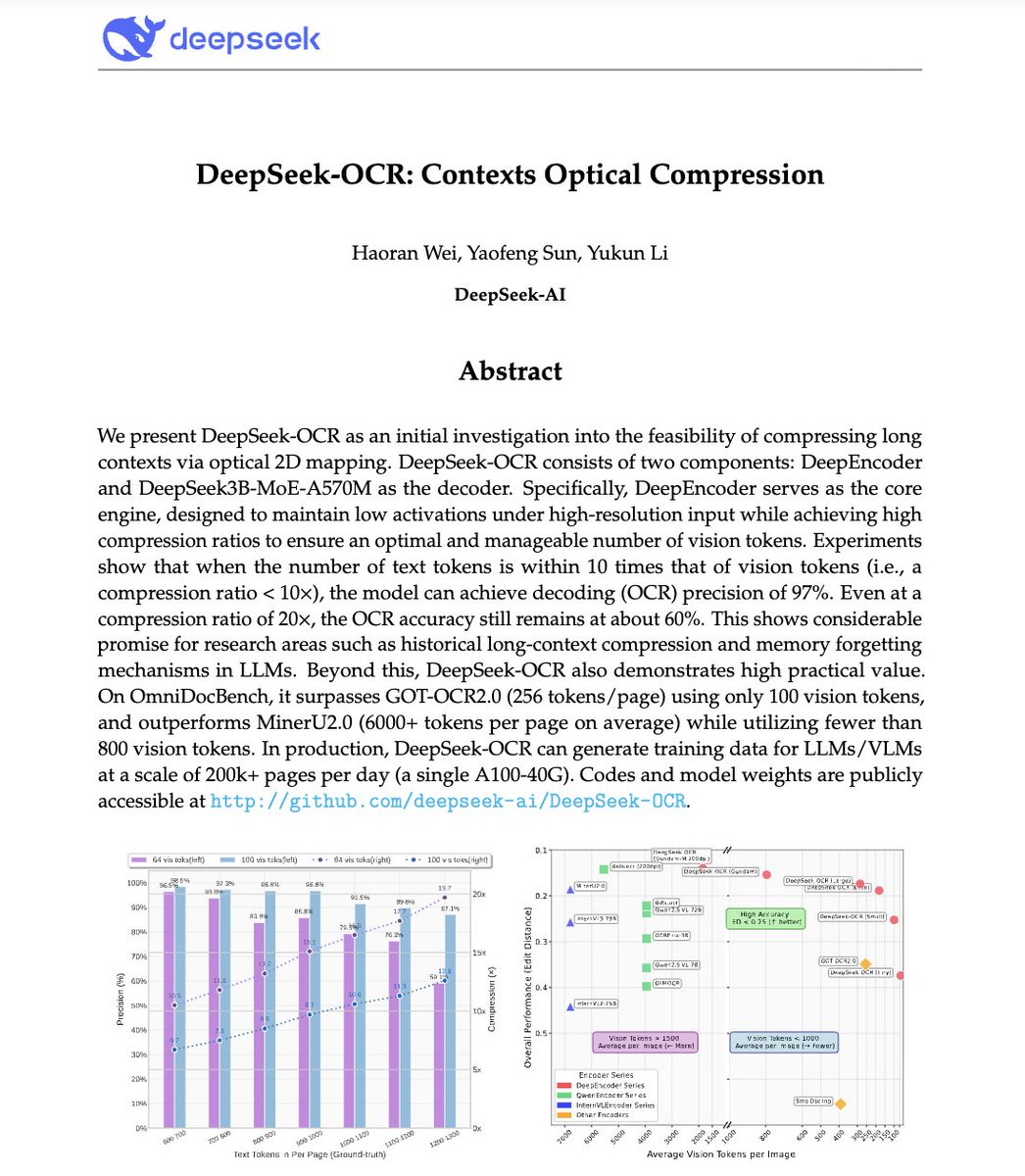
🚨 DeepSeek vient de faire quelque chose de fou. Ils ont construit un système OCR qui compresse les textes longs en jetons de vision, transformant littéralement les paragraphes en pixels. Leur modèle, DeepSeek-OCR, atteint une précision de décodage de 97 % avec une compression de 10x et atteint 60 % même avec une compression de 20x. Cela signifie qu'une seule image peut représenter des documents entiers avec une fraction des jetons nécessaires à un LLM. Encore plus fou ? Il surpasse GOT-OCR 2.0 et MinerU 2.0 tout en utilisant jusqu'à 60 fois moins de jetons et en pouvant traiter plus de 200 000 pages par jour sur un seul A100. Cela pourrait résoudre l’un des plus gros problèmes de l’IA : l’inefficacité du contexte long. Au lieu de payer plus pour des séquences plus longues, les modèles pourraient bientôt voir du texte au lieu de le lire. L’avenir de la compression contextuelle pourrait ne pas être du tout textuel. C'est peut-être optique 👁️ github. com/deepseek-ai/DeepSeek-OCR
1. Compression vision-texte : l'idée centrale Les LLM ont du mal à gérer les documents longs car l'utilisation des jetons évolue de manière quadratique avec la longueur. DeepSeek-OCR inverse cela : au lieu de lire du texte, il encode des documents complets sous forme de jetons de vision, chaque jeton représentant un élément compressé d'informations visuelles. Résultat : vous pouvez intégrer 10 pages de texte dans le même budget de jetons qu'il faut pour traiter 1 page dans GPT-4.

2. DeepEncoder - Le compresseur optique Rencontrez la star : DeepEncoder. Il utilise deux dorsales SAM (pour la perception) et CLIP (pour la vision globale) reliées par un compresseur convolutif 16×. Cela lui permet de maintenir une compréhension haute résolution sans faire exploser la mémoire d'activation. L'encodeur convertit des milliers de patchs d'image → quelques centaines de jetons de vision compacts.

3. Mode « Gundam » multi-résolution Les documents varient : factures ≠ plans ≠ journaux. Pour gérer cela, DeepSeek-OCR prend en charge plusieurs modes de résolution : Tiny, Small, Base, Large et Gundam. Le mode Gundam combine des tuiles locales + une vue globale évoluant de 512 × 512 à 1 280 × 1 280 de manière efficace. Un modèle, plusieurs résolutions, pas de recyclage.

4. Moteur de données OCR 1.0 à 2.0 Ils ne se sont pas seulement entraînés sur des analyses de texte. Les données de DeepSeek-OCR incluent : • Plus de 30 millions de pages PDF dans 100 langues • 10 millions d'échantillons OCR de scènes naturelles • 10 millions de graphiques + 5 millions de formules chimiques + 1 million de problèmes de géométrie Il ne s’agit pas seulement de lire, mais d’analyser des diagrammes, des équations et des mises en page scientifiques.

5. Il ne s’agit pas « juste d’un autre OCR ». C'est une preuve de concept pour la compression de contexte. Si le texte peut être représenté visuellement avec 10 fois moins de jetons, les LLM pourraient utiliser la même idée pour la mémoire à long terme et le raisonnement efficace. Imaginez que GPT-5 traite un document de 1 M de jetons comme une image cartographique de 100 000 jetons.

Arrêtez de perdre des heures à écrire des invites → Plus de 10 000 invites prêtes à l'emploi → Créez le vôtre en quelques secondes → Accès à vie. Pagodofprompt.ai/pricingez votre exemplaire 👇