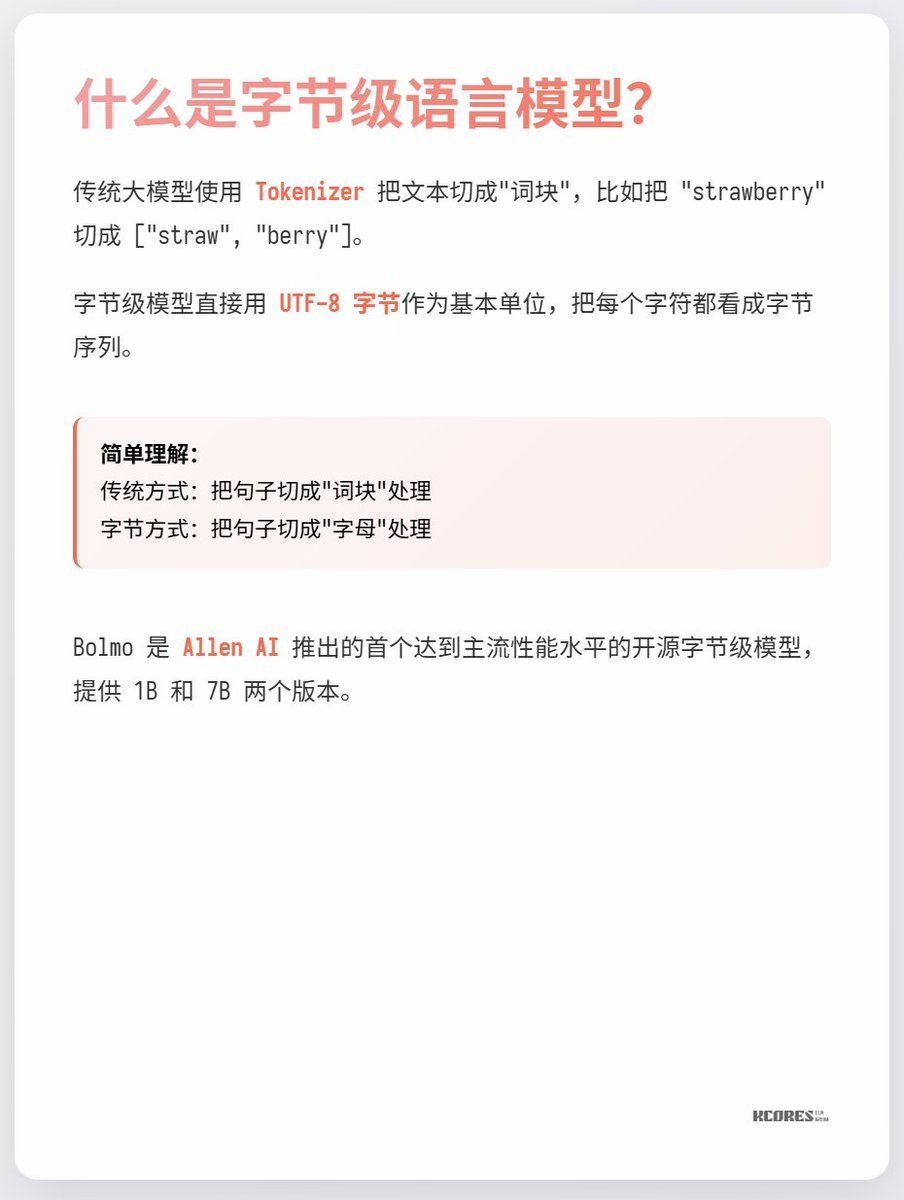
Todos sabemos que los modelos a gran escala cuentan con un tokenizador, que registra las tablas de segmentación de palabras que utiliza el modelo y es la unidad mínima para comprender la semántica y realizar cálculos. Pero ¿se ha preguntado alguna vez por qué necesitamos la segmentación de palabras? ¿No sería mejor introducir directamente los tokens mediante codificación UTF-8? Analicemos el nuevo modelo actual, Bolmo-8B. Abandonaron directamente el enfoque tradicional y, en su lugar, utilizaron bytes UTF-8 como unidad básica, tratando cada carácter como una secuencia de bytes para su procesamiento.
