Cet article de l'Université de Stanford vaut la peine d'être lu 👇🏻 Ils ont construit un cadre d'agent d'IA, en partant de zéro donnée, sans annotations humaines, sans tâches soigneusement conçues ni démonstrations, et pourtant il a surpassé toutes les méthodes d'auto-apprentissage existantes. Ce cadre est appelé Agent0 : il libère les agents intelligents auto-évolutifs de l’absence de données en intégrant l’inférence via des outils. Ses réalisations sont incroyables. Tous les agents « à amélioration automatique » que vous avez vus jusqu'à présent ont un défaut fatal : ils ne peuvent générer que des tâches légèrement plus difficiles que celles qu'ils connaissent déjà, ce qui les conduit immédiatement à un goulot d'étranglement. Agent0 a brisé ce plafond de verre. Le point essentiel est : Ils génèrent deux agents à partir du même LLM sous-jacent et les laissent s'affronter. • Agent de parcours : Génère des tâches de difficulté croissante. • Agent d’exécution : Tente de résoudre ces tâches en utilisant le raisonnement et des outils. Chaque fois que l'agent d'exécution s'améliore, l'agent de cours est contraint d'augmenter la difficulté. Lorsque la tâche se complexifie, l'agent exécutant est contraint d'évoluer. Cela a créé un système de formation en boucle fermée et auto-renforçante, et tout a commencé à partir de zéro, sans données, sans personnes et sans rien. Il s'agit simplement du fait que les deux agents intelligents se poussent mutuellement à atteindre un niveau d'intelligence supérieur. Puis ils ont ajouté des codes de triche : Un interpréteur d'outils Python complet est en boucle. L'agent d'exécution apprend à raisonner sur les problèmes grâce au code. L'agent de cours apprend à créer des tâches qui nécessitent l'utilisation d'outils. Par conséquent, les deux agents intelligents sont constamment mis à jour. Et quel a été le résultat ? → Amélioration de 18 % des capacités de raisonnement mathématique → Les capacités de raisonnement général ont augmenté de 24 % → Surpasse R-Zero, SPIRAL, Absolute Zero et même les frameworks utilisant des API propriétaires externes → Tous ces éléments proviennent de données nulles, simplement un cycle d'auto-évolution. Ils ont même démontré que la courbe de difficulté augmente au cours du processus d'itération : la tâche commence par la géométrie de base et finit par atteindre des problèmes impliquant la satisfaction de contraintes, la combinatoire, les énigmes logiques et des problèmes à plusieurs étapes dépendant de l'outil. C’est ce qui se rapproche le plus d’une croissance cognitive autonome dans le cadre du LLM. Agent0 est bien plus qu'un simple "meilleur RL". Il s'agit d'un plan directeur permettant aux agents intelligents de guider leur propre intelligence. L'ère des agents intelligents est arrivée.

Avant de commencer votre lecture, n'oubliexaicreator.comger ou d'enregistrer cet article. Ce contenu sur Threads a été publié par un moteur de contenu collaboratif homme-machine. https://t.co/Gxsobg3hEN
Idée centrale : Agent0 crée deux agents à partir du même modèle linéaire sous-jacent et les force à s’affronter dans une boucle de rétroaction compétitive. L’un invente une tâche, l’autre tente de survivre. Cette interaction constante crée un problème de difficulté inédit, sans équivalent dans aucun ensemble de données statique.
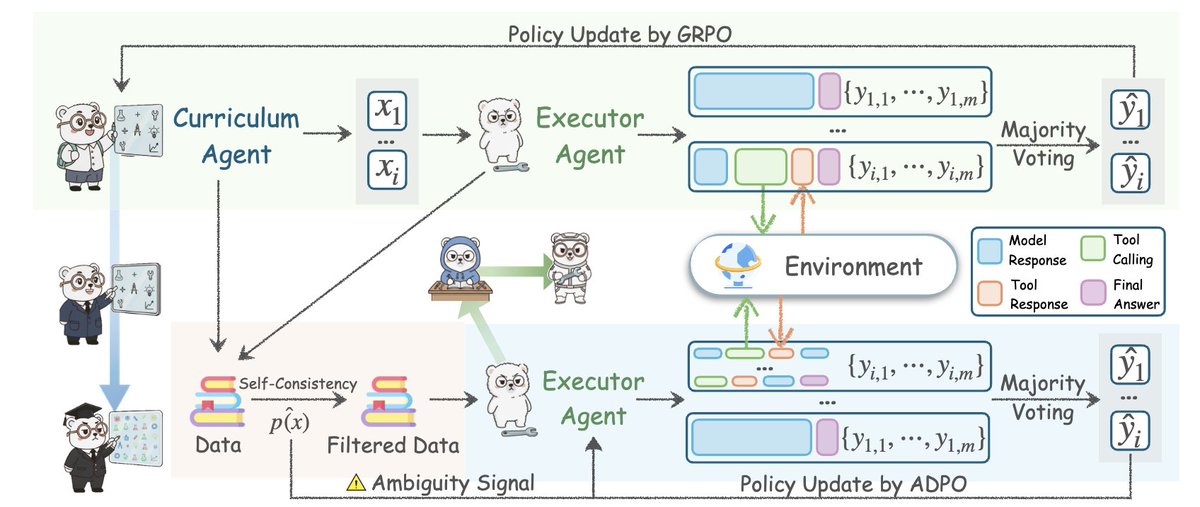
La véritable innovation ne réside pas dans l'auto-apprentissage, mais dans le raisonnement intégré aux outils. L'agent exécutif peut exécuter du code Python directement dans la solution, obtenir le résultat et mettre à jour son raisonnement. L'agent pédagogique peut ainsi répondre en posant des questions nécessitant l'utilisation d'outils. Un cercle vertueux.

Ils se sont attaqués au principal mode de défaillance des agents auto-évolutifs : la stagnation. Larxiv.org/abs/2511.16043 génèrent que des problèmes légèrement plus difficiles que leur niveau actuel. Agent0 utilise l’incertitude, la divergence entre les réponses échantillonnées et la fréquence d’appel des outils pour détecter les faiblesses de l’agent en cours d’exécution. Lire l’article complet ici : https://t.co/7UheEMgrBw

Selon moi, ce système utilise essentiellement un modèle linéaire de processus (LLM) pour construire deux agents en compétition, ce qui correspond à la logique de pensée des réseaux antagonistes génératifs (GAN). Autrement dit, le développement résulte de la résolution constante du conflit entre le Yin et le Yang. Cependant, pour que ce système fonctionne, il est indispensable de doter les agents de la capacité de « rechercher et créer des outils ». Grâce à cette capacité, les agents peuvent interagir continuellement avec le monde par le biais de l'apprentissage par renforcement (RL) et, à terme, trouver des solutions aux problèmes. Ce processus est similaire à la pratique humaine.
Enfin, merci d'avoir pris le temps de lire ce tweet ! Suivez @Yangyixxxx pour des informations sur l'IA, des analyses commerciales et des stratégies de croissance. Si ce contenu vous a plu, merci d'aimer et de partager le premier tweet afin de diffuser cette information précieuse à un plus grand nombre de personnes.