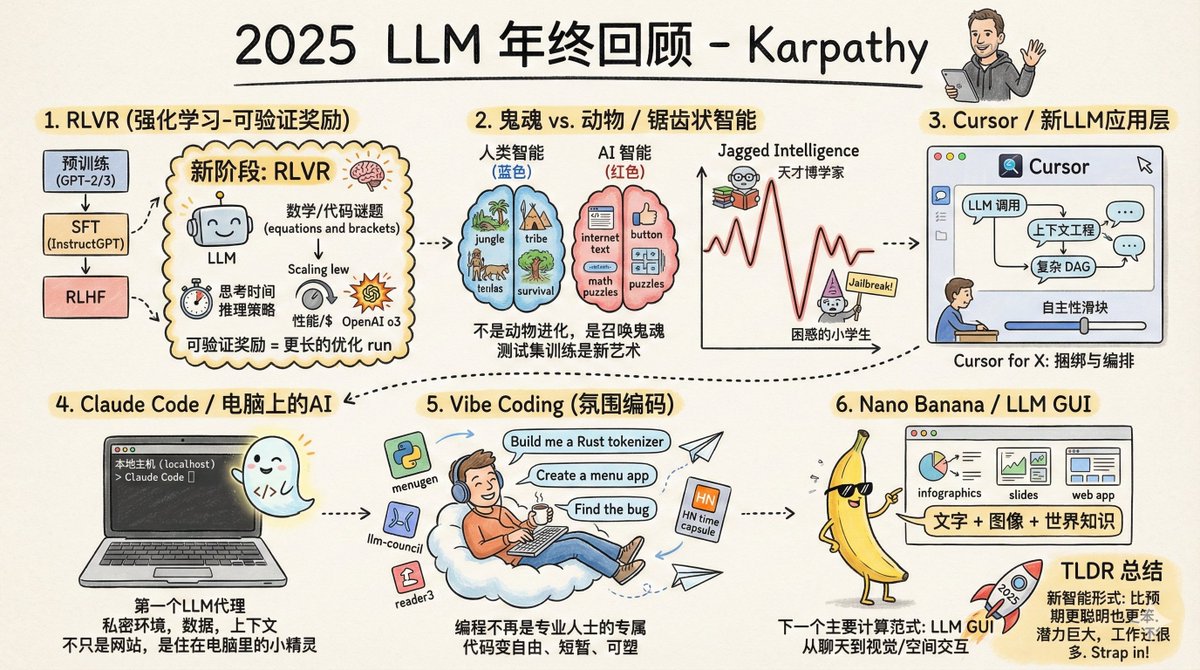
Andrej Karpathy, cofundador de OpenAI, ex director de IA en Tesla y uno de los investigadores de IA más influyentes del mundo, acaba de publicar una revisión de fin de año del LLM 2025. El primer gran cambio: un cambio de paradigma en los métodos de entrenamiento. Antes de 2025, el entrenamiento de un modelo grande utilizable implicaba básicamente tres pasos: preentrenamiento, ajuste fino supervisado y aprendizaje de refuerzo con retroalimentación humana. Esta fórmula se utiliza desde 2020 y se mantiene estable y fiable. En 2025 se añadió un cuarto paso crucial: RLVR, que significa Aprendizaje por Refuerzo a Partir de Recompensas Verificables. ¿Qué significa esto? En pocas palabras, significa permitir que el modelo practique repetidamente en un entorno con "respuestas estándar". Por ejemplo, en los problemas de matemáticas, la respuesta es correcta o incorrecta; no es necesario que la persona la califique. Lo mismo aplica al código: si funciona, funciona. ¿Cuál es la diferencia fundamental entre este entrenamiento y el anterior? El ajuste supervisado previo y la retroalimentación humana consistían básicamente en "copiar el modelo", donde el modelo aprendía las muestras proporcionadas por el humano. Pero el RLVR es diferente; permite al modelo descubrir sus propias estrategias de resolución de problemas. Es como aprender a nadar: antes, veías videos instructivos e imitabas los movimientos; ahora, simplemente te lanzan al agua; mientras puedas nadar hasta el otro lado, no importa cómo remes. ¿El resultado? El modelo "descubrió" algo similar a razonar por sí solo. Aprendió a descomponer los grandes problemas en pasos más pequeños y a volver atrás y empezar de nuevo cuando se desviaba. Estas estrategias no pueden ser demostradas por humanos, porque ni siquiera ellos pueden explicar con claridad cómo es el "proceso de pensamiento correcto". Este cambio ha desencadenado una reacción en cadena: la forma en que se asigna la potencia de cálculo ha cambiado. Anteriormente, la mayor parte de la potencia de cálculo se destinaba a la etapa de preentrenamiento, pero ahora se utiliza cada vez más en la etapa de aprendizaje automático (RL). El tamaño de los parámetros del modelo no ha aumentado mucho, pero su capacidad de inferencia se ha disparado. El o1 de OpenAI fue el punto de partida de este camino, y el o3 fue el punto de inflexión que realmente hizo que la gente sintiera la diferencia. Existe otro enfoque nuevo: también puede consumir más potencia de cálculo durante la inferencia. Al hacer que el modelo "piense más" se generan cadenas de inferencia más largas, lo que resulta en un mejor rendimiento. Esto consiste básicamente en añadir un control de ajuste para controlar sus capacidades. El segundo gran cambio: finalmente entendemos qué es lo que “da forma” a la inteligencia de la IA. Karpathy utilizó una analogía brillante: no estamos "criando animales", estamos "invocando fantasmas". La inteligencia humana evoluciona, y su objetivo de optimización es "ayudar a la tribu a sobrevivir en la selva". La inteligencia de los modelos grandes se entrena, y su objetivo de optimización es "imitar texto humano, obtener puntos en problemas matemáticos y acumular puntuaciones en las listas de referencia". Los objetivos de optimización son completamente diferentes, por lo que los resultados naturalmente también serán completamente diferentes. Por lo tanto, la inteligencia de la IA es "inteligencia irregular". Puede comportarse como un erudito omnisciente en algunos campos, mientras que en otros comete errores que ni siquiera un estudiante de