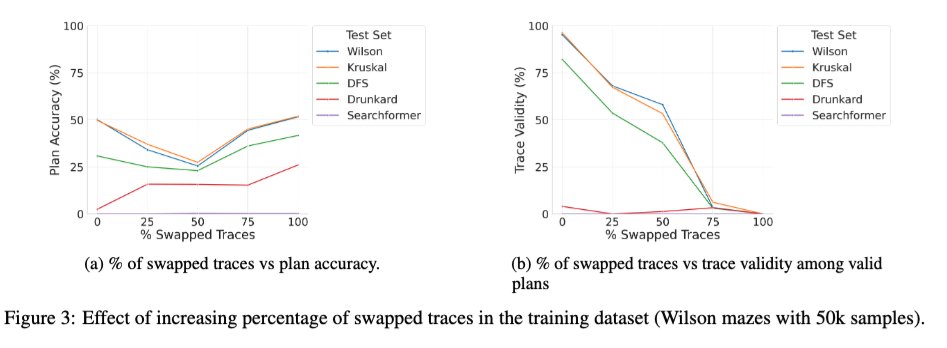
Nous venons de publier sur arXiv une version enrichie de l'article « Beyond Semantics » (notre étude systématique du rôle des jetons intermédiaires dans les LRM), qui pourrait intéresser certains d'entre vous. 🧵 1/ Une nouvelle étude intéressante porte sur l'effet de l'entraînement du transformateur de base avec un mélange de traces correctes et incorrectes. On observe que lorsque le pourcentage de traces incorrectes (interverties) pendant l'entraînement passe de 0 à 100 %, la validité des traces des modèles lors de l'inférence diminue de façon monotone (graphique de droite ci-dessous), comme prévu. Cependant, la précision de la solution présente une courbe en U (graphique de gauche) ! Cela suggère que ce qui importe, c'est la « cohérence » des traces utilisées pendant l'entraînement plutôt que leur exactitude.
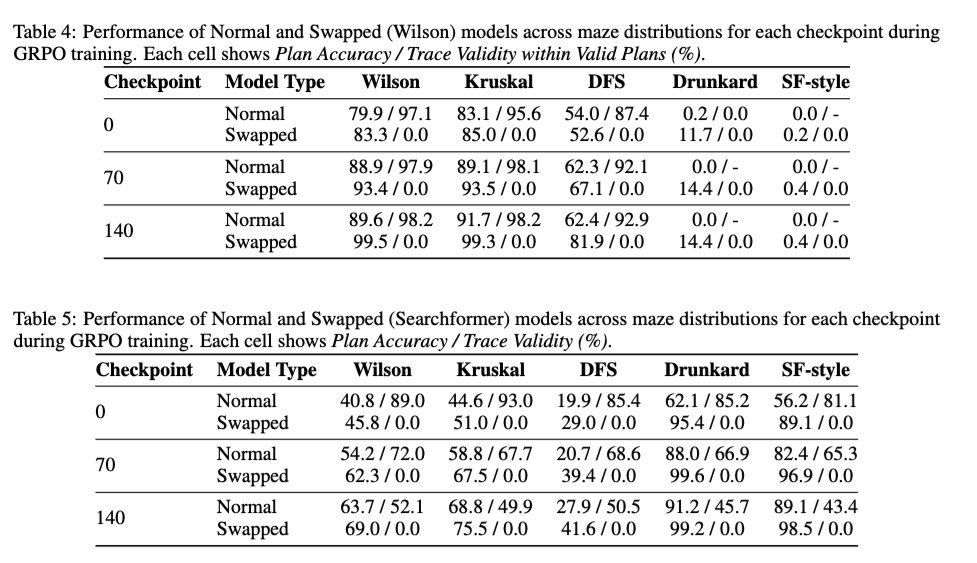
2/ Nous examinons également l'effet de l'apprentissage par renforcement (RL) de type DeepSeek R1 sur la validité des traces, afin de déterminer si le RL améliore la validité des traces du modèle de base. Les résultats montrent que le RL est globalement neutre sur la validité des traces. Il améliore la précision de la solution, même dans le cas d'un modèle entraîné sur des traces permutées à 100 %, sans pour autant augmenter la validité des traces.
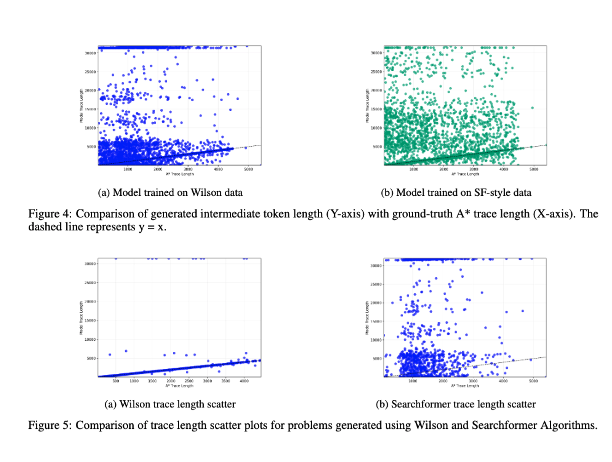
3/ Enfin, nous avons étudié la corrélation entre la longueur des jetons intermédiaires et la complexité algorithmique de l'instance du problème. Les résultats montrent qu'il n'existe aucune corrélation entre elles ! (J'ai présenté une version antérieure de cette expérience ici : https://t.co/RL9ZEOKbpQ)
4/ La nouvelle version est disponibarxiv.org/abs/2505.13775t.co/4LGWfiCZ5e. Ces résultats seront également présentés par les auteurs principaux @karthikv792, @kayastechly et @PalodVardh12428 lors des ateliers #NeurIPS2025 sur le droit, les modèles de langage pour les réseaux de neurones (ForLM) et le raisonnement efficace la semaine prochaine. N'hésitez pas à venir en discuter !