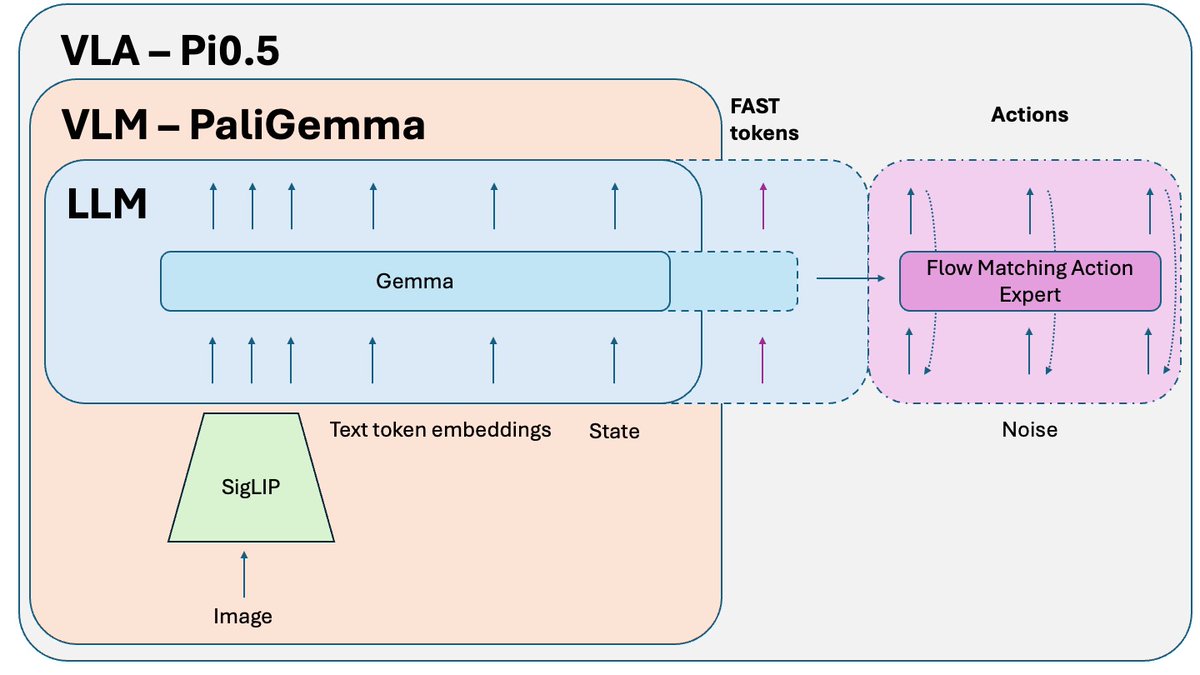
Pi0.5 de @physical_int es una de las mejores políticas de robótica de extremo a extremo de código abierto en este momento 🤖 Es una versión mejorada de Pi0. Y los avances más recientes de PI se basan en ella. Analicemos cómo funciona:
¿Qué cambió respecto a Pi0? - Tokenización FAST: había una versión FAST opcional en Pi0, pero para Pi0.5, es una parte esencial del entrenamiento. - Sistema 2: siguiendo el artículo de Hi Robot, Pi 0.5 utiliza su parte VLM como un sistema 2 de razonamiento de alto nivel para razonar y planificar tareas complejas. - Mejor receta de entrenamiento y un par de pequeños ajustes.