primaria cometería. En un instante te ayuda a derivar fórmulas complejas, y al siguiente se deja engañar para que te entregue datos mediante una simple pista de jailbreak. ¿A qué se debe esto? Porque en áreas con "recompensas verificables", los modelos desarrollarán "picos" en esas áreas. Las matemáticas tienen respuestas estándar y el código se puede probar, por lo que el progreso en estas áreas es rápido. Pero en áreas como el sentido común, la interacción social y la creatividad, es difícil definir qué es "correcto", lo que dificulta que los modelos aprendan eficientemente. Esto también hizo que Karpathy perdiera la fe en los benchmarks. La razón es simple: las preguntas del examen en sí mismas son "entornos verificables" y el modelo puede optimizarse para estos entornos. Dominar los benchmarks se convirtió en un arte. Es perfectamente posible alcanzar el máximo rendimiento en todos los benchmarks y aun así quedar muy lejos de la verdadera inteligencia general. El tercer gran cambio: surge la capa de aplicación LLM. Cursor se ha vuelto increíblemente popular este año, pero Karpathy cree que su mayor importancia no radica en el producto en sí, sino en demostrar la existencia de una nueva especie: "aplicaciones LLM". El surgimiento de debates sobre los "cursores en el dominio X" indica la formación de un nuevo paradigma de software. ¿Qué harán estas aplicaciones? Primero, realice la ingeniería de contexto. Organice la información relevante e introdúzcala en el modelo. En segundo lugar, organice múltiples llamadas al modelo. El backend puede estar gestionando varias llamadas a la API; equilibre el rendimiento y el coste. En tercer lugar, proporcionar interfaces para escenarios especializados, que permitan a los humanos intervenir en puntos clave. En cuarto lugar, ofrece a los usuarios un control deslizante de grado de autonomía. Puedes ajustarlo en mayor o menor medida. Una pregunta se ha debatido durante todo un año: ¿Qué tan "gruesa" es esta capa de aplicación? ¿Los proveedores de modelos absorberán todas las aplicaciones? La evaluación de Karpathy es que los fabricantes de modelos forman a "graduados universitarios con habilidades generales", pero las solicitudes de maestría en derecho (LLM) son responsables de organizar, capacitar y colocar a estos graduados en puestos de trabajo, convirtiéndolos en equipos profesionales capaces de trabajar en industrias específicas. Datos, sensores, actuadores, bucles de retroalimentación: todas estas son tareas de la capa de aplicación. El cuarto gran cambio: la IA se ha instalado en tu ordenador. Claude Code es uno de los productos que más impresionó a Karpathy este año. Demuestra cómo debería ser un "agente de IA": capaz de invocar herramientas, realizar inferencias, ejecutar bucles y resolver problemas complejos. Pero lo más importante es que se ejecuta en tu ordenador. Utiliza tu entorno, tus datos y tu contexto. Karpathy cree que OpenAI calculó mal la situación. Centraron a Codex y a los agentes en los contenedores en la nube, programándolos desde ChatGPT. Parece que buscan el objetivo final de la IA general, pero aún no lo hemos logrado. La realidad es que las capacidades de la IA varían considerablemente, y los humanos aún necesitan supervisarlas y asistirlas. Colocar agentes inteligentes localmente, trabajando junto con los desarrolladores, es el enfoque más sensato actualmente. Claude Code logra esto con una interfaz de línea de comandos minimalista. La IA ya no es solo un sitio web que visitas, sino un pequeño sprite que "vive" en tu computadora. Este es un paradigma completamente nuevo de interacción