NVIDIA acaba de lanzar un modelo acelerado diseñado específicamente para GPT-OSS-120B. NVIDIA acaba de lanzar un nuevo modelo, gpt-oss-120b-Eagle3-throughput, diseñado específicamente para funcionar con gpt-oss-120b. Puede utilizarse como premodelo para la decodificación especulativa de gpt-oss-120b, mejorando así la velocidad de salida del modelo. Para quienes no estén familiarizados con la decodificación especulativa, esta implica usar un modelo pequeño para generar datos y luego alimentar estos resultados en lotes a un modelo más grande para su corrección. De esta manera, si el modelo pequeño acierta, la velocidad es muy rápida. Además, en contextos normales, aún hay muchas palabras vacías (palabras con una frecuencia extremadamente alta en el lenguaje, pero que contribuyen muy poco a distinguir la semántica central de una oración). Por lo tanto, la mejora de la velocidad es significativa.

Información del modelo / 1




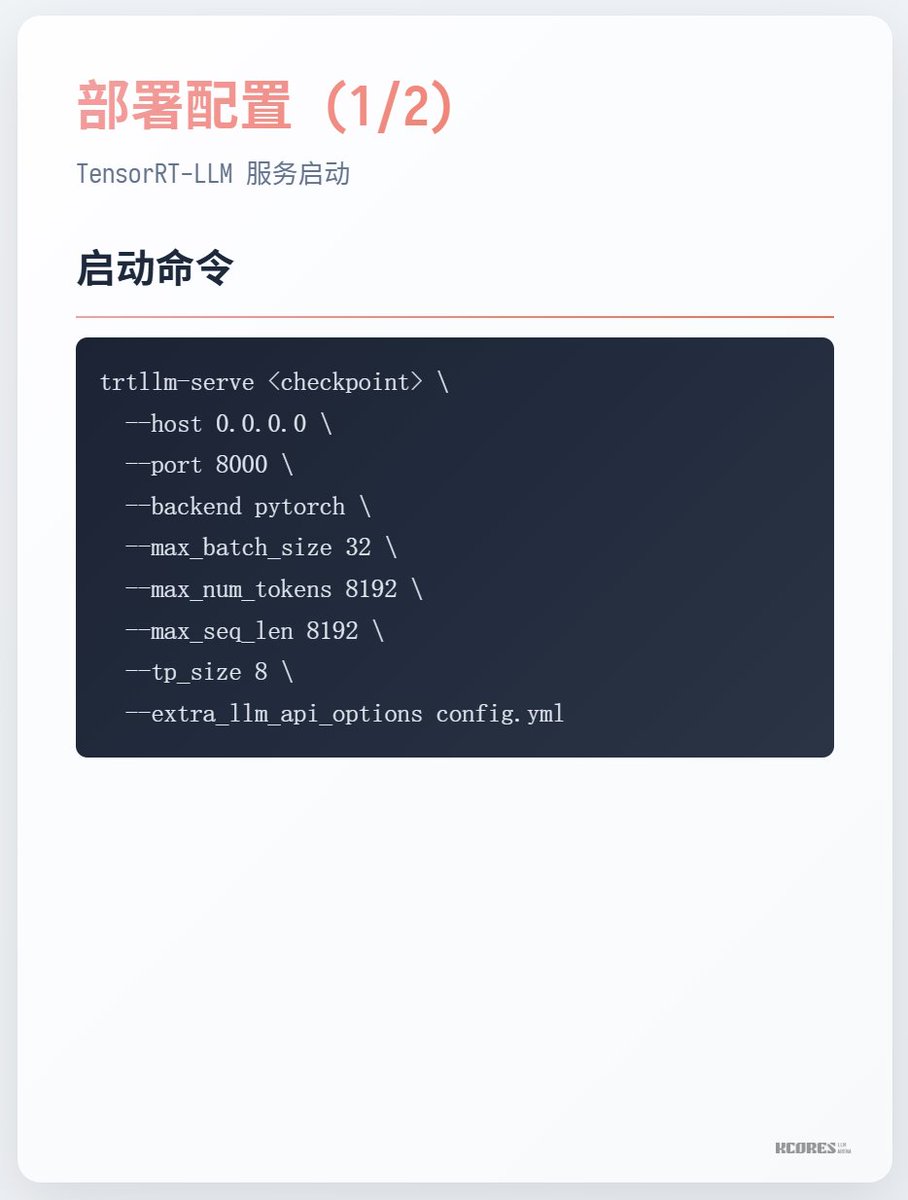
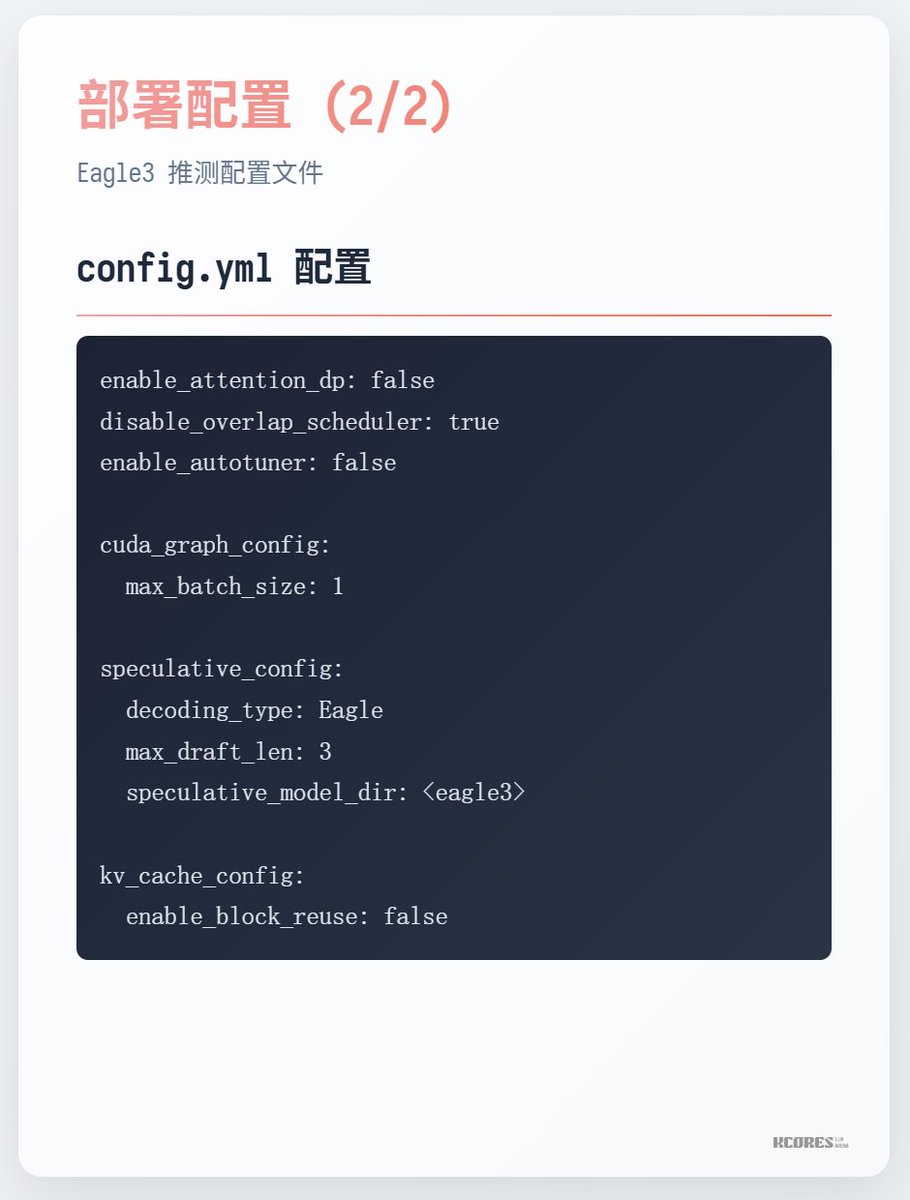
Cómo correr