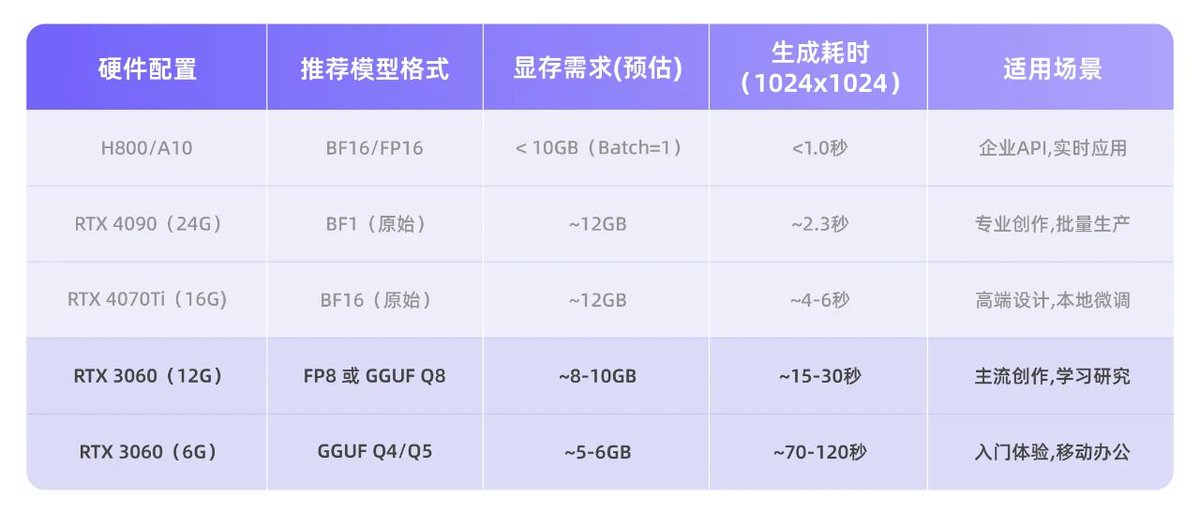
Un guide du débutant pour Z-Image, comprenant le déploiement local et des exemples pratiques de modèles de mots-clés. Un ordinateur portable doté de 6 Go de mémoire vidéo permet de créer des affiches de qualité professionnelle avec des caractères chinois. Ce guide propose une explication détaillée, depuis le téléchargement du modèle jusqu'à la résolution des erreurs courantes, en passant par la configuration de ComfyUI et la saisie des invites. 1. Sélectionnez le plan de déploiement approprié en fonction de la configuration de votre ordinateur (voir figure pour le plan de configuration). Pour les appareils équipés d'une RTX 3060 (6 Go), d'une RTX 4050 ou d'une autre carte graphique dotée de 6 à 8 Go de VRAM, le schéma de quantification GGUF est requis. Si la VRAM est supérieure ou égale à 12 Go (comme pour les RTX 3060 12 Go, 4070, 4080, etc.), le modèle BF16 d'origine peut être utilisé sans plugin supplémentaire. 2. Configurer ComfyUI Pour que Z-Image fonctionne correctement en local, trois composants essentiels doivent être correctement configurés dans ComfyUI : le modèle de diffusion, l’encodeur de texte et l’autoencodeur variationnel. 1) Installez ComfyUI et téléchargez les composants principaux. Installez la dernière version de ComfyUI et téléchargez le package portable depuis le site officiel. Téléchargez ensuite les trois fichiers principaux et placez-les dans le répertoire correspondant de ComfyUI. Fichier du modèle de diffusion : z_image_turbo_bf16.safetensors (ou version FP8/GGUF, à choisir en fonction de la mémoire du GPU) Chemin : ComfyUI/models/diffusion_models/ Fichier d'encodage de texte : qwen_3_4b.safetensors (Notez qu'il s'agit d'un modèle de langage volumineux avec 3,4 milliards de paramètres, et non d'un CLIP traditionnel) Chemin : ComfyUI/models/text_encoders/ Fichier d'auto-encodeur variationnel : ae.safetensors (généralement compatible avec le VAE de Flux, mais il est recommandé d'utiliser la version officielle) Chemin : ComfyUI/models/vae/ Placez ces trois fichiers dans les répertoires correspondants de ComfyUI, et placez le modèle de diffusion dans models/diffusion_models/. L'encodeur de texte est placé dans models/text_encoders/ Placez le fichier VAE dans models/vae/ Une fois cette opération terminée, vous pouvez sélectionner le flux de travail correspondant en fonction de la taille de la mémoire vidéo. La deuxième étape est détaillée dans l'article suivant. #ZImage #AIImage #ImageGenerationTutorial

