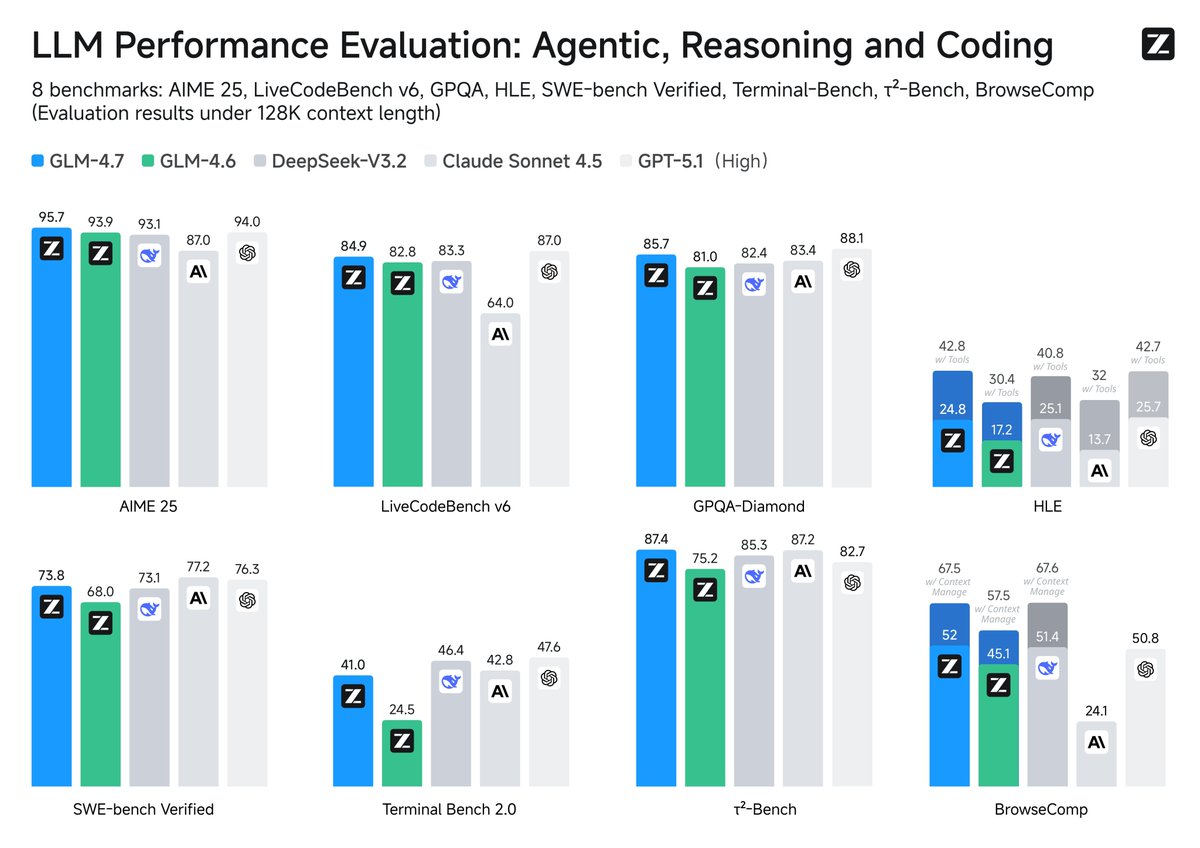
Zhipu acaba de publicar en código abierto su último modelo: GLM-4.7, cuyas capacidades de herramientas superan las de Claude Sonnet 4.5. Obtuvo una puntuación de 67,5 en la evaluación de tareas web de BrowseComp y de 87,4 en la evaluación de llamadas a herramientas interactivas de τ²-Bench, superando a Claude Sonnet por 4,5. Obtuvo un 42,8% en HLE, una mejora del 41% respecto a GLM-4.6 y superando a GPT-5.1. Super GPT-5.2 en Code Arena Las capacidades de GLM-4.7 se manifiestan en tres aspectos: programación, razonamiento y agentes inteligentes. En términos de habilidades de programación, incluido el front-end/back-end y el cumplimiento de instrucciones, el rendimiento mejoró significativamente en comparación con 4,6 en una prueba a ciegas de 100 tareas en un proyecto real. También mejora el rendimiento en la programación multilenguaje y en agentes inteligentes de borde, lo que permite "pensar antes de actuar" dentro de marcos de programación como Claude Code. La planificación de tareas a largo plazo y las llamadas estables a herramientas permiten un pensamiento implícito y almacenable en caché. Los requisitos complejos se desglosan automáticamente en pasos y se invocan búsquedas, terminales, sistemas de archivos y navegadores. Los errores se revierten. Alcanza una puntuación de 87,4 en τ²-Bench, lo que significa que las cadenas de herramientas de varios pasos rara vez fallan. El módulo Habilidades se ha lanzado en el modo de desarrollo full-stack z ai para respaldar la programación unificada de tareas multimodales. #ZhipuGLM47
GitHub:github.com/zai-org/GLM-4.5V Cara abrazahuggingface.co/zai-org/GLM-4.7U4ij modelscope.cn/models/ZhipuAI…/t.co/ELPQoNUXbc