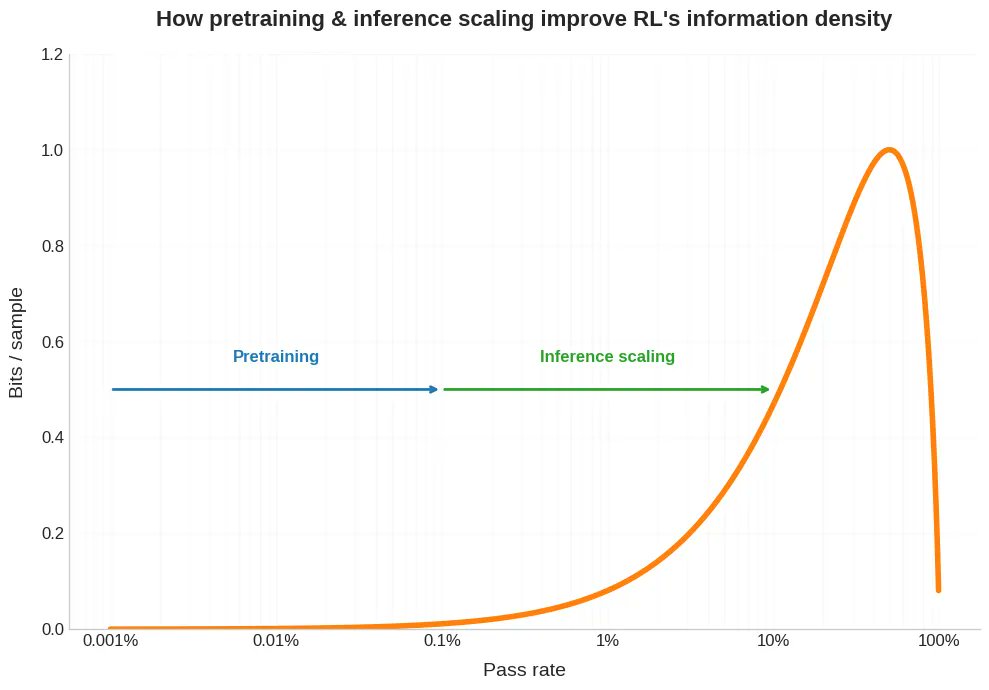
Nouvel article de blog. Récemment, on a beaucoup parlé du fait qu'obtenir un seul échantillon en apprentissage par renforcement (RL) nécessite beaucoup plus de puissance de calcul qu'en pré-entraînement. Mais ce n'est que la moitié du problème. En RL, cet échantillon coûteux vous donne généralement beaucoup moins de bits. Et cela a des implications sur la capacité de RLVR à s'adapter à grande échelle, et nous aide également à comprendre pourquoi l'auto-apprentissage et l'apprentissage par programme sont si utiles pour le RL, pourquoi les modèles RLed sont étrangement irréguliers, et comment nous pouvons envisager ce que les humains font différemment. Lien ci-dessous.