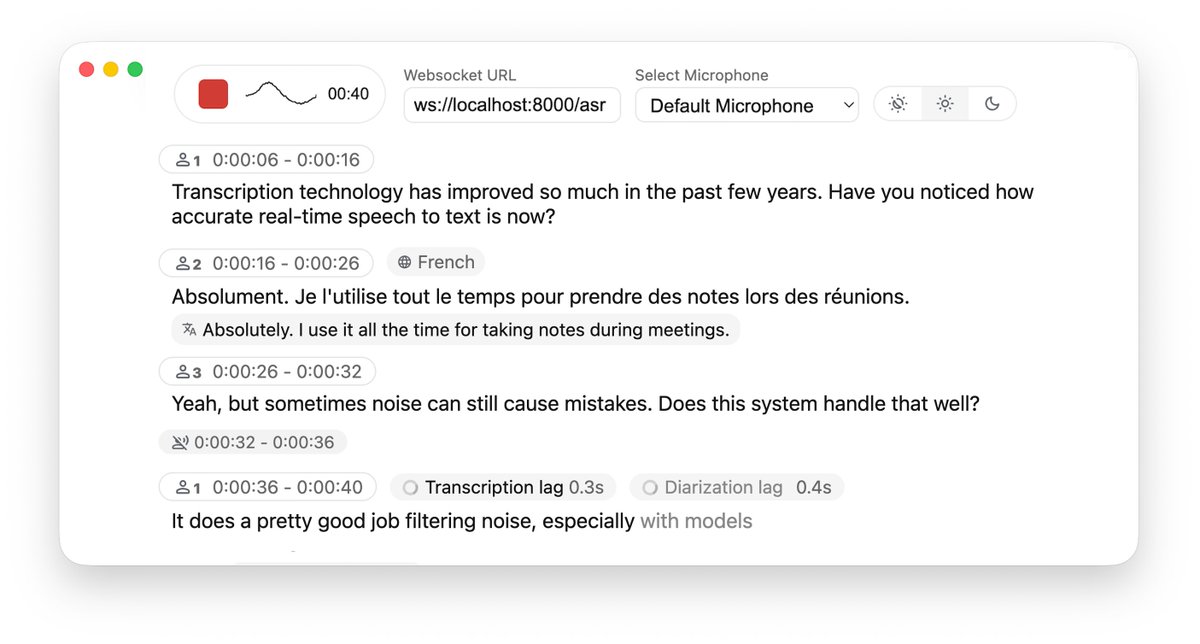
Pour réaliser une conversion parole-texte en temps réel dans un projet, il faut généralement choisir une API cloud, ce qui est non seulement coûteux, mais soulève également des préoccupations en matière de confidentialité des données. Bien que le déploiement local de Whisper soit gratuit, la latence et la segmentation des phrases lors du traitement de l'audio en flux continu sont souvent insatisfaisantes. Je suis tombé par hasard sur le projet open-source WhisperLiveKit sur GitHub, qui fournit une solution complète de reconnaissance et de traduction vocales en temps réel en local, spécifiquement optimisée pour les problèmes de latence de diffusion. Il prend non seulement en charge la transcription en temps réel de haute précision, mais dispose également d'une reconnaissance vocale intégrée (diarisation) et d'une détection d'activité vocale (VAD), qui peuvent distinguer avec précision qui parle et quand il fait une pause. GitHub : https://t.co/SVCcyqdqhG Le système dorsal est extrêmement flexible, prenant en charge l'intégration avec Faster Whisper ou le moteur mlx-whisper optimisé pour Apple Silicon, et même l'intégration du modèle NLLW pour réaliser la traduction en temps réel de 200 langues. Ce projet inclut des exemples prêts à l'emploi côté serveur Python et côté client web, compatibles avec le déploiement Docker. Il fournit une infrastructure très robuste pour la création d'un système d'enregistrement de réunions ou d'interprétation simultanée respectueux de la vie privée et à faible latence.