Tang Jie (@jietang) es profesor de la Universidad de Tsinghua y científico jefe de IA en Zhipu (la empresa creadora de los modelos de la serie GLM). Además, es uno de los expertos más expertos en modelos a gran escala en China. Recientemente publicó una extensa publicación en Weibo (ver comentarios) donde analiza sus perspectivas sobre los modelos a gran escala en 2025. Curiosamente, Tang Jie y Andrej Karpathy comparten muchas observaciones, pero también tienen diferentes enfoques. Al analizar las perspectivas de estos dos destacados expertos en conjunto, se obtiene una visión más completa. El contenido es bastante largo, pero hay una frase que quiero destacar al principio: El primer principio de la aplicación de modelos de IA no debería ser la creación de nuevas aplicaciones; su esencia es que la IA general sustituya el trabajo humano. Por lo tanto, desarrollar una IA capaz de sustituir diferentes trabajos es clave para su aplicación. Si desarrolla aplicaciones de IA, debería considerar repetidamente esta afirmación: el principio fundamental de las aplicaciones de IA no es crear nuevos productos, sino reemplazar el trabajo humano. Una vez que comprenda esto, las prioridades en muchos aspectos quedarán claras. El argumento central de Tang Jie tiene siete capas de lógica. --- Primer nivel: El pre-entrenamiento no lo mató, simplemente ya no es el único protagonista. El entrenamiento previo sigue siendo la base para que los modelos adquieran conocimiento del mundo y capacidades básicas de razonamiento. Más datos, parámetros más amplios y una computación más intensiva siguen siendo las formas más eficientes de mejorar la inteligencia de un modelo. Esto es como un niño en crecimiento: la cantidad de alimento (potencia de procesamiento) y nutrición (datos) debe ser suficiente. Esta es una ley física ineludible. Pero la inteligencia por sí sola no basta. Los modelos actuales tienen un problema: tienden a ser desequilibrados. Para mejorar sus puntuaciones de referencia, muchos modelos se centran en problemas específicos, lo que los hace menos eficaces en situaciones reales complejas. Esto es como enviar a un niño a un lugar de trabajo real después de nueve años de educación obligatoria (preformación) para que se encargue de los problemas que no aparecen en los libros de texto: ahí es donde se desarrollan las verdaderas habilidades. Por lo tanto, el siguiente enfoque se centra en el entrenamiento intermedio y posterior. Estas dos etapas son responsables de activar la capacidad del modelo, especialmente su capacidad de alineación en escenas de cola larga. ¿Qué son los escenarios de cola larga? Son necesidades poco comunes pero reales. Por ejemplo, ayudar a los abogados a organizar ciertos contratos especiales o ayudar a los médicos a analizar imágenes de enfermedades raras. Estos escenarios representan un pequeño porcentaje del conjunto de pruebas general, pero son cruciales en aplicaciones del mundo real. Si bien los puntos de referencia generales evalúan el rendimiento del modelo, también pueden provocar sobreajuste en muchos modelos. Esto coincide con la opinión de Karpathy de que «entrenar en el conjunto de pruebas es un arte nuevo». Todos intentan mejorar su clasificación, pero alcanzar puntuaciones altas en la clasificación no equivale a resolver problemas del mundo real. --- La segunda capa: Agente, representa la transición de “estudiante” a “persona trabajadora”. Tang Jie utilizó una analogía vívida: Sin capacidades de agente, un modelo grande es solo un "doctorado teórico". Por muchos libros que