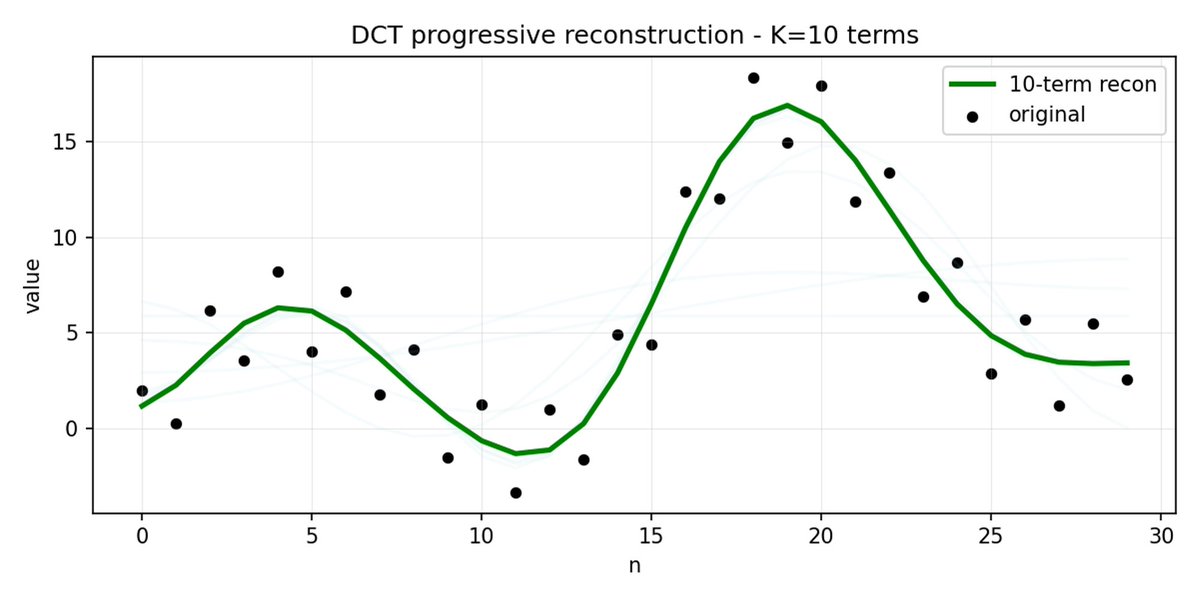
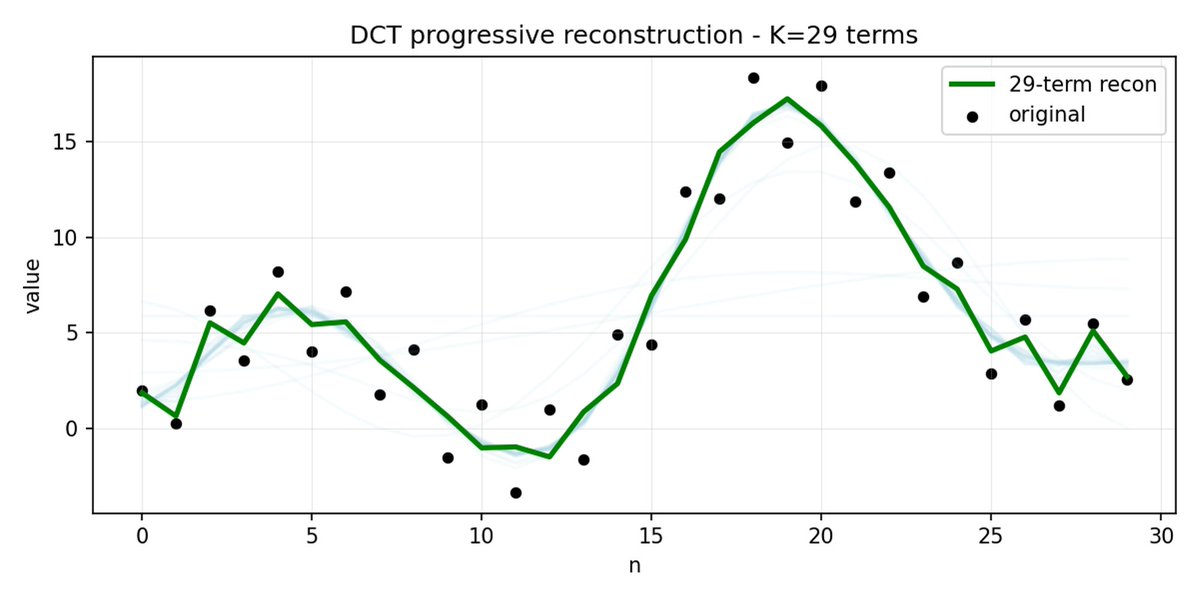
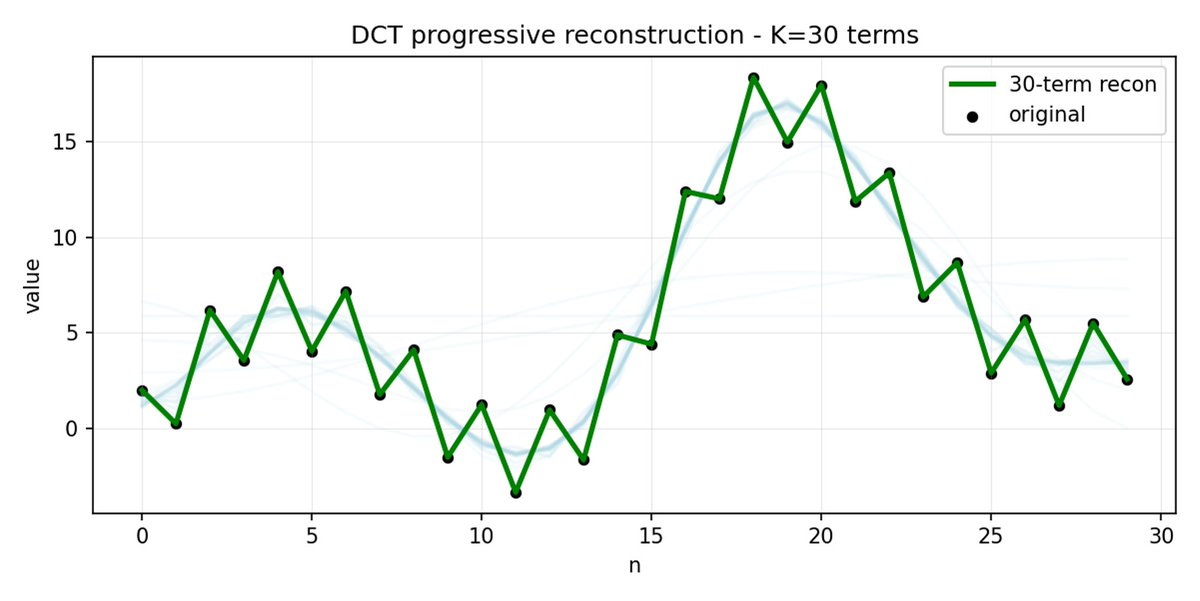
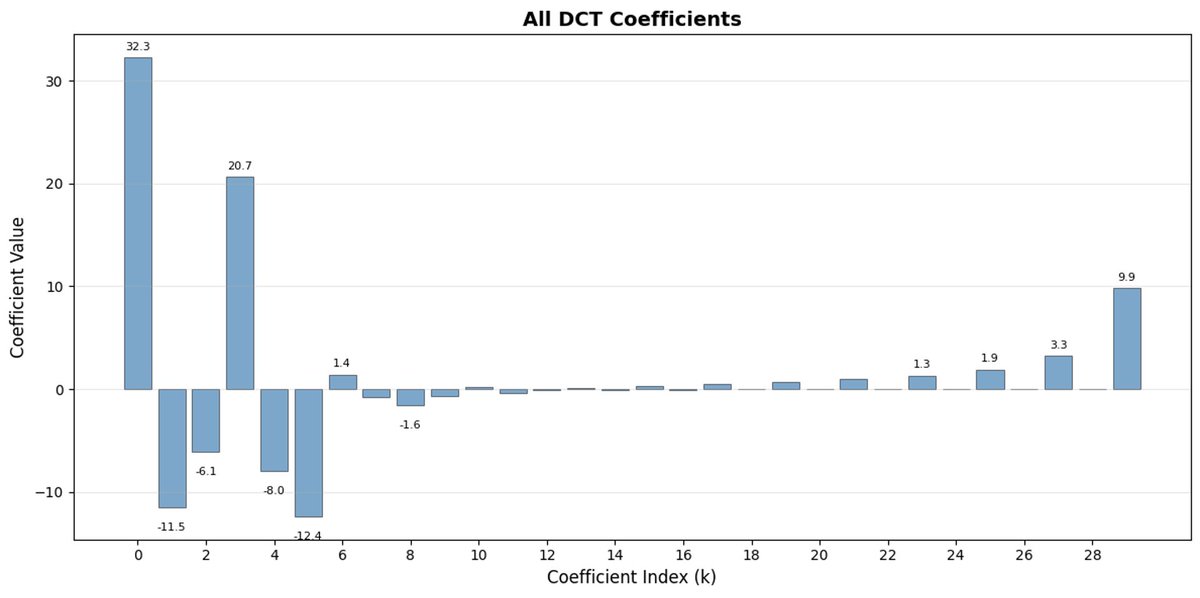
FAST es un enfoque de tokenización que permite comprimir secuencias de acción en tokens discretos con mucha densidad de información utilizando DCT (Transformada de coseno discreta) y BPE (Codificación de pares de bytes). DCT es el mismo algoritmo que se utiliza para