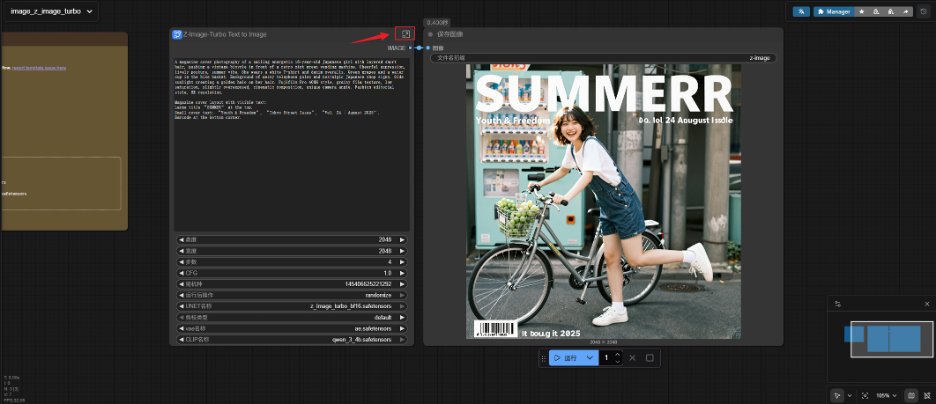
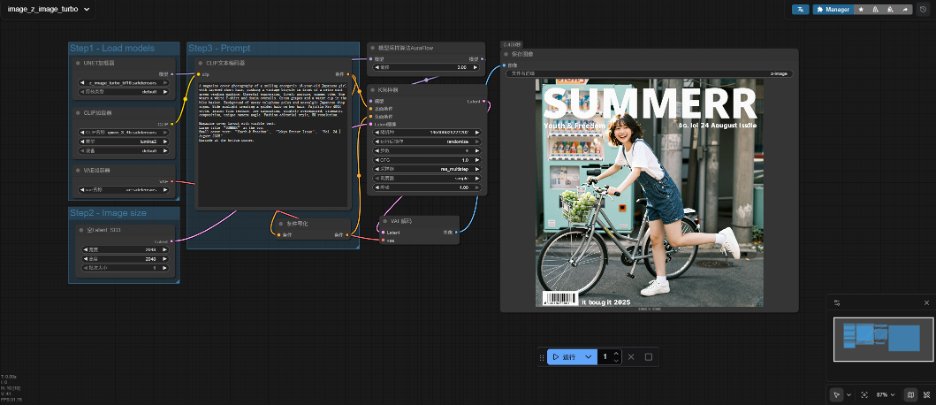
2) Solution de déploiement rapide pour 12 Go et plus de VRAM : Si la carte graphique possède ≥12 Go de VRAM (comme la RTX 3060 12G, 4070, 4080, etc.), il est recommandé d’utiliser le flux de travail standard de Z-Image pour obtenir la meilleure qualité d’image et la meilleure vitesse. Charger les nœuds du modèle Dans ComfyUI, la sélection de « Z-Image Turbo Text-to-Image » dans la bibliothèque de modèles à gauche chargera automatiquement les trois composants principaux déjà placés dans les répertoires correspondants. Chargez z_image_turbo_bf16.safetensors à l'aide du nœud Charger le modèle de diffusion. Charger les tenseurs de sécurité ae. à l'aide du nœud Charger VAE. Charger qwen_3_4b à l'aide de DualCLIPLoader ou d'un chargeur d'encodeur de texte Z-Image personnalisé. Si les fichiers ont été correctement placés, le modèle se chargera généralement automatiquement sans configuration manuelle. Paramètres de l'échantillonneur En mode sous-graphique par défaut, vous pouvez modifier les paramètres de base. Pour des paramètres plus détaillés, cliquez sur le coin supérieur droit afin d'ouvrir le sous-graphique et accéder à des options supplémentaires. Les paramètres de KSampler sont essentiels aux résultats générés et doivent être strictement définis conformément aux instructions suivantes. Étapes : Réglez la valeur sur 8 ou 9. Ne la réglez pas sur une valeur trop élevée, comme 20 ou 30, sinon la peau risque de paraître cireuse ou de présenter des imperfections. CFG : Réglé sur 1.0 Nom de l'échantillonneur : Euler recommandé Planificateur : sgm_uniform ou le planificateur par défaut simple sont recommandés. Les tests ont montré que sgm_uniform réduit efficacement le bruit pour les faibles nombres d'étapes. Décalage : Réglez-le sur 3 pour une résolution de 1024 et sur 7 pour une résolution de 2K. [Paramètres de résolution] Z-Image est optimisé pour les résolutions standard telles que 1024x1024, 1280x720 et 720x1280. Évitez de générer directement des résolutions ultra-élevées, comme la 4K. Générez plutôt une image 2K, puis agrandissez-la à l'aide d'un upscaler pour garantir la stabilité de la composition et la qualité des détails. Une fois les trois étapes précédentes terminées, vous pouvez saisir le mot d'invite et cliquer sur « Invite en file d'attente » pour générer l'image.