lea alguien, incluso al llegar al nivel posdoctoral, si no puede resolver problemas, es solo un contenedor de conocimiento, incapaz de generar productividad. Esta analogía es acertada. El preentrenamiento es como asistir a clases, y el aprendizaje por refuerzo es como practicar problemas, pero estos aún se encuentran en la fase de aprendizaje. El agente es clave para que el modelo realmente funcione y marca el umbral para acceder al mundo real y generar valor práctico. La generalización y la transferencia entre diferentes entornos de agentes no son fáciles. Las habilidades que se desarrollan en un entorno de código pueden no funcionar bien en un entorno de navegador. El enfoque más sencillo ahora es acumular continuamente datos de más entornos y aplicar aprendizaje de refuerzo adaptado a ellos. Anteriormente, al desarrollar agentes, asociábamos diversas herramientas al modelo. La tendencia actual es incorporar directamente los datos obtenidos con estas herramientas al ADN del modelo para su entrenamiento. Quizás parezca una tontería, pero es el camino más eficaz en la actualidad. Karpathy también mencionó a Agent como uno de los cambios más importantes de este año. Citó a Claude Code como ejemplo, enfatizando que Agent debería poder "vivir en tu computadora", invocando herramientas, ejecutando bucles y resolviendo problemas complejos. --- La tercera capa: La memoria es una necesidad básica, pero aún no está claro cómo lograrla. Tang Jie dedicó mucho tiempo a analizar la memoria. Considera que es esencial para la implementación de modelos en entornos reales. Dividió la memoria humana en cuatro capas: - Memoria a corto plazo, correspondiente a la corteza prefrontal - Memoria a medio plazo, correspondiente al hipocampo. Los recuerdos a largo plazo se localizan en la corteza cerebral. - Memoria histórica humana, correspondiente a Wikipedia y registros históricos La IA también necesita imitar este mecanismo; el modelo grande podría corresponder a: - Ventana de contexto → Memoria a corto plazo - Búsqueda RAG → Memoria intermedia - Parámetros del modelo → Memoria a largo plazo Un enfoque es la "memoria comprimida", que almacena información importante en un formato conciso y simplista dentro del contexto. Los "contextos ultralargos" actuales solo abordan la memoria a corto plazo, alargando esencialmente la "nota adhesiva" utilizable. Si la ventana de contexto se amplía lo suficiente en el futuro, se podría alcanzar la memoria a corto, medio y largo plazo. Pero hay un problema aún más complejo: ¿cómo actualizamos el conocimiento del modelo? ¿Cómo modificamos los parámetros? Este sigue siendo un problema sin resolver. --- La cuarta capa: el aprendizaje en línea y la autoevaluación pueden ser el próximo paradigma de escalamiento. Esta sección es la parte más progresista del punto de vista de Tang Jie. El modelo actual está "fuera de línea", lo que significa que se entrena, pero no cambia. Esto presenta varios problemas: el modelo no puede iterar por sí solo, el reentrenamiento desperdicia recursos y se pierden muchos datos interactivos. Lo ideal sería que el modelo pudiera aprender en línea y se volviera más inteligente con cada uso. Sin embargo, para lograrlo, existe un requisito previo: el modelo debe saber si es correcto o no. Esto se denomina "autoevaluación". Si el modelo puede juzgar la calidad de su propio resultado, incluso si se trata de un juicio probabilístico, conoce el objetivo de optimización y puede mejorarse a sí mismo. Tang Jie cree que desarrollar un mecanismo de autoevaluación para un