la compresión de imágenes en JPEG. Representa la señal como una suma de funciones coseno con diferentes frecuencias. Los primeros componentes capturan la tendencia y la forma general de la señal, mientras que los demás componentes capturan cada vez más detalles. El JPEG progresivo envía primero los componentes de baja frecuencia y la imagen se ve borrosa, luego se vuelve más nítida a medida que se agregan más componentes.



FAST hace lo mismo para los fragmentos de acción. En lugar de predecir 30 valores de acción correlacionados, predice una representación más corta y significativa. A menudo, es posible conservar sólo unos pocos coeficientes principales (que contienen la mayor parte de la energía de la señal original) y aun así reconstruir la trayectoria bastante bien.
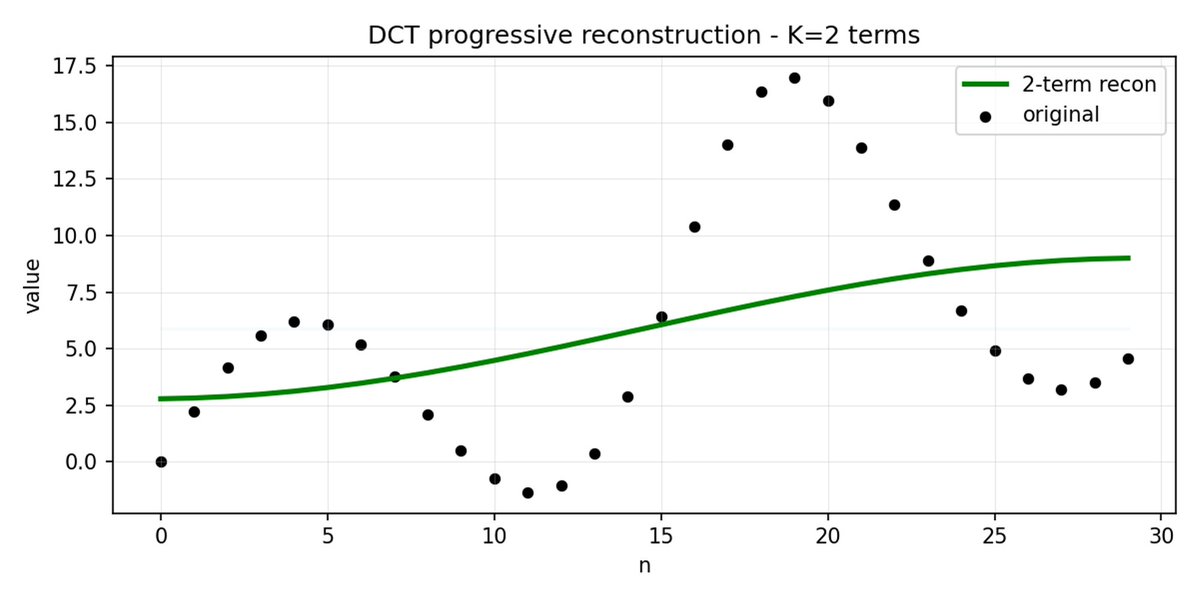
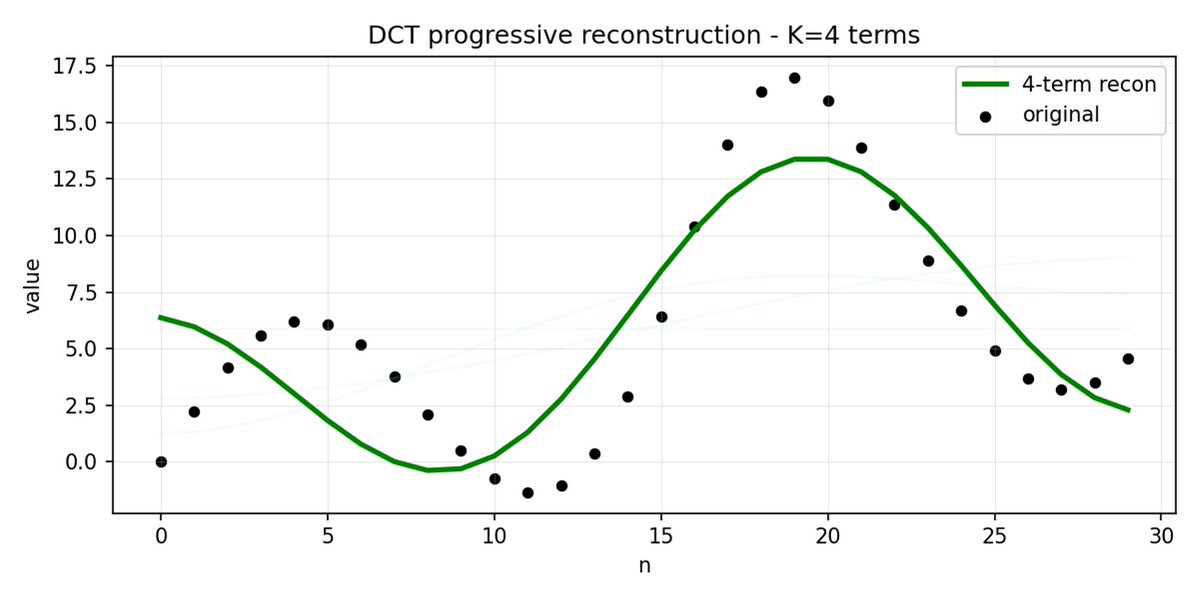
