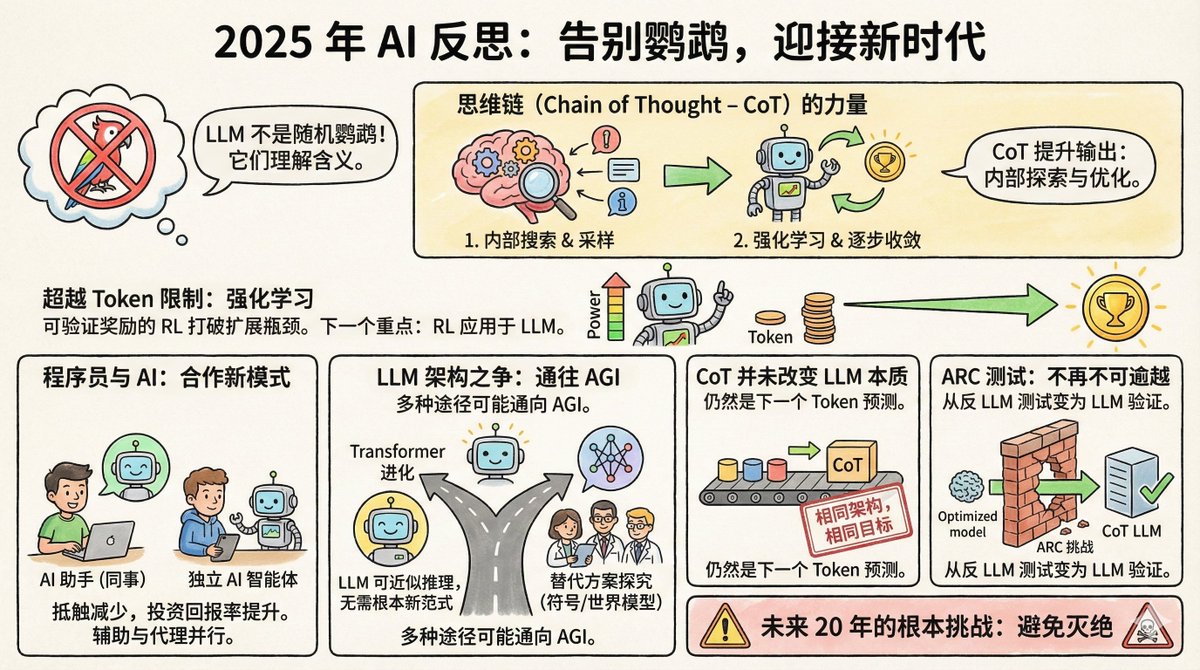
Salvatore Sanfilippo, el creador de Redis, publicó recientemente una reflexión de fin de año sobre IA, en la que destaca ocho puntos clave. Primero, un poco de contexto: Salvatore no se dedica al campo de la IA; es una leyenda en el mundo de la programación. En 2009, creó Redis, una base de datos que ahora es uno de los sistemas de almacenamiento en caché más populares del mundo. Se retiró de Redis en 2020 para dedicarse a sus propios proyectos. Regresó a Redis a finales de 2024, convirtiéndose también en un usuario intensivo de herramientas de IA; Claude es su compañero de programación. Esta identidad es bastante interesante: es al mismo tiempo un experto en tecnología y un usuario común de IA, lo que le otorga una perspectiva más realista que la de los investigadores puros de IA. En primer lugar, la afirmación sobre loros al azar finalmente está siendo desmentida. En 2021, los investigadores de Google Timnit Gebru y otros publicaron un artículo que denominó a los grandes modelos lingüísticos "loros aleatorios". Esto significa que estos modelos simplemente unen palabras probabilísticamente, sin comprender el significado de la pregunta ni saber qué dicen. La analogía es vívida y muy utilizada. Pero Salvatore afirma que para 2025, casi nadie la usará. ¿Por qué? Porque hay demasiada evidencia. Los modelos LLM superan a la gran mayoría de los humanos en exámenes de abogacía, exámenes médicos y competiciones de matemáticas. Más importante aún, los investigadores, mediante ingeniería inversa de estos modelos, han descubierto que efectivamente contienen representaciones internas de conceptos, no simplemente collages de palabras. Geoffrey Hinton lo expresó con toda claridad: para predecir con precisión la siguiente palabra, es necesario comprender la oración. Comprender no sustituye la predicción, sino que es una condición necesaria para hacer buenas predicciones. Por supuesto, si LLM realmente lo entiende es un debate filosófico. Pero en la práctica, ese debate ha terminado. II. La Cadena Mental es un avance subestimado La cadena de pensamiento consiste en que el modelo escriba su proceso de pensamiento antes de responder. Parece simple, pero el mecanismo subyacente es bastante profundo. Salvatore cree que hizo dos cosas: En primer lugar, permite al modelo muestrear sus representaciones internas antes de responder. En pocas palabras, recupera conceptos e información relevantes en el contexto de la pregunta y luego responde basándose en esa información. Esto es similar a que alguien planifique su examen en un borrador. En segundo lugar, al incorporar el aprendizaje por refuerzo, el modelo aprende a guiar su pensamiento paso a paso hacia la respuesta correcta. La salida de cada token cambia el estado del modelo, y el aprendizaje por refuerzo le ayuda a encontrar la ruta que converge hacia la respuesta correcta. No es nada misterioso, pero los efectos son sorprendentes. En tercer lugar, se ha superado el cuello de botella que impedía la expansión del poder computacional. Solía haber un consenso en la comunidad de IA: la mejora de las capacidades del modelo depende de la cantidad de datos de entrenamiento, pero la cantidad de texto producido por humanos es limitada, por lo que la expansión eventualmente se topará con un muro. Pero ahora, con el aprendizaje de refuerzo que ofrece recompensas verificables, las cosas han cambiado. ¿Qué son las recompensas verificables? Para algunas tareas, como optimizar la velocidad del programa o demostrar teoremas matemáticos, el modelo puede evaluar la calidad de los resultados por sí mismo. Un programa más rápido es mejor, y una demostración correcta es correcta; no se requiere anotación humana. Esto significa que el modelo puede mejorarse continuamente en este tipo de tareas, generando una cantidad casi infinita de señales de entrenamiento. Salvatore cree que esta será la dirección del próximo gran avance en IA. ¿Recuerdan el movimiento número 37 de AlphaGo? Nadie lo entendió en aquel momento, pero más tarde se demostró que era una jugada divina. Salvatore cree que LLM podría seguir un camino similar en ciertos campos. IV. La actitud de los programadores ha cambiado. Hace un año, la comunidad de programadores estaba dividida en dos bandos: unos creían que la programación asistida por IA era un arma mágica, y otros, que era solo un juguete. Ahora, los escépticos han cambiado de bando en gran medida. La razón es simple: el retorno de la inversión ha superado un punto crítico. Es cierto que el modelo puede cometer errores, pero el tiempo que ahorra supera con