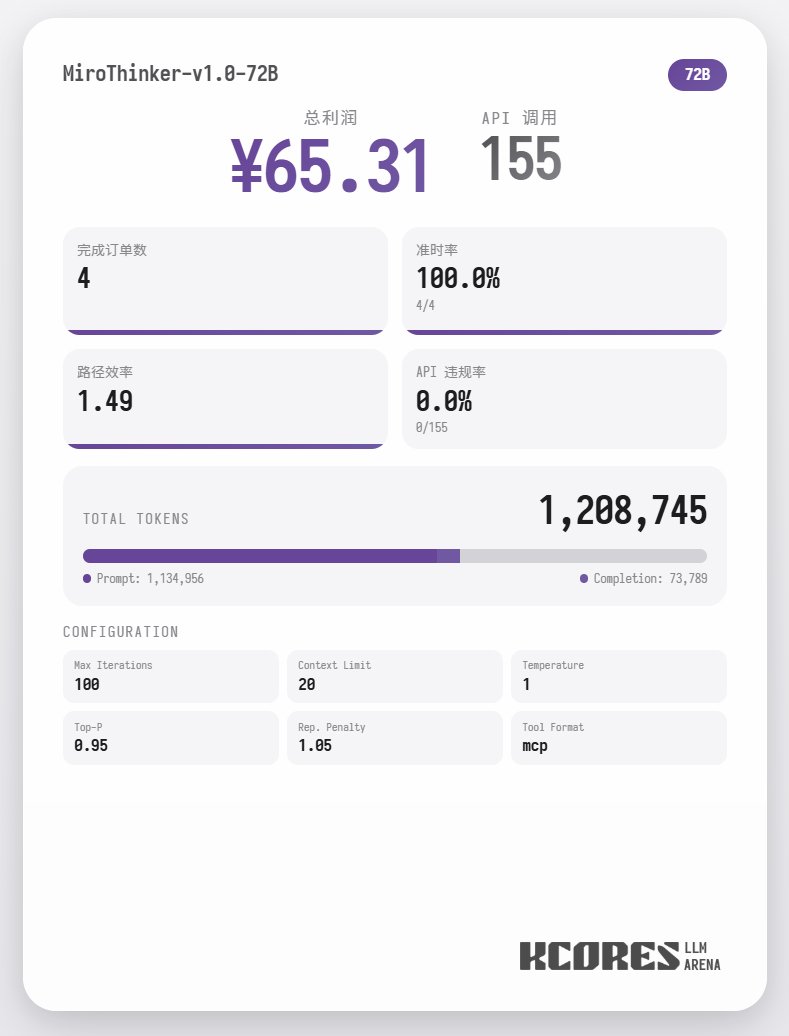
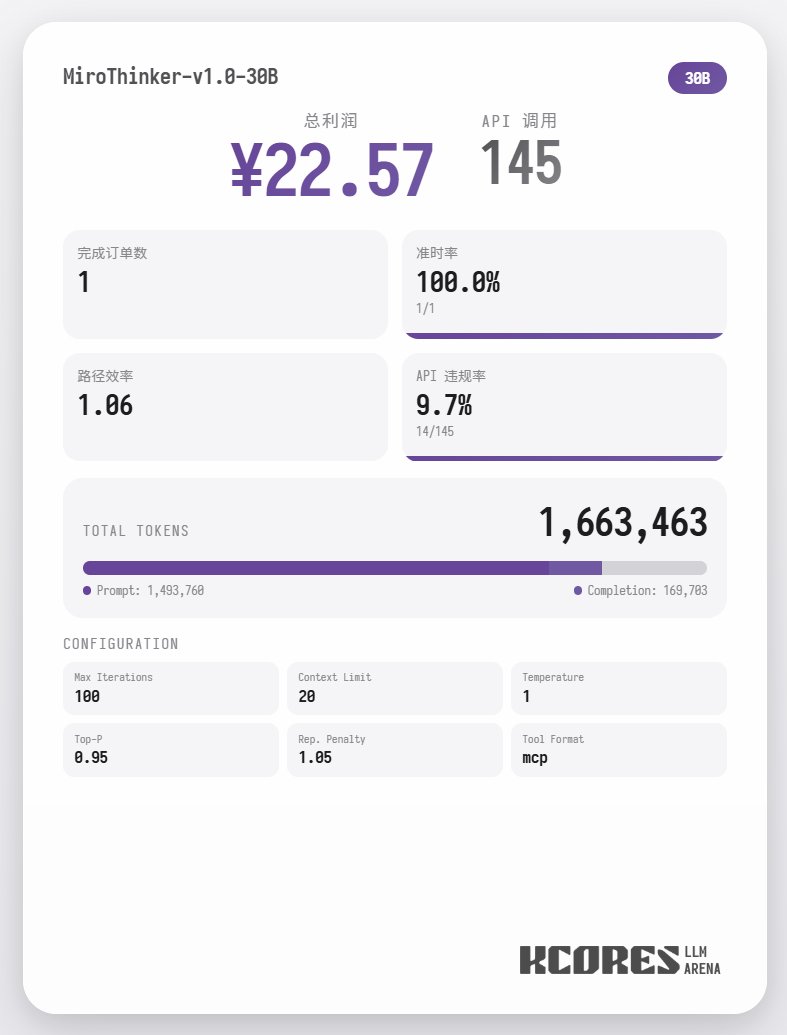
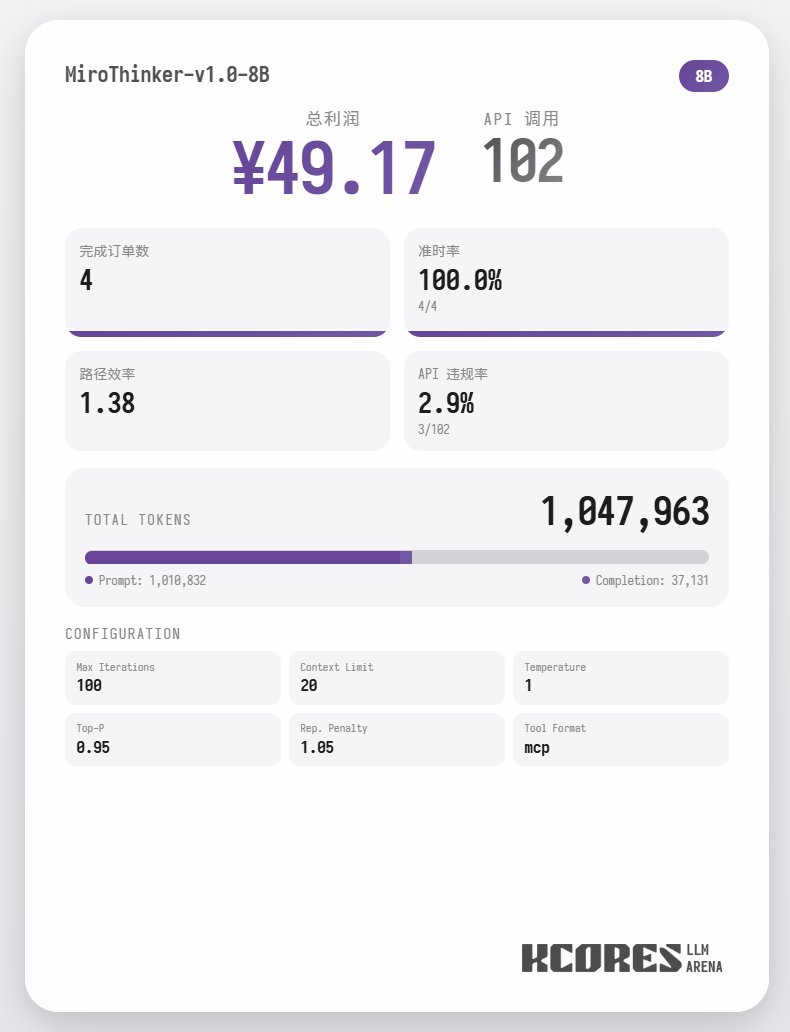
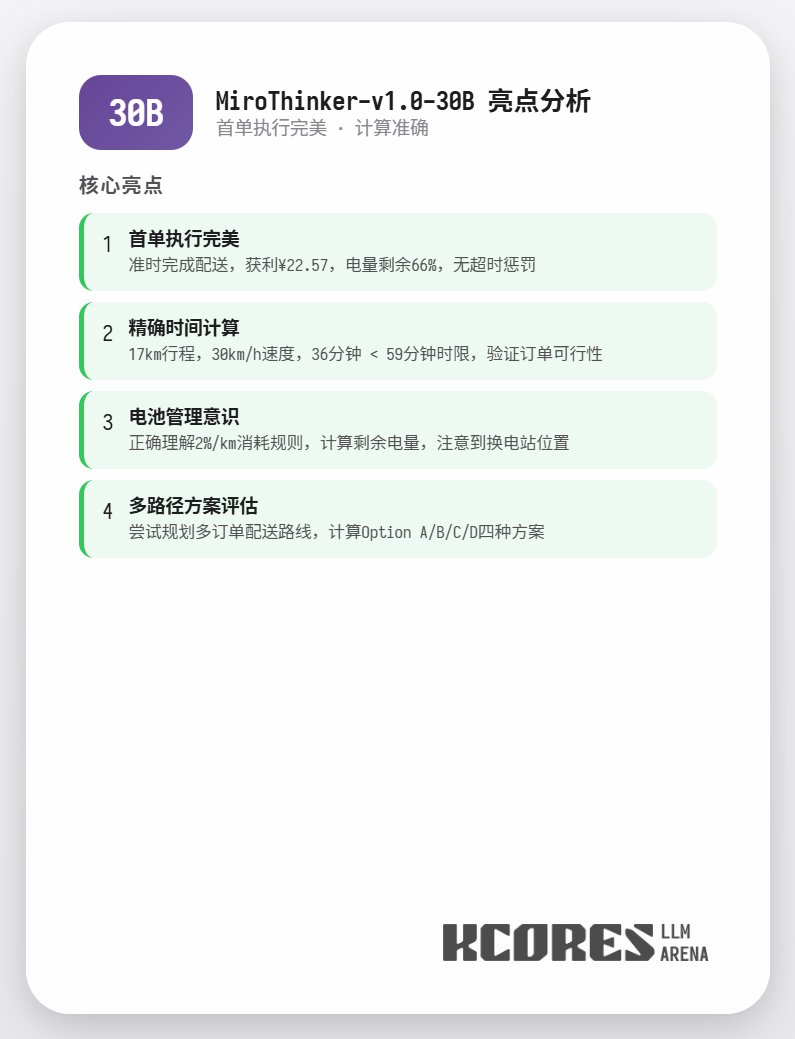
L'analyse montre que le modèle 72B a obtenu les meilleurs résultats, suivi du modèle 8B. Le modèle 72B permet de planifier systématiquement la prise de commandes et le traitement des commandes à emporter, tandis que le modèle 8B peut même évaluer quantitativement la consommation d'énergie et la rentabilité. Le modèle 30B a obtenu des résultats moyens, le principal