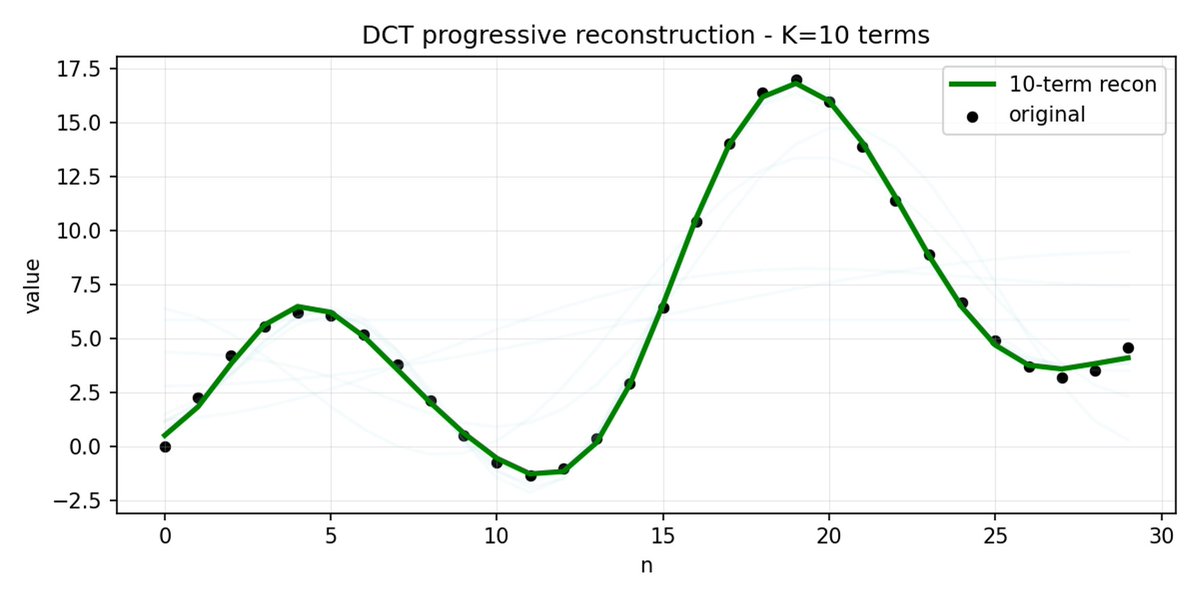
La codificación de pares de bytes (BPE) es el enfoque de tokenización más popular que se utiliza en LLM. Busca los pares de tokens más comunes y los fusiona en tokens únicos. Cuando se aplica sobre una DCT cuantificada, muchos coeficientes 0 de componentes de alta frecuencia, así como movimientos combinados comunes de diferentes articulaciones, se fusionan en tokens únicos, lo que genera una fuerte compresión.