creces el coste de corregirlos. Curiosamente, los enfoques de los programadores hacia la IA se dividen en dos grupos: uno considera a LLM como un "colega", utilizándolo principalmente a través de interfaces web conversacionales. El propio Salvatore pertenece a este grupo, utilizando versiones web como Gemini y Claude para colaborar como si estuviera charlando con una persona experta. Otra escuela de pensamiento considera a LLM como una "inteligencia de codificación independiente y autónoma", que le permite escribir código, ejecutar pruebas y corregir errores por sí sola, mientras que los humanos son los principales responsables de la revisión. Estos dos usos se basan en filosofías diferentes: ¿tratas a la IA como un asistente o como un ejecutor? V. El Transformer podría ser el camino a seguir. Algunos científicos destacados en IA han comenzado a explorar arquitecturas más allá de Transformer, formando empresas para investigar representaciones simbólicas explícitas o modelos mundiales. Salvatore mantiene una postura abierta pero cautelosa al respecto. Cree que el LLM es esencialmente una aproximación al razonamiento discreto en un espacio diferenciable, y que no es imposible lograr la IAG sin un paradigma fundamentalmente nuevo. Además, la IAG puede implementarse de forma independiente mediante diversas arquitecturas completamente diferentes. En otras palabras, todos los caminos llevan a Roma. El Transformador puede no ser el único camino, pero tampoco es necesariamente un callejón sin salida. VI. La cadena de mentalidad no cambia la esencia del LLM. Algunas personas han cambiado de opinión. Antes decían que LLM era un loro cualquiera, pero ahora reconocen que LLM tiene la capacidad, pero también afirman que la cadena mental cambia fundamentalmente la naturaleza de LLM, por lo que las críticas anteriores siguen siendo válidas. Salvatore dijo directamente: Están mintiendo. La arquitectura sigue siendo la misma; sigue siendo un Transformador. El objetivo de entrenamiento sigue siendo el mismo: predecir el siguiente token. CoT también se genera token a token, lo cual no difiere de generar otro contenido. No se puede afirmar que el modelo "se ha convertido en algo diferente" solo porque se ha vuelto más potente para justificar un juicio erróneo. Es una afirmación bastante contundente, pero lógicamente sólida. Los juicios científicos deben basarse en mecanismos, y las definiciones no deben modificarse simplemente porque el resultado haya cambiado. Otro ejemplo que ilustra bien este punto es la prueba ARC. VII. Las pruebas ARC han pasado de ser anti-LLM a ser favorables a los LLM. ARC es una prueba diseñada por François Chollet en 2019 específicamente para medir la capacidad de razonamiento abstracto. Su diseño busca resistir la recuperación de memoria y las búsquedas forzadas, requiriendo un razonamiento genuino para su resolución. En aquel entonces, muchos creían que el LLM nunca superaría esta prueba. Esto se debía a que requiere la capacidad de generalizar reglas a partir de un número muy reducido de muestras y aplicarlas a nuevas situaciones, que es precisamente lo que un loro al azar no puede hacer. ¿El resultado? A finales de 2024, el o3 de OpenAI alcanzó una precisión del 75,7 % en ARC-AGI-1. En 2025, incluso en el más complejo ARC-AGI-2, los mejores modelos alcanzaron una precisión superior al 50 %. Esta inversión es bastante irónica. La prueba se diseñó originalmente para demostrar su ineficacia. Sin embargo, irónicamente, se ha convertido en evidencia que demuestra su eficacia. VIII. Desafíos fundamentales para los próximos 20 años El último punto es sólo una frase: el desafío fundamental para la IA en los próximos 20 años es evitar la extinción. No dio más detalles, solo esa frase. Pero ya saben a qué se refiere. Cuando la IA sea realmente lo suficientemente potente, «cómo garantizar que no cause problemas graves» ya no será ciencia ficción. Salvatore no es un ferviente creyente en la IA ni un escéptico. Es alguien que comprende la tecnología y la utiliza en la práctica. Su perspectiva no es puramente académica ni puramente comercial, sino la serena observación de un ingeniero experimentado. Su opinión principal es que los LLM son mucho más poderosos de lo que muchas personas están dispuestas a admitir, el aprendizaje de refuerzo está abriendo nuevas posibilidades y nuestra comprensión de estos sistemas aún está lejos de ser completa. Este es probablemente el verdadero estado del desarrollo de la IA en 2025: las capacidades se están acelerando, las controversias están disminuyendo, pero la incertidumbre sigue siendo enorme.