modelo es un problema complejo, pero también podría ser la dirección del próximo paradigma de escalamiento. Utilizó varios términos: aprendizaje continuo, aprendizaje en tiempo real y aprendizaje en línea. Esto coincide con el punto de Karpathy sobre el RLVR. El RLVR es eficaz precisamente porque proporciona "recompensas verificables", lo que permite al modelo saber si es correcto o no. Si este mecanismo se puede generalizar a más escenarios, el aprendizaje en línea podría convertirse en una posibilidad. --- La quinta capa: El primer principio de las aplicaciones de IA es el "reemplazo de trabajo". Esta es la frase que más me inspiró: El primer principio de la aplicación de modelos de IA no debería ser la creación de nuevas aplicaciones; su esencia es que la IA general sustituya el trabajo humano. Por lo tanto, desarrollar una IA capaz de sustituir diferentes trabajos es clave para su aplicación. La esencia de la IA no es crear nuevas aplicaciones, sino reemplazar trabajos humanos. Dos caminos: 1. Transformar el software que antes requería intervención humana en IA. 2. Crear software de IA que se alinee con un trabajo humano específico, reemplazando directamente a los trabajadores humanos. El chat ya ha reemplazado parcialmente la búsqueda y también ha incorporado la interacción emocional. El siguiente paso es reemplazar el servicio de atención al cliente, los programadores júnior y los analistas de datos. Por lo tanto, el punto de inflexión en 2026 estará en que "la IA sustituya a otros trabajos". Los emprendedores no deberían pensar en "qué software quiero desarrollar para los usuarios", sino más bien en "qué tipo de empleado de IA quiero crear para ayudar al jefe a reducir los costos laborales para un puesto determinado". En otras palabras, en lugar de pensar siempre en crear un nuevo producto "AI+X", primero piense qué trabajos humanos se pueden reemplazar y luego trabaje hacia atrás para determinar la forma del producto. Esto coincide con la observación de Karpathy sobre «Cursor para X». Si el Cursor es esencialmente «la versión basada en IA del trabajo del programador», entonces surgirán cosas similares en diversas industrias. --- Sexta capa: El modelo de todo el dominio es una "proposición falsa". Este punto de vista puede incomodar a algunos, pero Tang Jie lo expresa sin rodeos: el modelo de dominio específico es una proposición falsa. Si hablamos de IAG, ¿qué sentido tiene la "IAG de dominio específico"? La razón por la que existen grandes modelos específicos de dominio es que las empresas de aplicaciones no están dispuestas a admitir la derrota frente a las empresas de modelos de IA y esperan construir un foso con conocimientos del dominio y convertir la IA en una herramienta. Pero la esencia de la IA es un "tsunami": arrasará con todo a su paso. Algunas empresas de ciertos sectores inevitablemente abandonarán sus ventajas competitivas y se verán atraídas por el mundo de la IA general. Sus datos de dominio, procesos y datos de agentes se incorporarán gradualmente al modelo principal. Por supuesto, los modelos de dominio existirán durante mucho tiempo antes de que la IA general se materialice. Pero ¿cuánto durará este lapso? Es difícil predecirlo, ya que la IA se desarrolla demasiado rápido. --- La séptima capa: Inteligencia multimodal y encarnada: un futuro brillante pero un camino difícil. La computación multimodal es sin duda el futuro. Pero el problema actual es que ofrece poca ayuda para ampliar el límite de inteligencia de la IA general. El texto, la multimodalidad y la generación