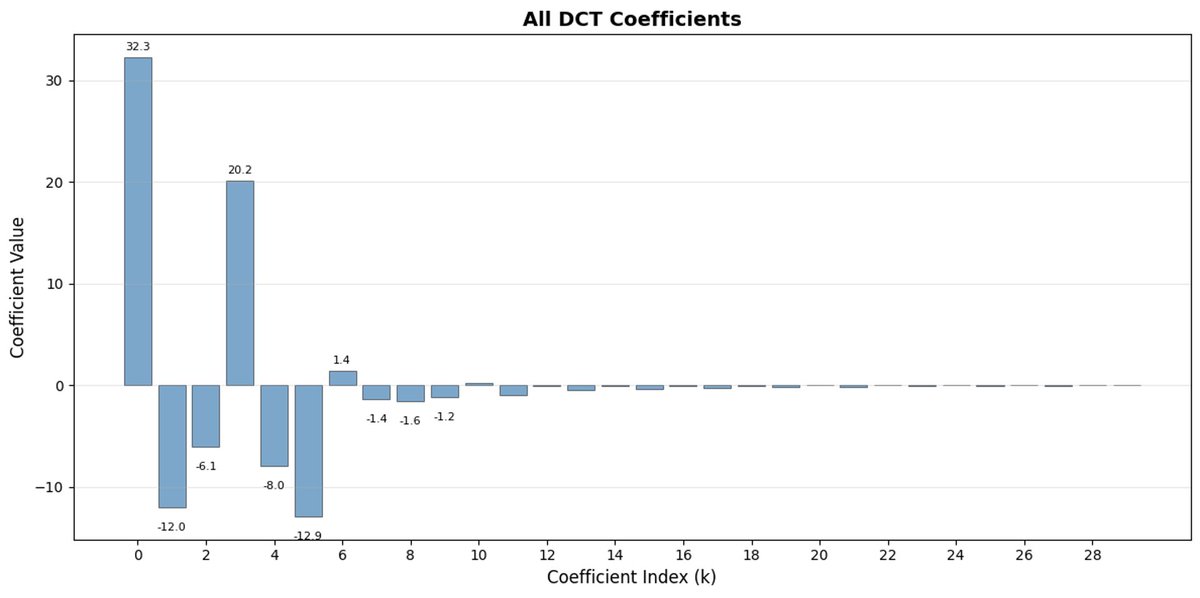
FAST puede comprimir deficientemente si sus acciones tienen ruido de alta frecuencia (como artefactos de normalización por paso de tiempo), los coeficientes dejan de ser cercanos a cero y la compresión se degrada. Los datos del robot real suelen ser fluidos, por lo que estará bien en la mayoría de los casos; solo tenga cuidado con el preprocesamiento de datos.
