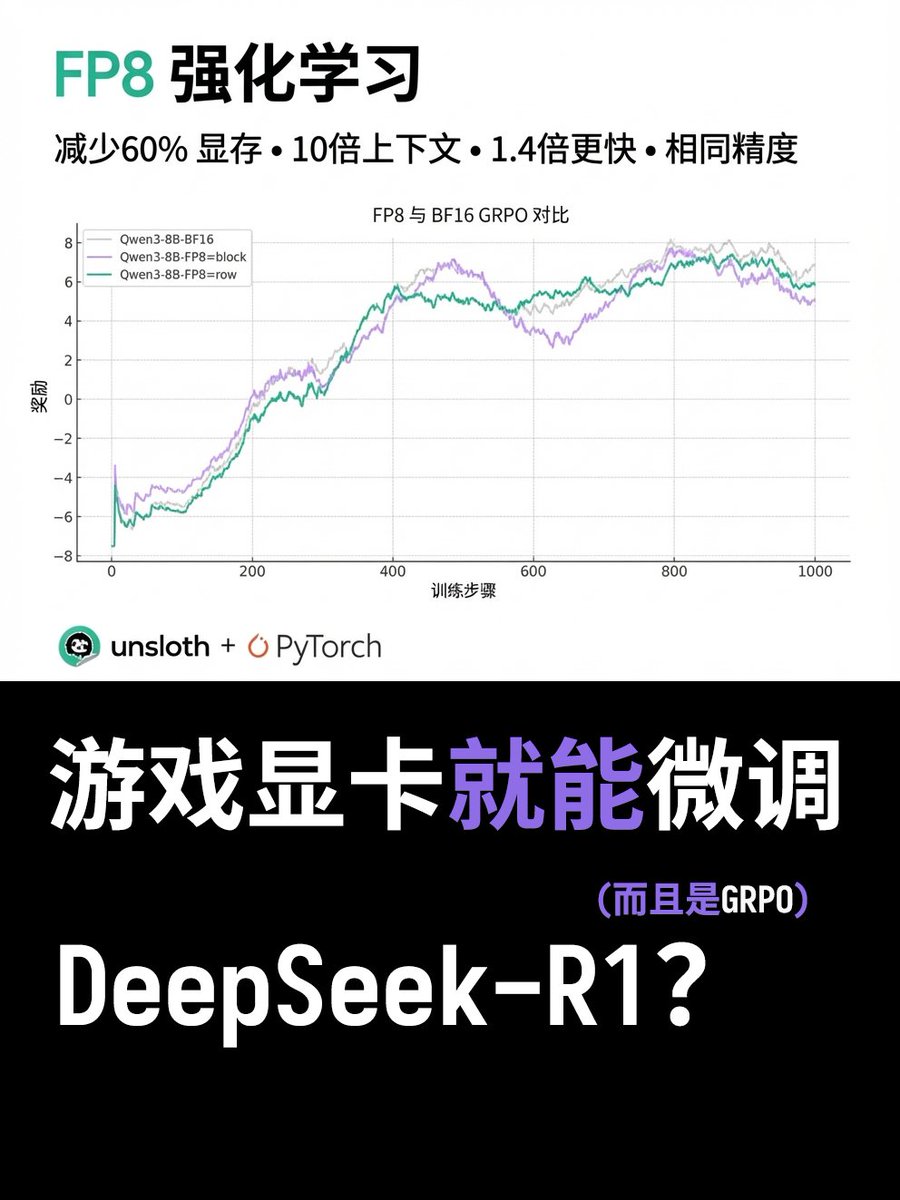
Les cartes de jeu peuvent-elles désormais également utiliser le GRPO FP8 ? Unsloth vient de publier un nouveau tutoriel montrant comment optimiser le GRPO FP8 du DeepSeek-R1 avec un minimum de VRAM ! Ils ont collaboré avec PyTorch pour améliorer la vitesse d'inférence FP8 RL d'un facteur 1,4. Ils ont ensuite optimisé le processus en réduisant la mémoire GPU de 60 % et en augmentant la longueur du contexte d'un facteur 12. Cette fonctionnalité est désormais disponible dans le framework Unsloth. Cette approche d'apprentissage par renforcement, qui favorise l'adoption généralisée de la précision FP8, permet désormais d'implémenter FP8 GRPO sur des GPU grand public (tels que les RTX 40 et 50). Les données de test montrent que FP8 GRPO sur Qwen3-1.7B ne nécessite plus que 5 Go de VRAM pour fonctionner. Adresse du tutoriel :