multimodal pueden desarrollarse de forma más eficiente por separado. Por supuesto, explorar una combinación de las tres requiere valentía y financiación. La inteligencia encarnada (robots) es aún más difícil. El reto es el mismo que con los agentes: versatilidad. Se le enseña a un robot a funcionar en el escenario A, pero no funciona en otro. ¿Qué se hace? Recopilar y sintetizar datos es difícil y costoso. ¿Qué hacer? Recopilar o sintetizar datos. Ninguna de las dos opciones es fácil y ambas son costosas. Pero, por el contrario, una vez que aumenta la escala de datos y surgen capacidades de propósito general, surge naturalmente una barrera de entrada. Otro problema que a menudo se pasa por alto es que los propios robots también representan un problema. La inestabilidad y los fallos frecuentes son problemas de hardware que limitan el desarrollo de la inteligencia incorporada. Tang Jie predice que se lograrán avances significativos en estas áreas para 2026. --- Al conectar el artículo de Tang Jie con el panorama general, se revela una hoja de ruta bastante clara: Actualmente, el escalamiento pre-entrenado sigue siendo efectivo, pero se debe poner más énfasis en la alineación y las capacidades de cola larga. Recientemente, los agentes han supuesto un avance clave que ha permitido que los modelos evolucionen de "hablar" a "hacer". A medio plazo, los sistemas de memoria y el aprendizaje en línea son cursos esenciales, y los modelos deben aprender a autoevaluarse e iterar. A largo plazo, la sustitución de puestos de trabajo es la esencia de las aplicaciones, y la ventaja competitiva del dominio será superada por la IAG. A largo plazo, los enfoques multimodales e incorporados se desarrollarán de forma independiente, a la espera de la maduración de la tecnología y los datos. --- Al comparar los puntos de vista de Tang Jie y Karpathy, se pueden observar varios puntos de consenso: En primer lugar, el cambio central en 2025 es la actualización del paradigma de formación, desde la "preformación como método principal" a la "colaboración en múltiples etapas". En segundo lugar, Agent es un hito, un salto clave para los modelos desde el aprendizaje hasta la acción. En tercer lugar, existe una brecha entre los puntajes de referencia y la capacidad real, y esta cuestión está recibiendo cada vez más atención. En cuarto lugar, la esencia de las aplicaciones de IA es reemplazar o mejorar los trabajos humanos, no crear aplicaciones por el mero hecho de crear aplicaciones. Los diferentes enfoques también son interesantes. Karpathy se centra más en la cuestión filosófica de "¿qué forma tiene la inteligencia artificial?", mientras que Tang Jie se centra más en el problema de ingeniería de "cómo implementar el modelo en escenarios reales". Uno se centra más en la "comprensión" y el otro en la "implementación". Ambas perspectivas son necesarias. Solo con una comprensión clara podemos saber si vamos por buen camino; solo con una ingeniería sólida podemos convertir las ideas en realidad. 2026 será un año maravilloso.
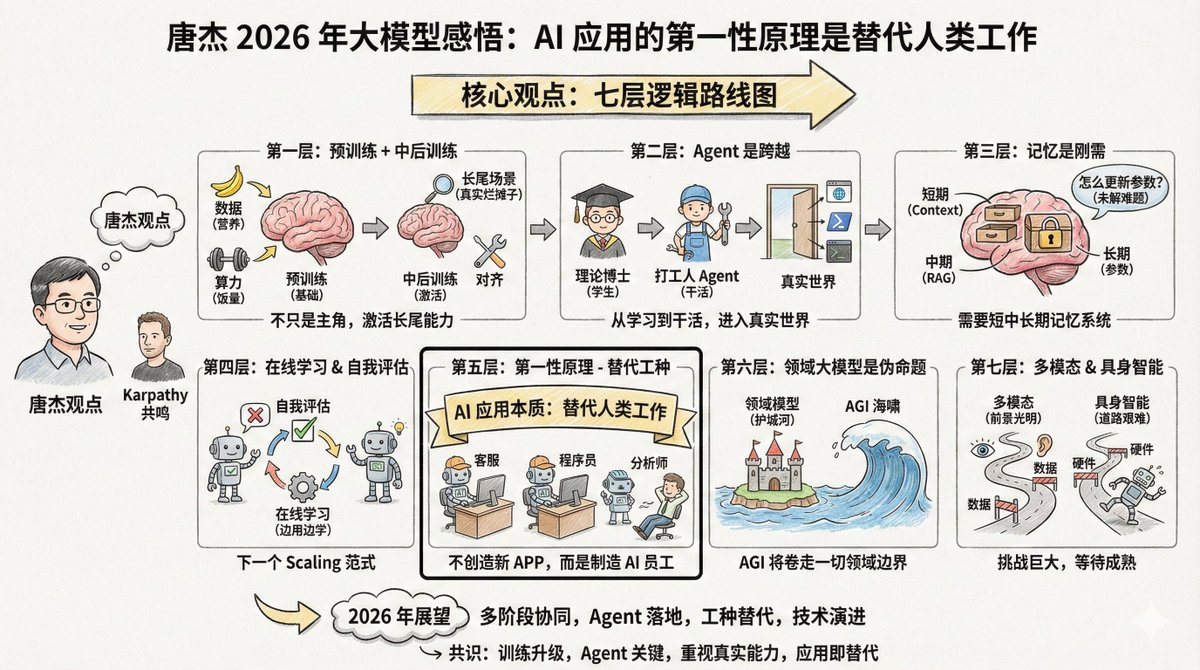