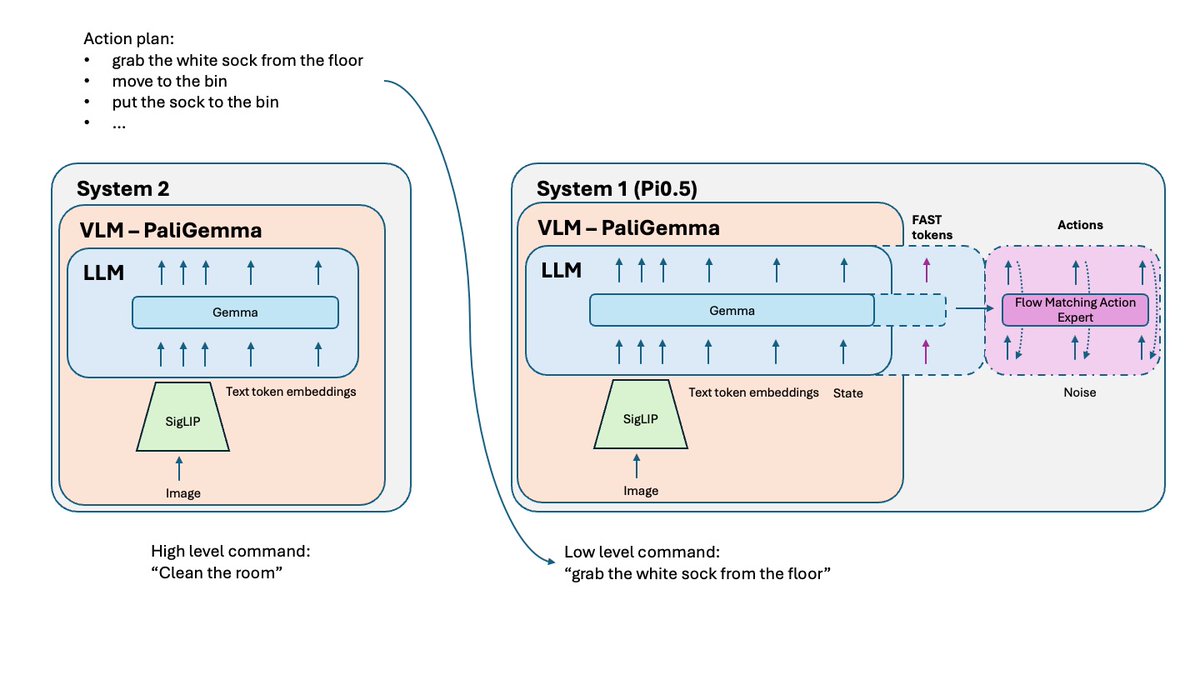
Las políticas de VLA entrenadas en tareas simples pueden tener dificultades para combinarlas en problemas complejos y de largo plazo. Para resolverlo, se utiliza el Sistema 2 de nivel superior. Pi0.5 utiliza el mismo VLM que el Sistema 1 (VLA), pero se invoca con mucha menor frecuencia para analizar el problema y definir el siguiente paso. Este se envía posteriormente al Sistema 1 para su ejecución.
