Pourquoi acceptons-nous une approximation de la distribution à partir des données/du modèle avec KL direct (image de gauche) ? Pourquoi ne pas travailler sur des algorithmes qui ressemblent à (l'image de droite) ?
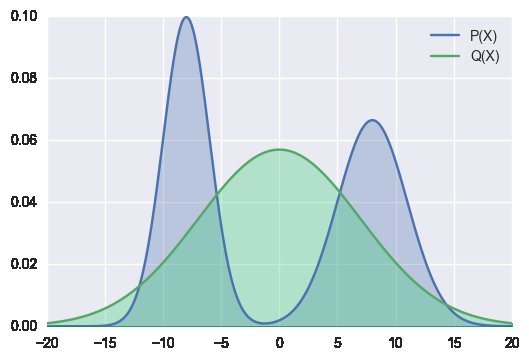

Ou bien le faisons-nous déjà parce que nous minimisons KL avec un biais de récence plus important plutôt que sur l'ensemble de la distribution ?