Imaginez une équipe de développement logiciel travaillant sur un projet d'envergure, mais avec une règle étrange : chaque ingénieur ne peut travailler que quelques dizaines de minutes, quelques heures au maximum, avant d'être remplacé. Cette équipe convient donc aux tâches simples, mais pour des projets plus complexes nécessitant de longues sessions, comme le clonage d'un fichier claude.ai, elle est tout simplement incapable de les mener à bien. Voici en résumé l'état actuel des agents de codage : ils manquent de mémoire et leur fenêtre de contexte est limitée. Par conséquent, ils ne sont pas adaptés aux tâches de longue durée. L'article de blog d'Anthropic, intitulé « Effective harnesses for long-runing agents », explique précisément comment permettre aux agents de continuer à effectuer des tâches à travers plusieurs fenêtres de contexte. Tout d'abord, examinons les principaux problèmes rencontrés par l'agent lors des tâches longues. Il existe trois types principaux : Le premier type d'erreur consiste à vouloir en faire trop à la fois. Par exemple, si vous demandez à un agent de cloner un site web comme claude.ai, il tentera de réaliser l'application entière d'un seul coup. De ce fait, le contexte n'est pas pleinement exploité, la moitié des fonctionnalités est implémentée et le code est un véritable fouillis. Lors de la session suivante, l'agent se retrouve face à un produit inachevé, et perd un temps précieux à essayer de deviner ce qui a été fait lors des étapes précédentes. Le second type consiste à déclarer victoire prématurément. Une partie du projet est achevée, puis un autre agent vérifie l'environnement, pense que le travail est presque terminé et s'arrête là. De nombreuses fonctionnalités manquantes sont alors ignorées. Le troisième type est appelé test superficiel. L'agent modifie le code, exécute quelques tests unitaires ou interroge l'interface et considère que tout est en ordre, sans effectuer le processus de bout en bout comme un véritable utilisateur. Le point commun entre ces trois modes de défaillance est que l'agent ignore l'objectif global, et ne sait ni où s'arrêter ni ce qu'il faut laisser à l'agent suivant. Quelle est donc la solution proposée par Anthropic ? Voici quelques solutions facilement disponibles en génie logiciel : introduire un mécanisme de collaboration similaire à celui d’une équipe humaine, décomposer les tâches complexes en tâches plus petites, traçables et vérifiables, établir des mécanismes de transfert clairs et vérifier rigoureusement les résultats des tâches. Un agent d'initialisation n'apparaît qu'une seule fois, au démarrage du projet. Sa tâche consiste à configurer l'environnement d'exécution. Il joue un rôle similaire à celui d'un architecte : il rédige un script init.sh pour faciliter le démarrage ultérieur du serveur de développement, crée un fichier claude-progress.txt pour suivre la progression, effectue le premier commit Git et, surtout, génère la liste des fonctionnalités. Ce descriptif des fonctionnalités est-il détaillé ? Dans le cas du clonage de claude.ai, plus de 200 fonctions spécifiques sont listées, permettant notamment aux utilisateurs d'ouvrir de nouvelles conversations, de poser des questions, d'appuyer sur Entrée et de consulter les réponses de l'IA. Chaque état initial est marqué comme « échec », et l'agent doit le vérifier individuellement avant qu'il ne puisse être considéré comme « succès ». De plus, un détail important : cette liste n’est pas écrite en Markdown, mais sous forme de tableau JSON. En effet, des expériences menées par Anthropic ont démontré que, contrairement au Markdown, les modèles sont moins susceptibles d’être modifiés ou écrasés arbitrairement lors du traitement de JSON. L'autre est l'agent de codage. Une fois le projet initialisé, il prend en charge l'exécution des tâches. Ses principales règles de fonctionnement sont les suivantes : exécuter une fonction à la fois et laisser un environnement propre après son exécution. Qu’est-ce qu’un environnement propre ? Imaginez vos critères pour l’intégration de code à la branche principale : aucun bug grave, un code propre et bien documenté, afin que la personne suivante puisse commencer à travailler immédiatement sur de nouvelles fonctionnalités sans avoir à nettoyer votre code au préalable. Avant chaque opération, il effectue quelques opérations : – Exécutez `pwd` pour voir dans quel répertoire vous vous trouvez. – Consultez les journaux Git et les fichiers de progression pour comprendre ce qui a été fait lors de l'exécution précédente. – Examinez la liste