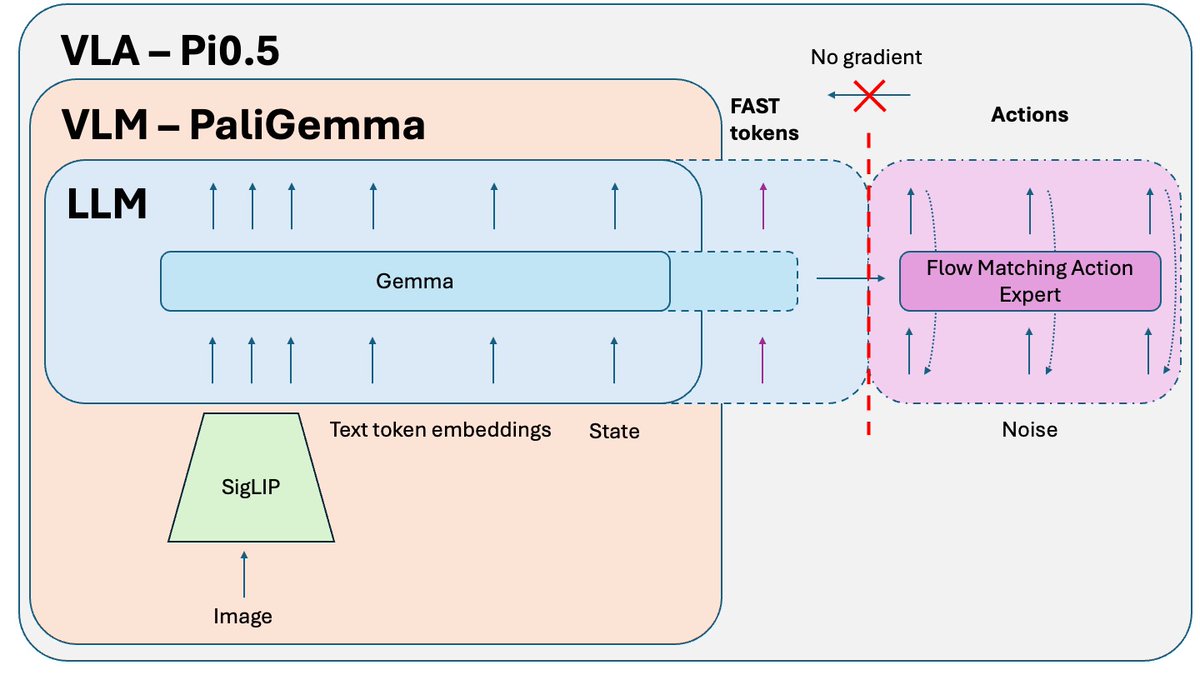
Un truco adicional que se publica después del artículo Pi0.5, pero que se utiliza para entrenar la versión de código abierto del modelo, es el aislamiento del conocimiento. Al entrenar conjuntamente la parte VLM (preentrenada con datos a escala de internet) y el experto en acciones (inicializado aleatoriamente), el gradiente ruidoso del experto en acciones corrompe el preentrenamiento del VLM. Simplemente, empieza a olvidar su conocimiento preentrenado. La solución es aislar el gradiente del experto en acciones y permitir que afecte solo los pesos del experto en acciones, mientras VLM se entrena con tokens de acción FAST + datos de no acción relevantes.
Otro problema durante la inferencia es que el movimiento no es suave debido a la fragmentación. El modelo predice el siguiente fragmento, lo ejecuta y luego hace una pausa para predecir el siguiente (video a continuación, velocidad x3). Si intenta predecir un fragmento antes de que se ejecute el anterior, puede producir errores fatales si el modelo salta a un nuevo modo de acción mientras ejecuta uno muy diferente. La solución es la restauración de la imagen, que se utiliza a menudo en la generación de imágenes. Podemos predecir el siguiente fragmento mientras se ejecuta el anterior, pero forzamos esta nueva predicción para que coincida exactamente con el final del fragmento anterior. El resultado es un movimiento mucho más suave, sin saltos ni pausas, y un mayor rendimiento y capacidad de procesamiento del modelo.
Si quieres profundizar en el tema (con imágenes, demostración e instrucciones de ajuste), mira mi nuevo vyoutu.be/QgGhK1LaUe8edJiDn