Je suis ravi de publier mon nouveau dépôt : nanochat ! (Il est parmi les plus déjantés que j'ai écrits). Contrairement à mon précédent dépôt similaire, nanoGPT, qui ne couvrait que le pré-entraînement, nanochat est un pipeline d'entraînement/d'inférence minimal, partant de zéro et full-stack, d'un simple clone de ChatGPT dans une base de code unique et minimale en termes de dépendances. Vous démarrez un boîtier GPU cloud, exécutez un seul script et, en seulement 4 heures, vous pouvez communiquer avec votre propre LLM dans une interface Web de type ChatGPT. Il pèse environ 8 000 lignes de code, à mon avis, assez propre pour : - Entraîner le tokenizer à l'aide d'une nouvelle implémentation de Rust ; - Pré-entraîner un Transformer LLM sur FineWeb, évaluer le score CORE sur plusieurs métriques ; - Entraîner en cours d'exécution sur les conversations utilisateur-assistant de SmolTalk, les questions à choix multiples et l'utilisation des outils. - SFT, évaluer le modèle de chat sur des QCM de connaissances mondiales (ARC-E/C, MMLU), mathématiques (GSM8K), code (HumanEval). - RL du modèle (optionnellement sur GSM8K avec « GRPO »). - Inférence efficace du modèle dans un moteur avec cache KV, pré-remplissage/décodage simple, utilisation d'outils (interpréteur Python dans un bac à sable léger), communication via CLI ou interface Web de type ChatGPT. - Rédiger un rapport Markdown unique, résumant et gamifiant l'ensemble. Même pour seulement 100 $ (environ 4 heures sur un nœud 8XH100), vous pouvez entraîner un petit clone de ChatGPT avec lequel vous pouvez communiquer, écrire des histoires/poèmes et répondre à des questions simples. Environ 12 heures dépassent la métrique GPT-2 CORE. À mesure que vous progressez vers 1 000 $ (environ 41,6 heures de formation), le modèle devient rapidement beaucoup plus cohérent et peut résoudre des problèmes mathématiques/de code simples et passer des QCM. Par exemple, un modèle de profondeur 30 entraîné pendant 24 heures (soit environ l'équivalent des FLOP de GPT-3 Small 125M et 1/1000e de GPT-3) atteint 40 s sur MMLU, 70 s sur ARC-Easy, 20 s sur GSM8K, etc. Mon objectif est de rassembler l'ensemble de la pile « de base solide » dans un dépôt cohérent, minimal, lisible, piratable et potentiellement duplicable. nanochat sera le projet de clôture du LLM101n (encore en développement). Je pense qu'il a également le potentiel de devenir un outil de recherche, ou un benchmark, similaire à nanoGPT avant lui. Il n'est en aucun cas terminé, optimisé ou optimisé (en fait, je pense qu'il y a probablement beaucoup de possibilités à portée de main), mais je pense que le squelette global est suffisamment bon pour pouvoir être publié sur GitHub, où tous les éléments pourront être améliorés. Le lien vers le dépôt et une présentation détaillée du speedrun nanochat se trouvent dans la réponse.

Dépôt GitHub github.com/karpathy/nanoc…rY Procédure pas à pas beaucoup plus détaillée etgithub.com/karpathy/nanoc…co/YmHaZfNjcJ Exemple de conversation avec le nanochat de 4 heures à 100 $ dans l'interface Web. C'est… divertissant :) Les modèles plus grands (par exemple, une profondeur de 26 heures sur 12 heures ou de 30 heures sur 24 heures) deviennent rapidement plus cohérents.

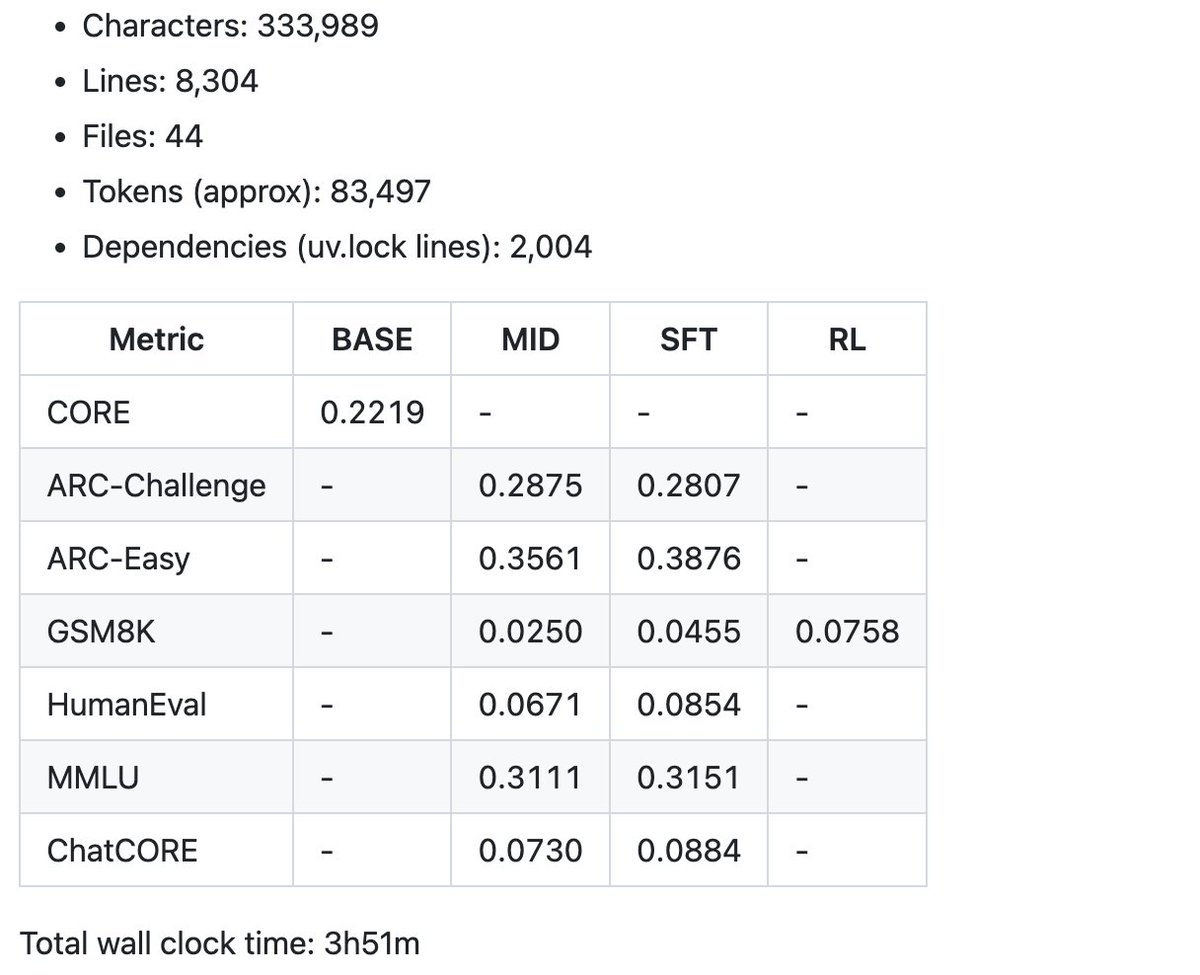
Et voici un exemple de quelques indicateurs récapitulatifs produits par le speedrun à 100 $ dans le bulletin pour commencer. Le code actuel compte un peu plus de 8 000 lignes, mais j'ai essayé de le garder clair et bien commenté. Vient maintenant la partie amusante : le réglage et les montées.