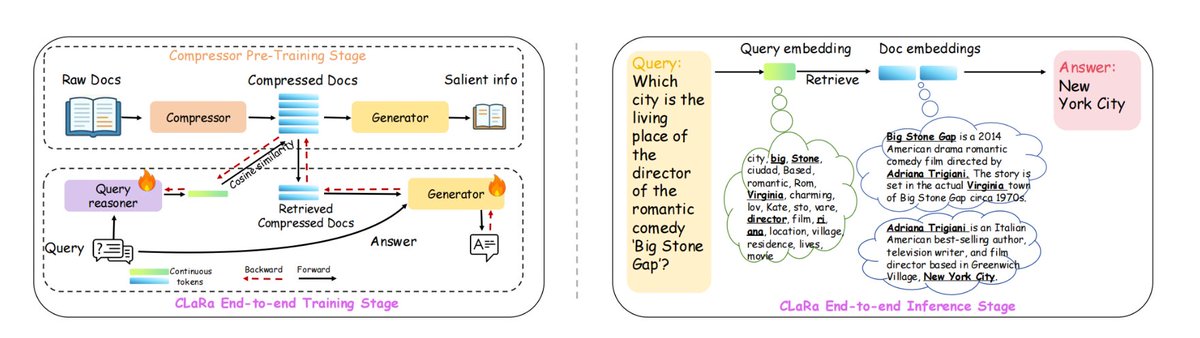
Apple a développé un nouveau framework RAG appelé ml-clara, qui remédie aux inefficacités liées à la gestion des contextes longs et à la séparation des processus d'optimisation de la récupération et de la génération. L'idée principale est d'éviter d'intégrer l'intégralité du texte dans un modèle volumineux, mais plutôt de compresser les processus de « récupération » et de « génération » dans un même espace vectoriel continu différentiable, permettant ainsi un entraînement unifié et une inférence en une seule étape. Cela permet de résoudre les problèmes suivants : 1) l'augmentation de la longueur du contexte entraînant une explosion du coût de calcul ; 2) l'incohérence des objectifs d'optimisation causée par l'entraînement indépendant de la récupération et des générateurs ; et 3) le problème de la déconnexion du gradient. Sur NQ, HotpotQA, MuSiQue et 2Wiki, il a maintenu sa position de leader à différents taux de compression de 4×/16×/32×, et même à une compression de 32×, il était toujours supérieur à la référence de recherche pure non compressée. La longueur du contexte peut être compressée jusqu'à 32×–64× tout en conservant les informations essentielles nécessaires pour générer une réponse précise. Plus précisément, 1. Premièrement, compresser le pré-entraînement, en compressant les documents en vecteurs de 32 à 256 dimensions tout en préservant la sémantique QA/répétition. 2. Ensuite, affinez les instructions pour adapter le vecteur compressé à la tâche de question-réponse en aval. 3. Formation conjointe de bout en bout plus poussée, optimisant à la fois la récupération et les générateurs. #RAG #mlclara
github:github.com/apple/ml-clara