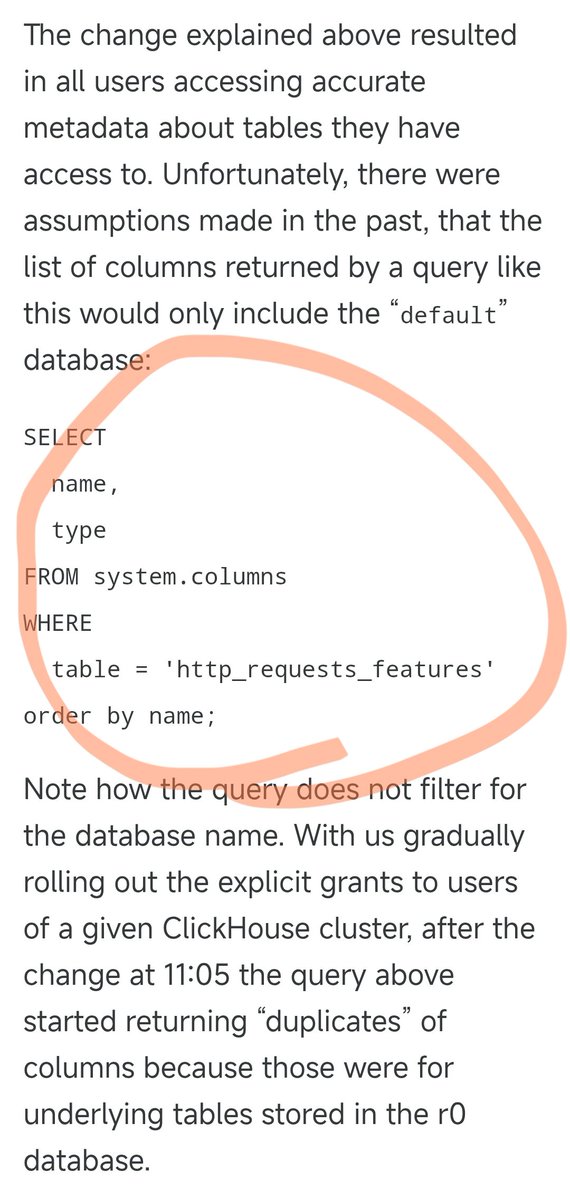
La panne de Cloudflare survenue la nuit dernière a été causée par l'instruction SQL suivante. Auparavant, cette requête SQL fonctionnait parfaitement, interrogeant uniquement les informations des colonnes de la base de données par défaut. Cependant, hier, la mise à jour des permissions de certains utilisateurs a eu pour conséquence que cette requête SQL renvoie des informations de solution provenant à la fois de la base de données par défaut et de la base de données r0 sous-jacente. Lors de cette modification des permissions, personne n'a pensé à adapter la requête SQL en conséquence. Par conséquent, le nombre de résultats de la requête a doublé, entraînant également un doublement de la taille du fichier de résultats. Ce fichier, qui contenait initialement environ 60 entités, en contient désormais environ 120. Ceci nous amène à une caractéristique de conception essentielle. Afin d'optimiser les performances, le module anti-robots de Cloudflare pré-alloue une quantité fixe de mémoire et impose une limite supérieure : il prend en charge un maximum de 200 fonctionnalités. La limite avait été initialement fixée de manière assez indulgente, puisque seulement 60 exemplaires ont été réellement utilisés, laissant une marge de plus de trois fois la marge. Cependant, des problèmes surviennent lorsque le fichier de fonctionnalités dépasse la limite de 200 en raison de données dupliquées. Le code Rust intègre une vérification qui provoque une erreur 500 si le nombre de fonctionnalités dépasse cette limite. Pire encore, ce fichier de configuration est généré automatiquement toutes les 5 minutes et rapidement déployé sur tous les serveurs du monde. Comme les modifications d'autorisations sont appliquées progressivement à chaque nœud de base de données toutes les 5 minutes, selon le nœud sur lequel la requête est exécutée, un fichier correct ou incorrect peut être généré. Cela a engendré un phénomène très étrange : le système fonctionnait puis se déconnectait par intermittence, revenant parfois à la normale et parfois plantant complètement. Ce symptôme a amené les ingénieurs à soupçonner une attaque DDoS. Par coïncidence, la page d'état de Cloudflare (hébergée par un tiers et totalement indépendante de l'infrastructure de Cloudflare) est également tombée en panne à ce moment-là, renforçant encore les soupçons d'une « attaque ». Cela les a amenés à réfléchir dans la mauvaise direction lors de l'identification du problème, ce qui leur a fait perdre du temps. Ce n'est qu'après le déploiement progressif des modifications d'autorisation sur tous les nœuds, et la génération de fichiers corrompus par chacun d'eux, que le système a atteint un état de panne stable. C'est seulement à ce moment-là que les ingénieurs ont pu identifier la véritable cause du problème et le résoudre. La panne a débuté vers 19h28 le 18 novembre à Pékin, a été initialement rétablie à 22h30, puis totalement à 1h06 le 19, pour une durée totale d'environ 5,5 heures. Il s'agissait de la plus importante panne de Cloudflare depuis 2019.