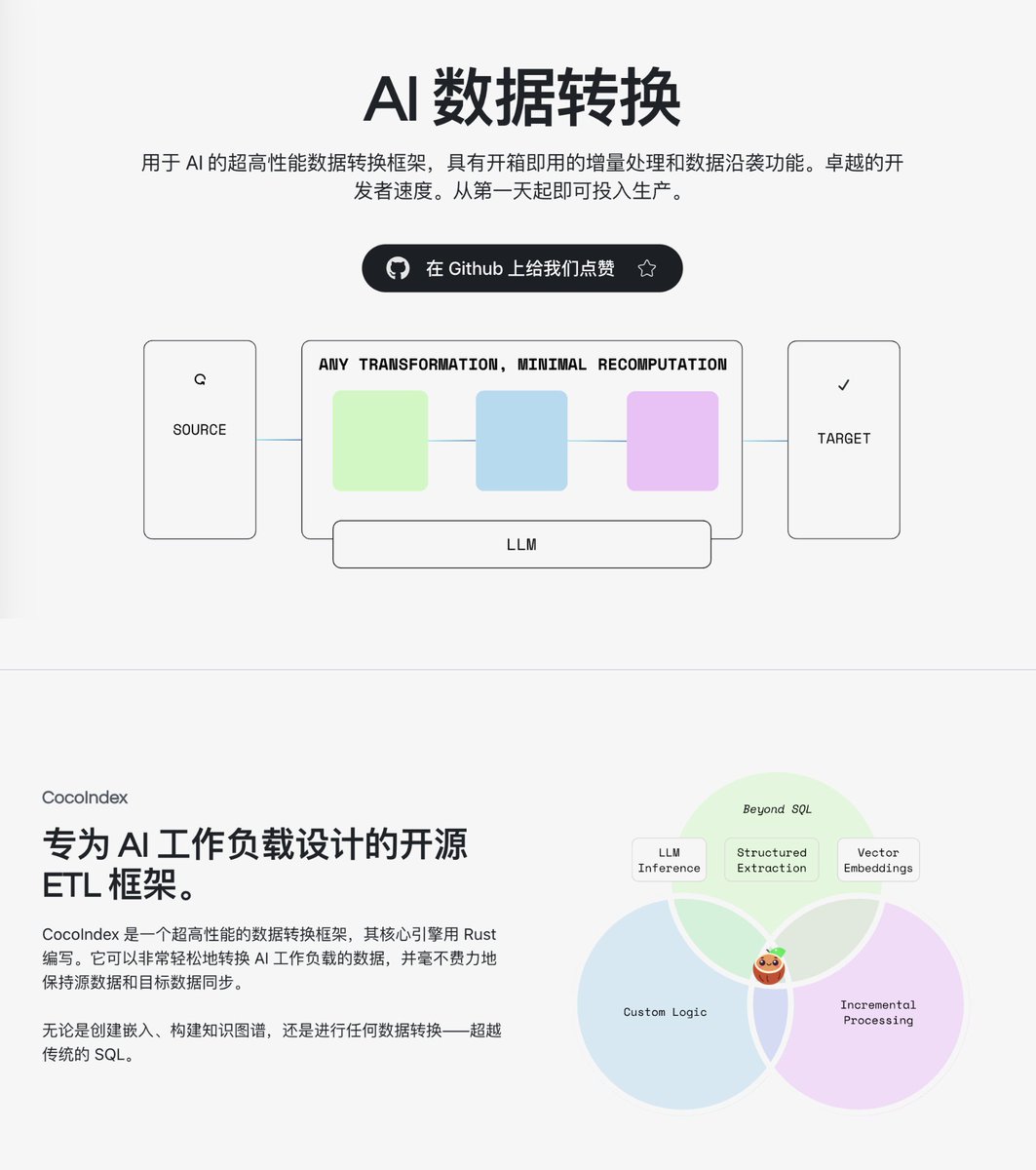
Al desarrollar aplicaciones RAG o construir bases de conocimiento, la parte más problemática a menudo no es la selección del modelo, sino el proceso de procesamiento de datos. Es necesario escribir una serie de scripts en Python para limpiar, segmentar y vectorizar los datos y, si los datos de origen cambian, volver a ejecutar todo el proceso es una tarea costosa y que consume mucho tiempo. Recientemente me encontré con el proyecto de código abierto CocoIndex en GitHub, un marco de transformación de datos de alto rendimiento diseñado específicamente para escenarios de IA. Con apenas 100 líneas de código Python, puedes definir todo el proceso, desde la lectura y fragmentación del archivo hasta la inserción del vector en la biblioteca. GitHub: https://t.co/RwUjyHJEym Admite una variedad de fuentes y destinos de datos, incluidos archivos locales, Amazon S3, Google Drive y bases de datos vectoriales como Postgres, Qdrant y LanceDB. Además, también incluye componentes de conversión de uso común, como segmentación de texto, generación de incrustaciones, análisis de PDF y construcción de gráficos de conocimiento. Proporciona una gran cantidad de ejemplos que cubren más de 20 escenarios de aplicaciones prácticas, incluida la búsqueda semántica, los gráficos de conocimiento, la recomendación de productos y la búsqueda de imágenes, a los que se puede hacer referencia y utilizar directamente.