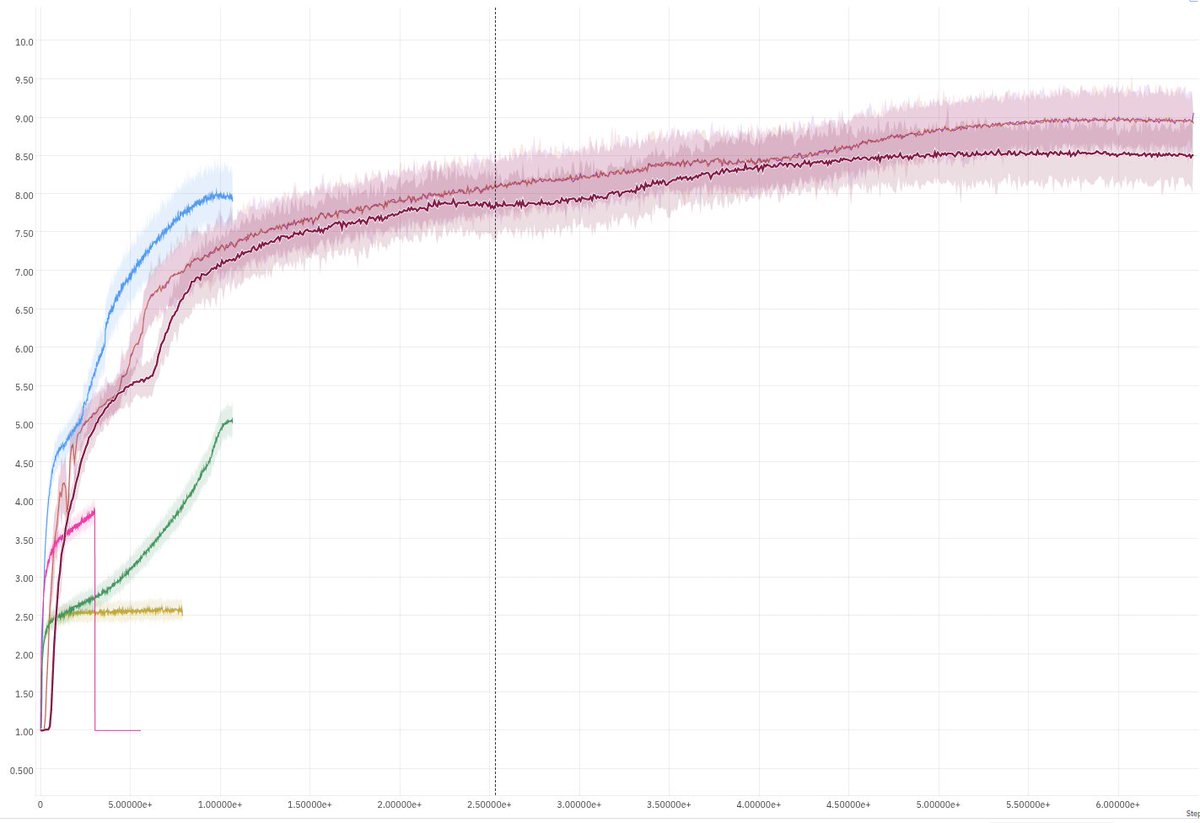
Nous avons obtenu des performances de pointe incontestables sur Neural MMO 3, notre tâche d'apprentissage par renforcement la plus difficile, avec 650 milliards d'étapes d'entraînement (plus d'un pétaoctet d'observations par exécution). Les performances ont été appariées en termes de performances et de paramètres. Le problème ? Pour que ce réseau soit utile, je dois rivaliser avec le LSTM de cuDNN en termes de performances. Or, ce réseau nécessite plusieurs noyaux.