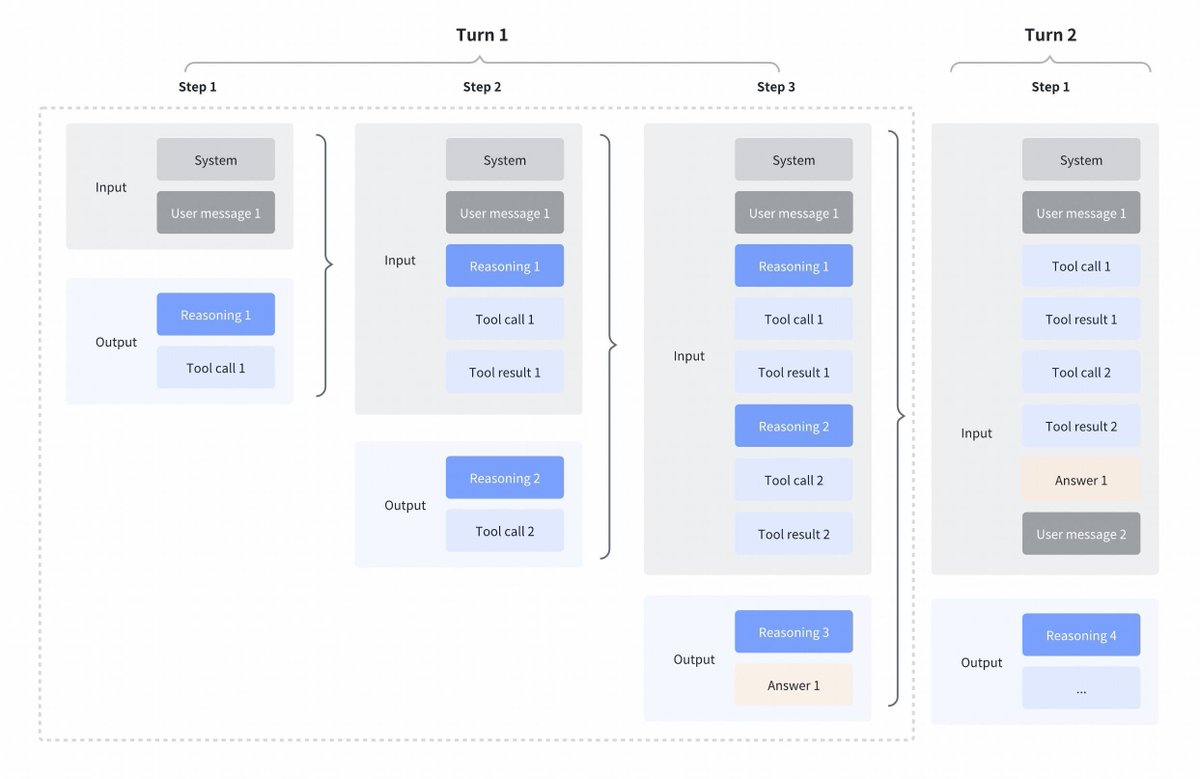
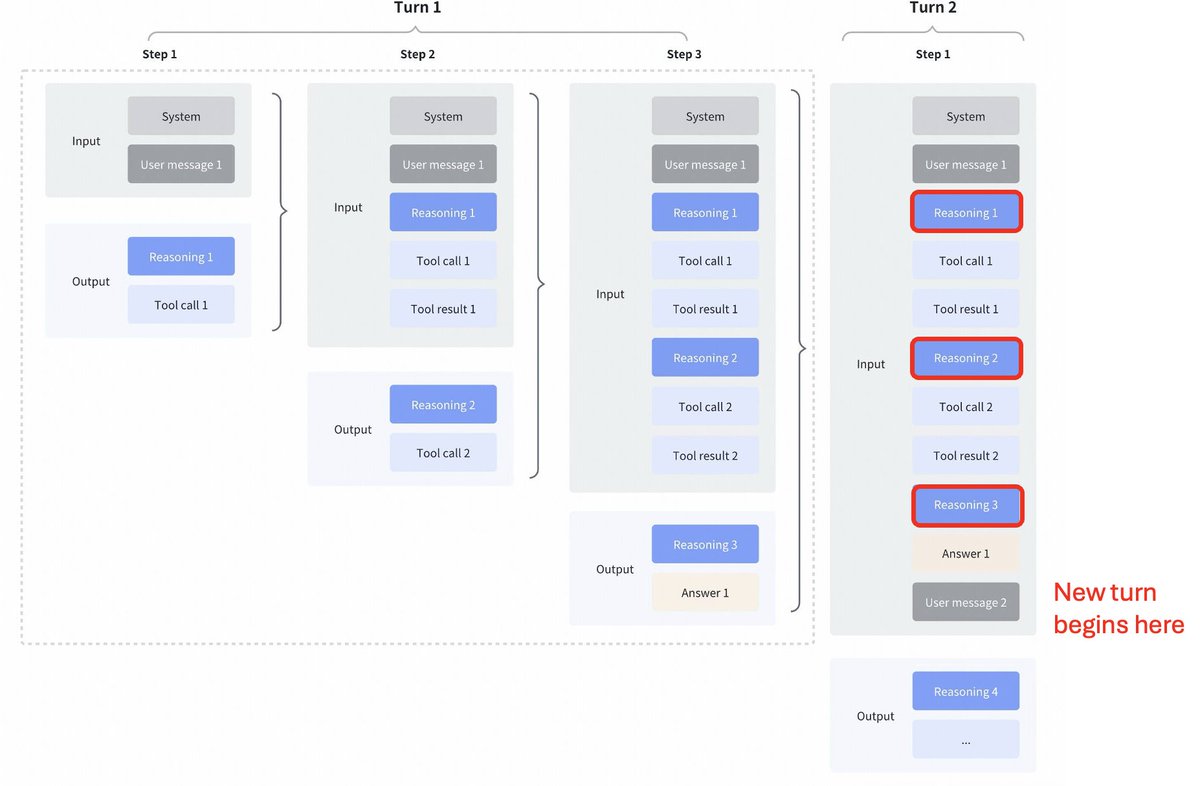
Interesante cambio de estrategia de GLM4.7 en comparación con Kimi K2 Thinking, DeepSeek V3.2 y MiniMax M2.1 Pensamiento intercalado entre llamadas de herramientas: Todos estos modelos admiten el pensamiento intercalado para las llamadas de herramientas, pero eliminan el pensamiento de los turnos anteriores como se puede ver en la primera captura de pantalla a continuación. Pensamiento preservado en GLM 4.7: En comparación con GLM 4.7 (solo para codificar puntos finales), se conserva el razonamiento de los turnos anteriores, como se puede ver en la captura de pantalla a continuación (observe los bloques rojos). Para el otro punto final de la API, el comportamiento es el mismo que antes (descarte el razonamiento de los turnos anteriores). Seguramente esto mejorará el rendimiento, ya que el modelo tendrá contexto pasado. Como aconseja @peakji, los modelos necesitan su proceso de pensamiento previo para tomar buenas decisiones posteriormente. Esto es una compresión anticontextual, pero supongo que para escenarios de codificación puede ser útil. Desearía que lo hicieran configurable, para que pudiéramos ver el impacto nosotros mismos.