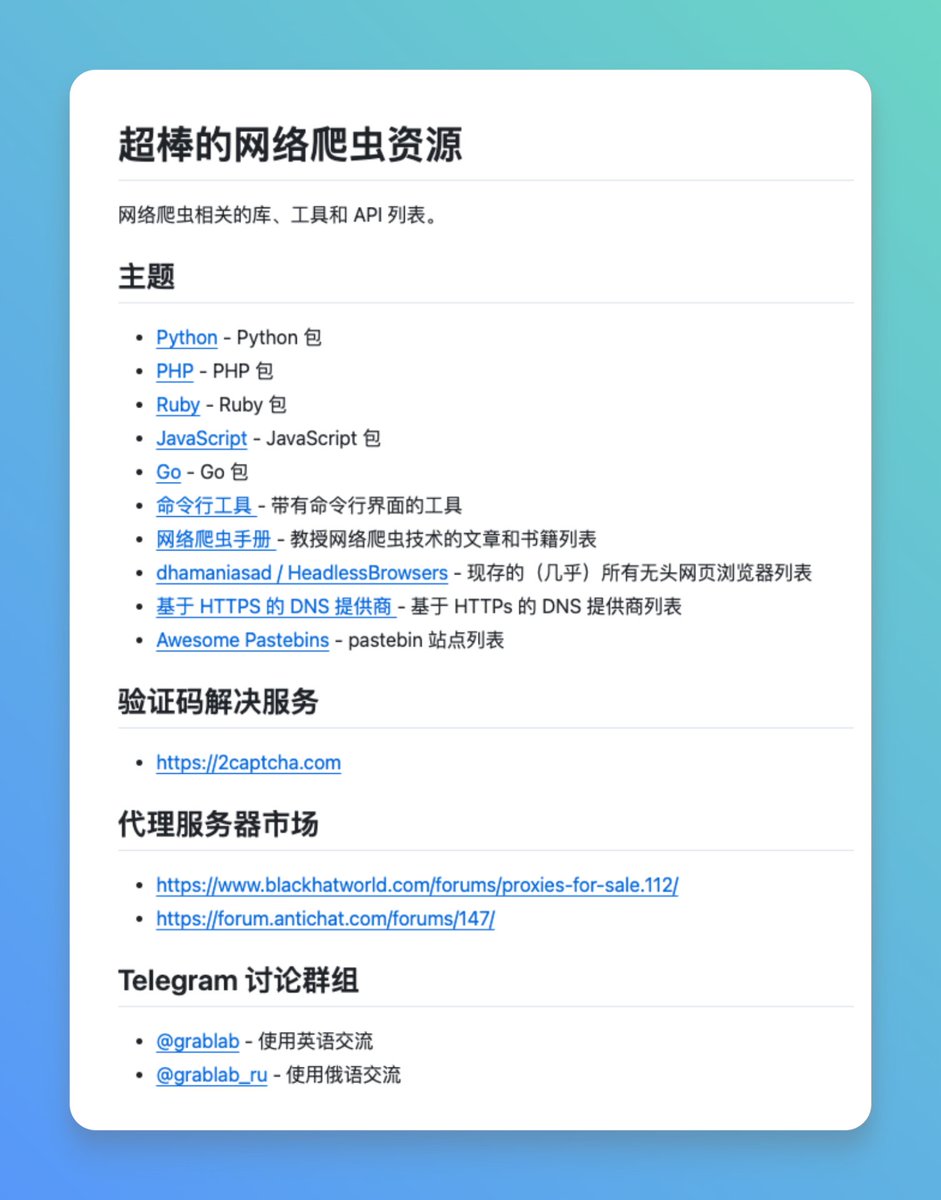
Lors du développement de robots d'exploration Web, le plus gros casse-tête n'est souvent pas l'écriture du code, mais la recherche de bibliothèques ou d'outils adaptés aux différents langages et scénarios, car les ressources sont très dispersées. Je suis tombé par hasard sur Awesome Web Scraping, une collection de ressources open source qui organise systématiquement divers outils de web scraping et de traitement de données. Il est organisé par langages de programmation, couvrant les bibliothèques de web scraping pour les langages courants tels que Python, PHP, Ruby, JavaScript et Go, ainsi que les outils en ligne de commande et les ressources pédagogiques. GitHub : https://t.co/MP1R3oMRNH En plus de la bibliothèque d'outils elle-même, elle comprend également des ressources pratiques telles que des tutoriels sur le web scraping et une liste de navigateurs sans interface graphique. Ce projet s'appuie sur des données issues de plusieurs listes exceptionnelles bien connues, et les ressources sont relativement complètes, ce qui justifie de le conserver pour consultation ultérieure.