El siguienteweibo.com/2126427211/QjI… de Tang Jie: https://t.co/AOdkBXNIey Me gustaría compartir algunas ideas recientes, esperando que sean útiles para todos. El preentrenamiento permite que los modelos grandes adquieran un conocimiento práctico del mundo y posean capacidades básicas de razonamiento. Más datos, parámetros más amplios y una computación más saturada siguen siendo la forma más eficiente de escalar los modelos de pedestal. Activar la alineación y mejorar las capacidades de inferencia, especialmente las de cola larga más completas, es clave para garantizar el rendimiento del modelo. Si bien los benchmarks generales evalúan el rendimiento general de los modelos, también pueden provocar sobreajuste en muchos de ellos. En escenarios reales, ¿cómo pueden los modelos alinear escenas reales de cola larga con mayor rapidez y precisión, mejorando así la sensación de realismo? El entrenamiento a mitad y después del entrenamiento permite una alineación rápida y sólidas capacidades de inferencia en más escenarios. Las capacidades de los agentes representan un hito en la expansión de las capacidades de los modelos y son clave para que los modelos de IA se integren al mundo real (virtual/físico). Sin ellas, los modelos grandes permanecerán en la etapa de aprendizaje teórico, como una persona que aprende continuamente, incluso hasta obtener un doctorado, acumulando conocimientos sin transformarlos en productividad. Anteriormente, los agentes se implementaban mediante la aplicación de modelos; ahora, los modelos pueden integrar directamente los datos de los agentes en el proceso de entrenamiento, lo que aumenta su versatilidad. Sin embargo, el desafío persiste: la generalización y la transferencia entre diferentes entornos de agentes no son fáciles. Por lo tanto, la solución más sencilla es aumentar continuamente los datos de diferentes entornos de agentes e implementar aprendizaje por refuerzo adaptado a dichos entornos. Lograr la memoria del modelo es esencial, una capacidad necesaria para que cualquier modelo se aplique en entornos reales. La memoria humana se divide en cuatro etapas: corto plazo (corteza prefrontal), mediano plazo (hipocampo), largo plazo (corteza cerebral distribuida) e histórica (wiki o libros de historia). Es crucial cómo los modelos grandes logran la memoria en las diferentes etapas. El contexto, el marco temporal y los parámetros del modelo pueden corresponder a diferentes etapas de la memoria humana, pero la clave está en cómo lograrlo. Un enfoque es la compresión de la memoria, que consiste simplemente en almacenar el contexto. Si un modelo grande puede soportar contextos suficientemente largos, lograr la memoria a corto, mediano y largo plazo se vuelve prácticamente posible. Sin embargo, iterar a través del conocimiento del modelo y modificar sus parámetros sigue siendo un desafío importante. Aprendizaje en línea y autoevaluación. Con la comprensión de los mecanismos de memoria, el aprendizaje en línea se convierte en un enfoque clave. Los modelos actuales a gran escala se reentrenan periódicamente, lo que presenta varios problemas: el modelo no puede iterarse por sí mismo, pero el autoaprendizaje y la autoiteración serán inevitablemente una capacidad en la siguiente etapa; el reentrenamiento también es un desperdicio y resulta en la pérdida de una gran cantidad de datos interactivos. Por lo tanto, es crucial lograr el aprendizaje en línea, y la autoevaluación es un aspecto clave del mismo. Para que un modelo aprenda por sí mismo, primero debe saber si es correcto o incorrecto. Si lo sabe (aunque solo sea probabilísticamente), conocerá el objetivo de optimización y podrá mejorar. Por lo tanto, construir un mecanismo de autoevaluación del modelo es un desafío. Este también podría ser el próximo paradigma de escalamiento. ¿Aprendizaje continuo/aprendizaje en tiempo real/aprendizaje en línea? Finalmente, a medida que el desarrollo de modelos a gran escala se vuelve cada vez más integral, es inevitable combinar el desarrollo y la