3) Schéma de quantification GGUF pour les flux de travail à faible mémoire (utilisateurs de 6 à 8 Go de VRAM) Si vous utilisez un appareil doté de 6 à 8 Go de mémoire vidéo, comme une RTX 3060 (6 Go) ou une RTX 4050, vous devez utiliser le schéma de quantification GGUF. Tout d'abord, vous devez installer le plugin ComfyUI-GGUF dans ComfyUI via le gestionnaire ComfyUI. Ensuite, téléchargez deux fichiers au format GGUF depuis la plateforme de modèles : le modèle de diffusion z_image_turbo_Q4_K_M.gguf et l’encodeur de texte qwen_3_4b_Q4_K_M.gguf. Cette étape est cruciale. Les tenseurs de sécurité qwen_3_4b non quantifiés occuperont à eux seuls plus de 6 Go de mémoire GPU. Même si le modèle principal a été quantifié, le chargement échouera toujours en raison d'un dépassement de capacité de la mémoire GPU. Placez ces deux fichiers respectivement dans les répertoires models/diffusion_models/ et models/text_encoders/. Dans ComfyUI, le nœud Unet Loader (GGUF) est utilisé pour charger le modèle de diffusion, le nœud CLIP Loader (GGUF) est utilisé pour charger l'encodeur de texte et un nœud VAELoader est connecté pour charger les ae.safetensors officiels. Les paramètres de l'échantillonneur sont configurés pour être conformes au flux de travail standard : Étapes=8, CFG=1.0, Planificateur=sgm_uniform L'utilisation de la mémoire vidéo peut être réduite à moins de 6 Go. Bien que le temps d'inférence soit légèrement plus long, le problème d'erreur de mémoire insuffisante (OOM) est complètement résolu.
