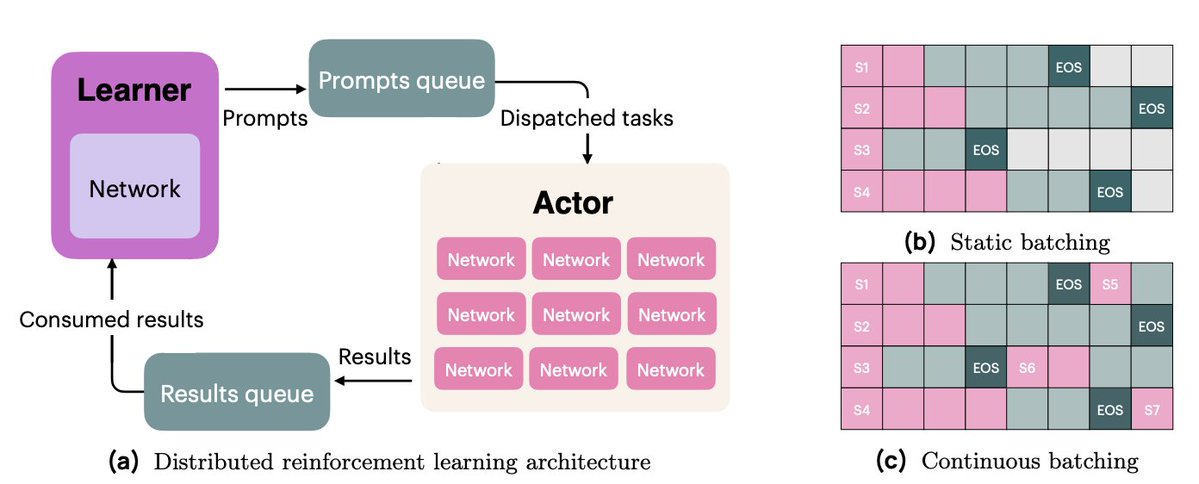
L'infrastructure OlmoRL était quatre fois plus rapide qu'Olmo 2 et permettait de réaliser des expériences à moindre coût. Voici quelques-unes des modifications : 1. Production par lots en continu 2. Mises à jour en vol 3. échantillonnage actif 4. De nombreuses améliorations ont été apportées à notre code multithread.
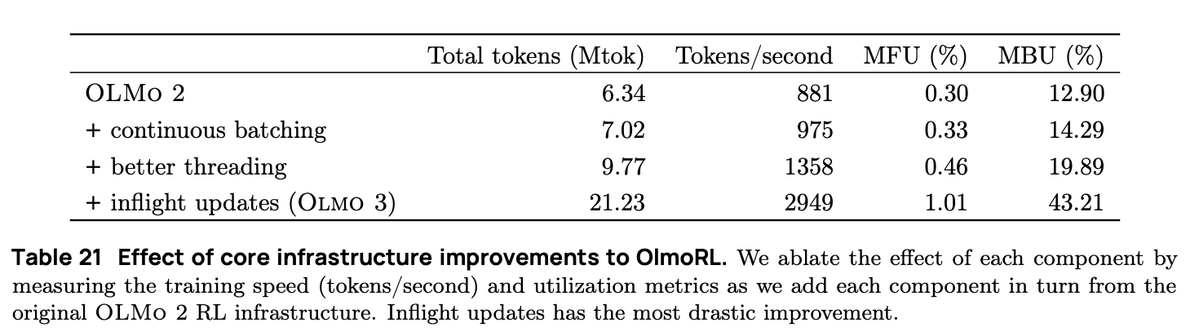
En mode de traitement par lots continu, nous passons à une configuration de génération entièrement asynchrone, où nous avons deux files d'attente : une pour les invites et une pour les résultats de génération. Nos acteurs fonctionnent de manière totalement asynchrone, en récupérant continuellement de nouvelles invites pour générer des requêtes au fur et à mesure que les opérations sont terminées.
Grâce aux mises à jour en temps réel (PipelineRL, développé par @alexpiche_, @DBahdanau et al.), nous mettons à jour nos acteurs en cours de génération. Le système est ainsi beaucoup plus rapide, car nous n'avons plus besoin de vider les files d'attente de génération pour mettre à jour les poids (un problème similaire à celui du traitement par lots statique).

L'échantillonnage actif (une contribution originale de @mnoukhov) résout un problème récurrent dans GRPO où les groupes avec une variance de récompense de 0 (et donc un avantage de 0, donc un gradient de 0) sont filtrés, ce qui entraîne une variation de la taille du lot à chaque étape d'entraînement.
Les travaux précédents résolvaient le problème de la taille variable des lots en échantillonnant trois fois plus de groupes que nécessaire, dans l'espoir d'en avoir toujours suffisamment après le filtrage. Michael, quant à lui, a modifié notre code pour attendre d'avoir un lot complet de groupes à récompense non constante avant l'entraînement.
Cela a nécessité un travail délicat pour assurer la synchronisation entre nos acteurs et l'apprenant.
Enfin, nous avons consacré énormément de temps à la refonte de notre code afin de réduire la synchronisation et permettre ainsi à nos acteurs de fonctionner de manière asynchrone. Cela a nécessité un travail d'ingénierie considérable avec les API de threading et d'asyncio de Python.
Notre travail sur l'infrastructure RL a été un effort collectif, avec la contribution de moi-même, @hamishivi, @mnoukhov, @saurabh_shah2 et @tyleraromero, et construit sur les bases laissées à utiliser par @vwxyzjn.
Pour en savoir plus sur nos travaux, veuillez consulter l'article, le billet de blog et les travaux associés, y compris notre diffusionx.com/natolambert/st…a à 9 h, heure du Pacifique.