aplicación de modelos. El objetivo principal de la aplicación de modelos de IA no debería ser la creación de nuevas aplicaciones; su esencia es que la IA sustituya el trabajo humano. Por lo tanto, desarrollar una IA que sustituya diferentes trabajos es clave para su aplicación. El chat sustituye parcialmente la búsqueda y, en cierto modo, incorpora la interacción emocional. El próximo año será un año clave para la IA que sustituya diferentes trabajos. En conclusión, analicemos la multimodalidad y la corporización. La multimodalidad es, sin duda, un futuro prometedor, pero el problema actual es que no contribuye significativamente al límite superior inteligente de la IAG, y el límite superior inteligente exacto de la IAG general sigue siendo desconocido. Quizás el enfoque más eficaz sea desarrollarlas por separado: texto, multimodalidad y generación multimodal. Por supuesto, explorar la combinación de estas tres de forma moderada podría revelar capacidades muy diferentes, pero esto requiere valentía y un apoyo financiero sustancial. De igual manera, si comprendes a los agentes, sabrás dónde residen los puntos débiles de la inteligencia corpórea: es demasiado difícil generalizar (aunque esto no es necesariamente cierto), pero activar capacidades corpóreas generales con una muestra pequeña es prácticamente imposible. Entonces, ¿qué hacer? Recopilar o sintetizar datos no es fácil ni económico. Por el contrario, una vez que la escala de datos aumenta, las capacidades generales emergerán de forma natural y crearán una barrera de entrada. Por supuesto, esto solo es un desafío relacionado con la inteligencia. Para la inteligencia corpórea, los propios robots también representan un problema; la inestabilidad y los fallos frecuentes limitan su desarrollo. Se esperan avances significativos en estas áreas para 2026. Analicemos también el modelo maestro de dominio y sus aplicaciones. Siempre he creído que este modelo es una proposición falsa; con la IA ya implementada, ¿qué IA específica de dominio existe...? Sin embargo, dado que la IA no se ha desarrollado plenamente, los modelos de dominio existirán durante mucho tiempo (es difícil decir cuánto tiempo, dado el rápido ritmo de desarrollo de la IA). La existencia de modelos de dominio refleja esencialmente la reticencia de las empresas de aplicaciones a reconocer la derrota ante las empresas de IA. Esperan construir un foso de conocimiento del dominio, resistir la intrusión de la IA y dominar la IA como herramienta. Pero la IA es inherentemente como un tsunami: arrasa con todo a su paso. Algunas empresas de dominio inevitablemente romperán sus fosos y se verán atraídas por el mundo de la IA. En resumen, los datos de dominio, los procesos y los datos de los agentes entrarán gradualmente en el modelo maestro. La aplicación de modelos a gran escala también debe volver a los principios básicos: la IA no necesita crear nuevas aplicaciones. Su esencia reside en simular, reemplazar o asistir a los humanos en la realización de ciertas tareas esenciales (ciertos trabajos). Esto probablemente da lugar a dos tipos: uno consiste en habilitar software existente mediante IA, modificando lo que originalmente requería intervención humana; el otro consiste en crear software de IA adaptado a una tarea humana específica, reemplazando la mano de obra humana. Por lo tanto, la aplicación de modelos a gran escala debe ayudar a las personas y crear nuevo valor. Si se crea un software de IA, pero nadie lo usa y no puede generar valor, entonces ese software de IA carece de vitalidad.