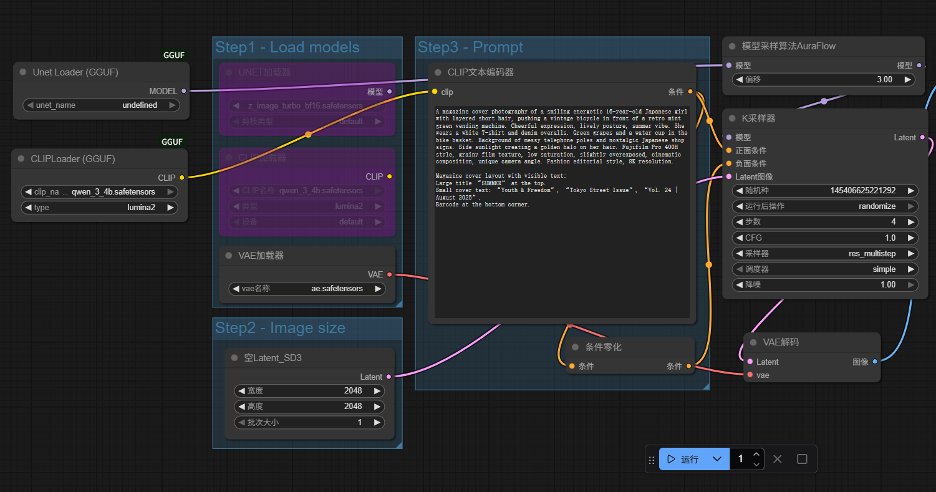
3. Améliorer le flux de travail grâce à des invites Une étape de traitement LLM optionnelle peut être ajoutée en amont du flux de travail pour exploiter pleinement le potentiel de Z-Image. Ce LLM transforme automatiquement des entrées simples (telles que « un flacon de parfum ») en instructions détaillées comprenant la scène, l'éclairage, les matériaux et les paramètres photographiques, améliorant ainsi la qualité du résultat. Vous trouverez ci-dessous trois types de scénarios à haute fréquence avec des modèles directement réutilisables qui ne nécessitent aucune configuration supplémentaire. 1) Photographie de produits e-commerce : [Générer une image d'affichage pour un flacon de parfum] Mots-clés : Photographie publicitaire hyperréaliste et cinématographique. Le sujet principal est un flacon de parfum en verre ambré translucide, coiffé d’un bouchon en métal doré brossé, élégamment posé sur une ardoise sombre à la texture brute émergeant d’une eau calme. La scène se déroule dans une forêt tropicale humide et brumeuse, au lever du soleil. Éclairage et ambiance : Une lumière volumétrique intense (effet Tyndall) filtre à travers le feuillage luxuriant des palmiers, projetant des ombres complexes et mouchetées et créant des jeux de lumière caustiques sur l’eau et les bouteilles en verre. Cette lumière chaude, dorée et éthérée contraste avec les tons froids et sombres des rochers et de l’eau. Détails et matériaux : Mise au point macro d'une précision exceptionnelle. Des gouttelettes de condensation sont visibles à la surface de la bouteille, reflétant la végétation environnante. La texture de l'ardoise est d'une finesse incroyable, parsemée de taches de mousse. De légères ondulations à la surface de l'eau créent des reflets et des réfractions réalistes. À l'arrière-plan, des particules floues et de délicates fleurs de jasmin blanc flottent à la surface de l'eau. Caractéristiques techniques : Prise de vue réalisée avec un appareil Hasselblad X2D 100C, un objectif macro de 80 mm et une ouverture de f/2.8 pour un flou d’arrière-plan harmonieux. Résolution 8K, mise au point ultra-nette sur le logo, reflets en lancer de rayons, rendu sous Unreal Engine 5, étalonnage des couleurs digne d’un magazine de luxe. 2) Culture orientale/Hanfu/Monument [Générer un portrait d'une femme portant un Hanfu] Description : Une concubine impériale de la dynastie Tang, d'une beauté incomparable, vêtue de plusieurs couches de hanfu en soie rouge (un type de hanfu à taille haute), brodé de motifs complexes de phénix et de pivoines en fils d'or. Elle se tient sur la grande terrasse du palais, avec en arrière-plan la vue nocturne animée de Chang'an et des milliers de lanternes Kongming flottant dans le ciel. Détails du maquillage et de la coiffure : Le front est orné de délicats motifs floraux, et les cheveux sont coiffés en un chignon haut, orné d’épingles à cheveux, d’épingles à cheveux dorées et de pompons de perles qui scintillent sous les lumières. Ambiance : La douce lumière jaune des lanternes se mêle à la fraîcheur bleue du clair de lune. L'atmosphère est festive. Rendu : Textures de tissus extrêmement détaillées, éclairage cinématographique, effets de profondeur de champ, résolution 8K — un régal pour les yeux digne du film « La Légende du Chat Démon ».


4. Problèmes courants Ceci conclut le processus complet de déploiement local de Z-Image. Lors de son utilisation, vous pourriez rencontrer des problèmes tels que des images complètement noires, du texte illisible ou une texture de peau cireuse. Cela provient généralement de paramètres incorrects, d'erreurs de chargement de fichiers ou d'un formatage incorrect des messages d'erreur.

GitHub github.com/Tongyi-MAI/Z-I…wA Visage câlhuggingface.co/Tongyi-MAI/Z-I…ip2bC Modelmodelscope.cn/models/Tongyi-…iPCTqgnS