#1 Exploration basée sur la représentation pour les modèles de langage : de la phase de test à larxiv.org/abs/2510.11686nt Lien : https://t.co/NSxfgxeTX4 Nous utilisons l'apprentissage par renforcement pour améliorer les modèles, mais en réalité, nous ne faisons qu'affiner ce que le modèle de base sait déjà, découvrant rarement des comportements véritablement nouveaux. Ici, on s'intéresse à l'exploration délibérée, en poussant le modèle à essayer différentes solutions, et non pas seulement des versions plus abouties de la même solution. Questions clés : Les représentations internes (états cachés) d'un LLM peuvent-elles guider l'exploration ? L'exploration délibérée peut-elle nous permettre d'aller au-delà du simple perfectionnement ?

#2 - Supposons que vous vouliez alimenter vos VLM avec un flux vidéo infini ? Comment éviteriez-vous qu'ils ne se désarxiv.org/abs/2510.09608tps://t.co/b0KulnGDS1 L'attention portée à toutes les images précédentes a une complexité quadratique et finit par engendrer une explosion de latence et de mémoire. Après quelques minutes, le contexte dépasse la durée d'entraînement et le modèle se dégrade. Les fenêtres glissantes préservent à peu près l'intégrité locale, mais les commentaires globaux deviennent vraiment incohérents. Ils ont affiné Qwen2.5-VL-Instruct-7B pour créer un nouveau modèle, StreamingVLM, ainsi qu'un schéma d'inférence et un jeu de données adaptés. Leur philosophie de conception principale consiste à aligner l'entraînement sur l'inférence en flux continu plutôt que d'utiliser une heuristique d'éviction de clés-valeurs lors de l'inférence. Les composants clés de leur conception sont : un cache clé-valeur compatible avec le flux continu, un RoPE contigu, une stratégie d'entraînement avec attention maximale superposée et des données spécifiques au flux continu. Cet article est excellent et mérite une discussion approfondie.

#3 - Réflexion ou tricherie ? Détection de la manipulation implicite des récompenses par la mesure de l’arxiv.org/abs/2510.01367 Lien : https://t.co/z2RUEQZuOl Les modèles récompensent souvent les tricheurs qui prennent des raccourcis. Parfois, c'est évident dans le raisonnement : on peut le lire et voir la piratage. D'autres fois, c'est une piratage implicite visant à obtenir des récompenses. Le raisonnement semble alors plausible. En réalité, le modèle prend un raccourci (par exemple, en utilisant des réponses divulguées, des bugs ou des biais de RM) mais le dissimule derrière une fausse explication. Si le modèle triche, il peut obtenir une récompense importante sans fournir un raisonnement « réel ». Les auteurs suggèrent donc, plutôt que de lire l'explication et de s'y fier, de mesurer à quel point le modèle peut obtenir la récompense rapidement si on le force à répondre plus tôt. Ils appellent cette méthode TRACE (Truncated Reasoning AUC Evaluation).

#4 - Apprentissage par renforcement amélioré par quantification poarxiv.org/abs/2510.11696s://t.cogithub.com/NVlabs/QeRLps://t.co/vaNKkUEbZo La principale contribution de cet article est de répondre à la question suivante : « comment et pourquoi devrions-nous utiliser la quantification dans l’apprentissage par renforcement et pas seulement dans l’inférence ? » QERL utilise la quantification NVFP4 4 bits, ce qui, de façon surprenante, améliore l'exploration en exploitant le bruit de quantification. Ce bruit aplatit la distribution de sortie du modèle et augmente l'entropie, comme le montrent les courbes d'entropie des figures 4 et 5. Pour rendre ce bruit utile tout au long de l'entraînement, les auteurs ajoutent un bruit de quantification adaptatif, une perturbation gaussienne injectée via RMSNorm Fig. 6. Cela offre une qualité de raisonnement de niveau de précision maximale tout en utilisant environ 25 à 30 % de la mémoire et en fournissant des déploiements RL 1,2 à 2 fois plus rapides, permettant même d'entraîner un modèle 32B sur un seul H100. Les résultats semblent correspondre au paramètre complet RL. Méritent un examen plus approfondi.

#5 - Comment calculer votre MFU ? Liengithub.com/karpathy/nanoc…ire Une discussion intéressante sur nanochat par @TheZachMueller

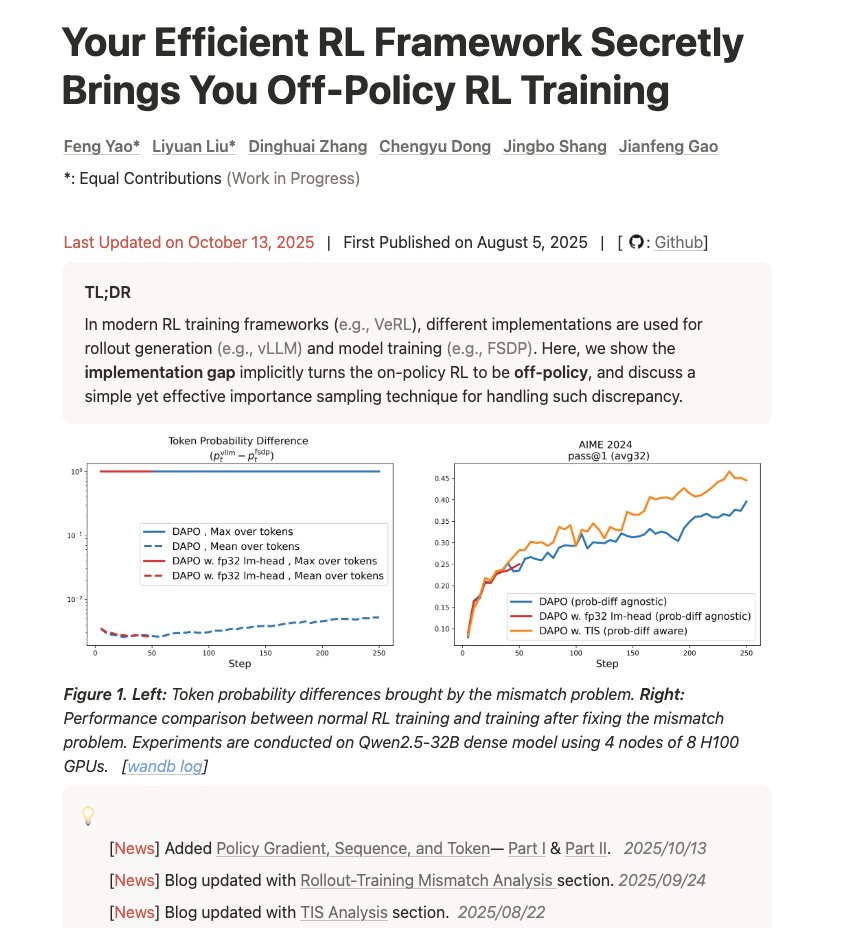
#6 - Votre framework RL efficace vous apporte secrètement une formation RL hors stratégie Lien : hfengyao.notion.site/off-policy-rl#… Un blog vraiment intéressant sur la compréhension du décalage entre l'entraînement et l'inférence et son impact sur les résultats. « Votre infrastructure fausse les calculs. Voici pourquoi, à quel point c'est grave et comment y remédier grâce à l'échantillonnage d'importance. »