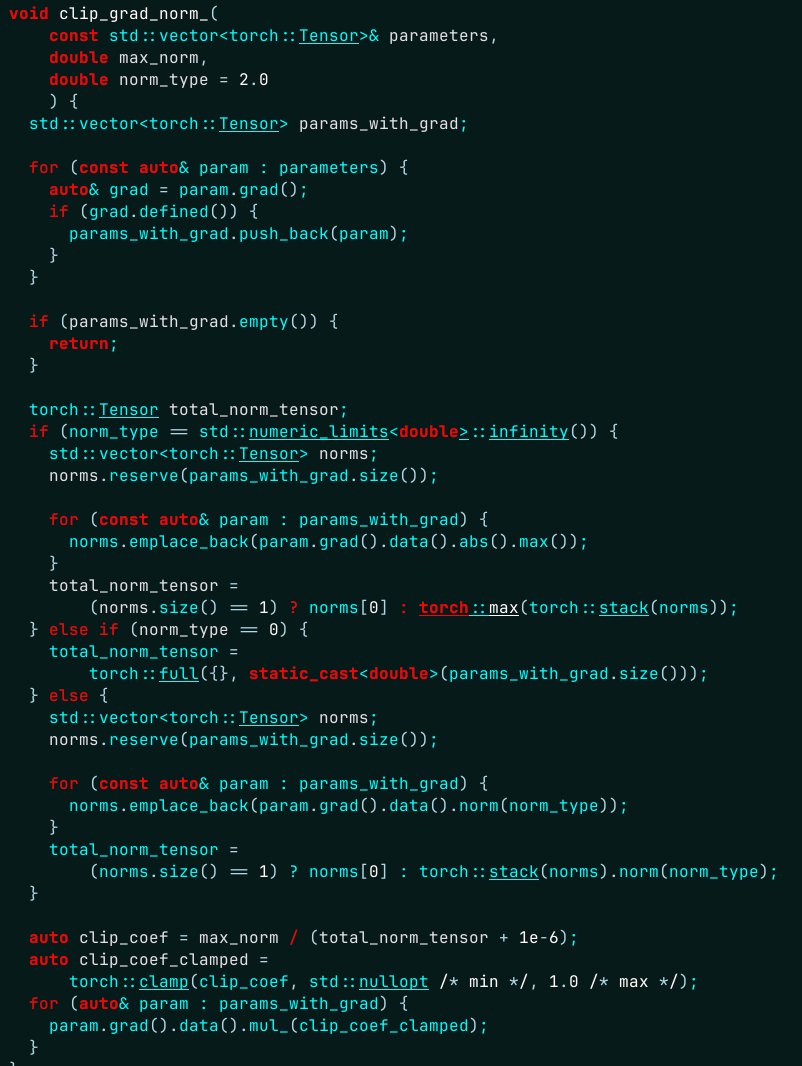
J'ai passé une heure à essayer de comprendre d'où venaient plusieurs centaines de synchronisations CUDA supplémentaires... sérieusement, Torch... // Différence avec la version Python : contrairement à la version Python, même lorsque // en ignorant les vérifications de finitude (error_if_nonfinite = false), cette fonction // introduira une synchronisation périphérique CPU (pour les périphériques où cela est nécessaire) // sens !) afin de renvoyer un `double` côté processeur. Cette version C++ // ne peut pas être exécuté de manière totalement asynchrone par rapport au périphérique des gradients.
La synchronisation était en cours sans aucune raison... problème résolu ici