des fonctionnalités et choisissez la fonctionnalité non terminée la plus prioritaire. – Effectuez un test de base pour vous assurer que l'application reste utilisable. Concentrez-vous ensuite sur une seule fonctionnalité, et une fois qu'elle sera terminée : - Message de commit Git clair – Mettre à jour claude-progress.txt – Modifiez uniquement les champs d'état dans la liste des fonctionnalités, ne supprimez ni ne modifiez jamais les exigences elles-mêmes. L'ingéniosité de cette conception réside dans l'externalisation de la « mémoire » dans des fichiers et l'historique Git. Chaque cycle de l'agent ne dépend pas d'informations fragmentées dans la fenêtre de contexte ; il imite plutôt les tâches quotidiennes d'un ingénieur humain compétent : synchroniser l'avancement, vérifier le bon fonctionnement de l'environnement, puis commencer le travail. Les améliorations apportées au processus de test méritent une discussion séparée. L'agent se limitait à la vérification au niveau du code, par exemple en exécutant des tests unitaires ou en appelant des API. Le problème est que de nombreux bogues n'apparaissent que lorsque l'utilisateur interagit avec la page. La solution consiste à doter l'Agent d'un outil d'automatisation de navigateur, tel que Puppeteer MCP. L'Agent peut désormais ouvrir un navigateur, cliquer sur des boutons, remplir des formulaires et visualiser le rendu des pages comme un utilisateur humain. Anthropic a publié un GIF animé montrant une capture d'écran réalisée par l'Agent lors du test d'un clone de claude.ai, démontrant ainsi son bon fonctionnement. Cette technique améliore considérablement la précision de la vérification fonctionnelle. Bien entendu, elle présente des limitations. Par exemple, Puppeteer ne peut pas capturer les alertes contextuelles natives du navigateur, et les fonctionnalités qui dépendent de ces alertes sont sujettes à des bogues. Ce plan laisse encore quelques questions en suspens. Par exemple, vaut-il mieux avoir un agent généraliste qui gère tout, ou des rôles spécialisés ? Il serait peut-être plus efficace d’avoir un agent de test dédié aux tests et un agent de nettoyage de code dédié au nettoyage. Par exemple, cet ensemble d'expériences est optimisé pour le développement web full-stack. Peut-il être transposé à des tâches de longue durée telles que la recherche scientifique ou la modélisation financière ? Cela devrait être possible, mais il convient de le vérifier par des expérimentations. Xiangma@xicilion a dit : Au-delà de l'IA, il y a toujours le génie logiciel. Les agents d'IA ne sont pas magiques. Ils doivent aussi tirer des enseignements de l'expérience humaine en ingénierie logicielle, décomposer les tâches complexes en tâches simples et disposer d'un environnement de travail structuré et d'un mécanisme de transition clair. Pourquoi les ingénieurs humains peuvent-ils collaborer malgré le décalage horaire et le nombre d'équipes ? Parce qu'ils utilisent Git, la documentation, la revue de code et les tests. Pour que les agents d'IA puissent fonctionner de manière autonome pendant de longues périodes, ils doivent également avoir accès à ces outils. L'approche d'Anthropic consiste simplement à transformer les meilleures pratiques d'ingénierie logicielle en mots-clés et en chaînes d'outils compréhensibles par l'agent. Elle ne rend pas le modèle plus intelligent, mais lui fournit plutôt une structure plus adaptée. L'approche d'Anthropic est instructive. Que vous utilisiez Claude, GPT ou un autre modèle, lors de la conception de tâches longues et itératives, il est essentiel de bien comprendre comment faire passer l'agent à l'itération suivante rapidement et comment éviter qu'il ne réinvente la roue ou ne génère un code complexe. Même pour les tâches à itération unique, il faut tenir compte du fait qu'elles ne disposent pas de mémoire ; il est donc nécessaire d'utiliser des fichiers externes pour leur permettre de « se souvenir » des opérations précédentes. Avec les fonctionnalités actuelles du modèle, Coding Agent est déjà capable de réaliser beaucoup de choses. L'essentiel est de savoir si l'on peut décomposer les tâches et concevoir des flux de travail à l'instar du génie logiciel. Texte original : Des harnais efficaces pour les agents à longue durée de vie https://t.co/tERUGrV9wC traduire:
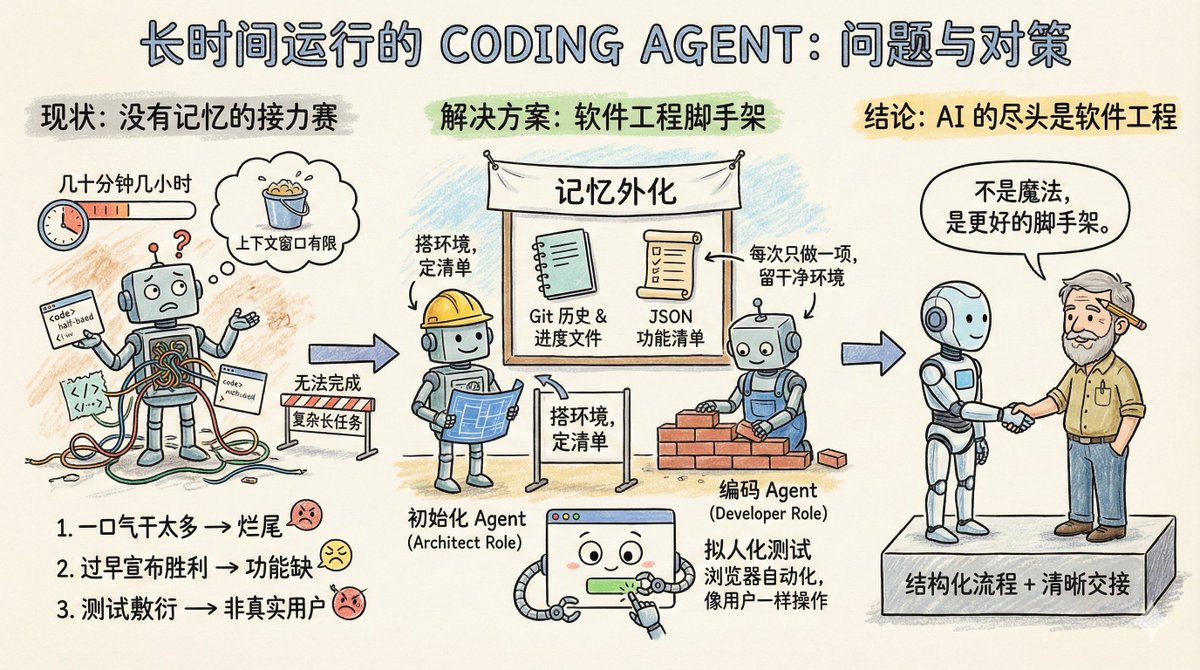
La liste des tâches mentionnée dans l'article est un type de x.com/stevenlu1729/s…omme tous les contextes globaux, elle ne peut pas être trop longue, sinon la fenêtre de contexte pour l'exécution des tâches serait insuffisante.