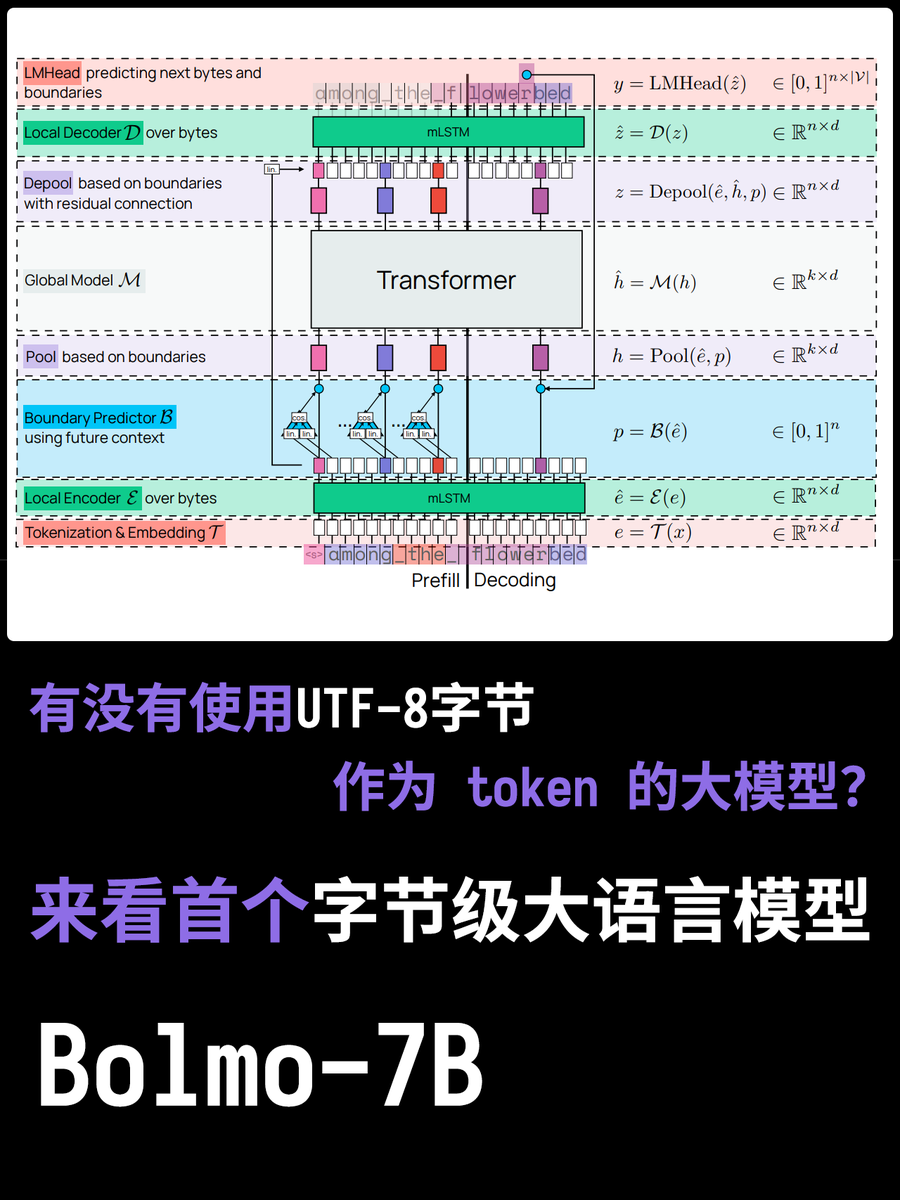
La mayor ventaja de esto es que preguntas como "¿Cuántas erres tiene Strawberry?" se pueden responder fácilmente. Esto se debe a que cada letra está codificada en UTF-8 de forma independiente. Sin embargo, los problemas que esto conlleva son muy reales. A veces, una palabra puede ser muy compleja, mientras que otras veces puede ser muy simple. Los tokenizadores tradicionales pueden compensar este problema en distintos grados, pero al usar UTF-8, cada palabra debe consumir un token de su longitud, lo que hace que la asignación de recursos computacionales sea muy inflexible.