humano-computadora. El quinto gran cambio: Vibe Coding ha despegado. En 2025, las capacidades de la IA traspasaron un umbral: podías describir tus necesidades solo en inglés y dejar que escribiera el programa por ti, sin preocuparte por la apariencia del código. Karpathy tuiteó casualmente sobre este estilo de programación, llamándolo "codificación de vibración", y el término se volvió viral. ¿Qué significa esto? La programación ya no es dominio exclusivo de los programadores profesionales; la gente común también puede hacerlo. Esto es diferente a cualquier modelo de difusión tecnológica anterior. En el pasado, las nuevas tecnologías siempre eran dominadas primero por grandes empresas, gobiernos y profesionales antes de extenderse gradualmente a otros sectores. Pero el modelo se ha invertido, y la gente común se beneficia mucho más que los profesionales. No se trata solo de "permitir que quienes no saben programar programen". Para quienes saben programar, muchos pequeños programas que antes no merecían la pena escribir ahora sí lo merecen. El propio Karpathy ha realizado numerosos proyectos con Vibe Coding: creó un tokenizador personalizado en Rust, creó varias aplicaciones de utilidad e incluso escribió un programa único solo para encontrar un error. El código se vuelve repentinamente barato, desechable y se puede escribir con la misma naturalidad que en un papel borrador. Esto cambiará por completo la forma del software y el trabajo de los programadores. El sexto gran cambio: se acerca la «era de la interfaz gráfica» para modelos a gran escala. Gemini Nano Banana de Google es uno de los productos más subestimados del año. Puede generar imágenes, infografías y animaciones en tiempo real basándose en el contenido de las conversaciones, "dibujando" en lugar de "escribir" las respuestas. Karpathy sitúa esto dentro de un contexto histórico más amplio: los modelos grandes representan el próximo gran paradigma informático, al igual que las computadoras en las décadas de 1970 y 1980. Por lo tanto, veremos un camino evolutivo similar. Chatear con modelos grandes ahora es como escribir comandos en una terminal en los años 80. El texto es un formato que prefieren las máquinas, pero no los humanos. A los humanos no les gusta leer texto; es lento y cansado. Prefieren ver imágenes, vídeos y diseños espaciales. Por eso las computadoras tradicionales inventaron las interfaces gráficas. Los modelos grandes también necesitan su propia interfaz gráfica de usuario (GUI). Debería comunicarse con nosotros de la forma que nos guste: imágenes, diapositivas, pizarras, animaciones, miniaplicaciones. Los emojis y Markdown actuales son solo formas rudimentarias, simplemente "adornan" el texto. ¿Cómo será una verdadera GUI de LLM? Nano Banana es un primer indicio. Lo más interesante es que no se trata solo de generar imágenes. Requiere entrelazar la generación de texto, la generación de imágenes y el conocimiento del mundo, integrándolos todos en los pesos del modelo. La conclusión de Karpathy es la siguiente: el gran modelo de 2025 es a la vez más inteligente y más tonto de lo que esperaba. Ambas son ciertas simultáneamente. Pero una cosa es segura: incluso con nuestras capacidades actuales, ni siquiera hemos alcanzado el 10% de nuestro potencial. Aún quedan muchísimas ideas por probar; todo el campo parece estar abierto. Dijo algo aparentemente contradictorio en el podcast de Dwarkesh: Él cree que el progreso continuará a un ritmo rápido. > Al mismo tiempo, creo que todavía queda mucho trabajo por hacer. Estas dos cosas no son contradictorias. Abróchense los cinturones y sigan acelerando en 2026.