problème étant les appels répétés à l'outil de numérisation des commandes. Ceci est probablement dû à la capacité inégale de rappel du contexte long du modèle de base.



Données détaillées



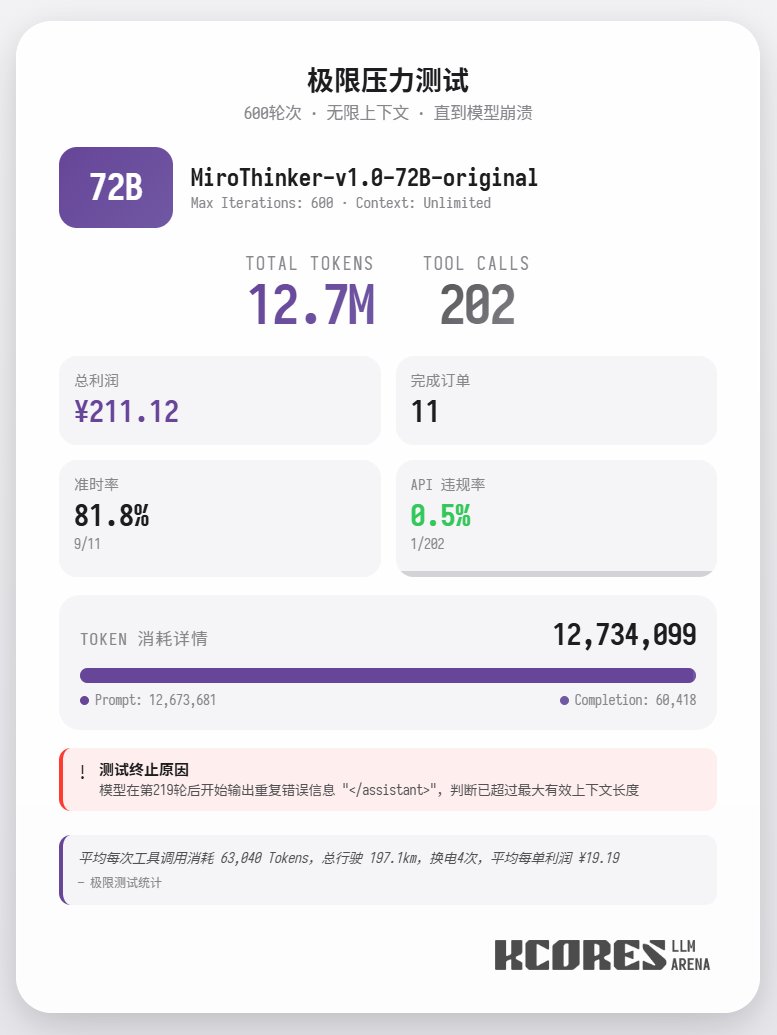
De plus, un test extrême a été mené avec le modèle 72B, sans restriction de contexte, pour la livraison de repas. Le modèle a effectué 202 appels d'outils, consommant 12,7 millions de jetons, traitant 11 commandes et générant 211,12 points. Un seul de ces 202 appels a entraîné une violation d'API (appel de méthode incorrect), démontrant ainsi que le modèle 72B conserve d'excellentes performances de rappel et une grande capacité d'appel d'outils, même dans des contextes très longs. En résumé, 72B excelle dans les tâches complexes d'agents, 8B se distingue par son efficacité en matière de ressources, et 30B nécessite des améliorations au niveau de l'exécution. Si vous devez utiliser un grand nombre d'outils, notamment dans le cadre de scénarios de recherche d'agents, la suite de modèles MiroThinker pourrait vous convenir.