El modelo de Bolmo adopta un enfoque inteligente: en lugar de entrenar desde cero, codifica en bytes el modelo existente. Incorpora un codificador/decodificador local que comprime las secuencias de bytes en posibles tokens antes de introducirlos en un transformador tradicional para su procesamiento. Esto permite una conversión con una sobrecarga mínima.

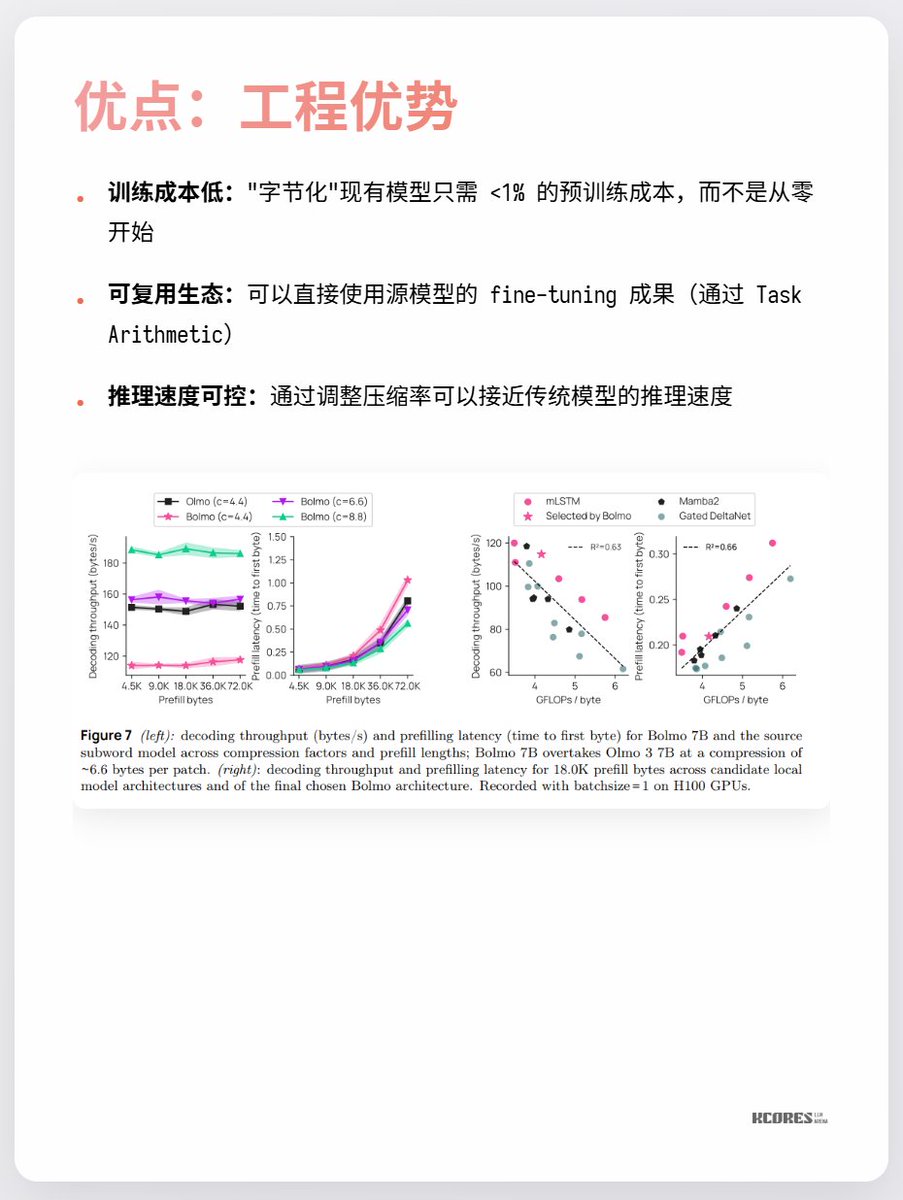

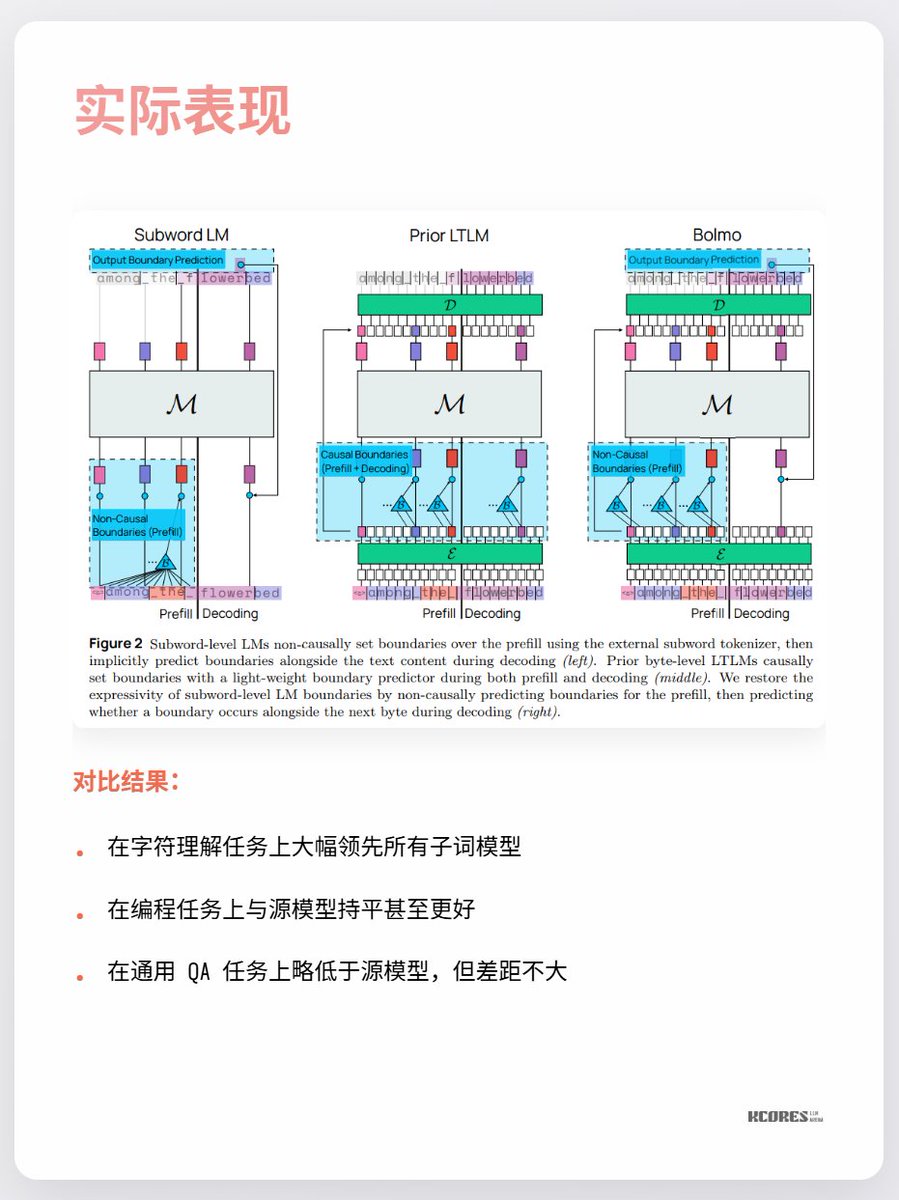
Los principales puntos de controversia actualmente son que no se observan grandes beneficios y que las secuencias más largas implican más caché clave-valor, lo que ejerce mayor presión sobre la memoria de la GPU. Además, la ventaja significativa solo se observa en la tarea de comprensión de caracteres, con escasas mejoras notables en otras tareas. En resumen, vale la pena seguirlo. La exploración de espirales durante periodos de avances tecnológicos siempre es muy interesante. Por ejemplo, a mí personalmente me gustaban los rectificadores de mercurio (última imagen), pero ahora han sido reemplazados por los IGBT.

