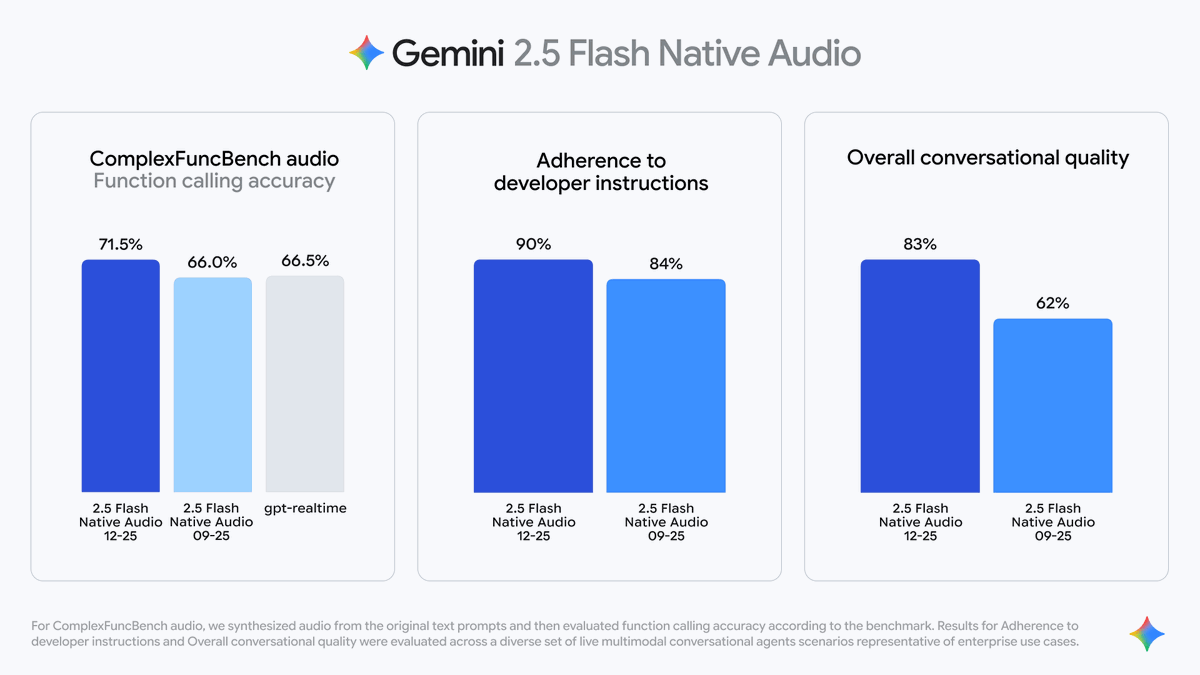
Google lanza el nuevo modelo Gemini 2.5 Flash Native Audio Se utiliza para controlar varias aplicaciones de voz en tiempo real. "Audio nativo" se refiere a la capacidad del modelo de generar directamente una salida de voz natural, en lugar de generar texto primero y luego sintetizar la voz. No sólo "entiende lo que dices", sino que también "puede responder inmediatamente con voz humana", con un tono, ritmo y pausas más naturales. Se han mejorado de forma integral las tres capacidades principales: 1️⃣ "Llamadas a funciones" más inteligentes Gemini ahora puede acceder de forma proactiva a fuentes de información externas durante conversaciones de voz, como: Llamar a la API meteorológica; Consultar la base de datos; Obtenga noticias o información bursátil en tiempo real. No solo "responde", sino que puede determinar cuándo buscar información y cuándo continuar la conversación durante el diálogo, y puede "buscar información mientras habla" para mantener un flujo de audio fluido.
2️⃣ Comprensión mejorada de las instrucciones El audio nativo de Gemini 2.5 Flash es más preciso al comprender instrucciones habladas complejas. Los datos de pruebas de Google muestran lo siguiente: La tasa de cumplimiento de las instrucciones aumentó del 84% al 90%; Se ha mejorado significativamente la integridad y precisión del contenido de salida. 3️⃣ Mejora la fluidez de la conversación Gemini 2.5 Flash Native Audio puede recordar el contexto de múltiples conversaciones, haciendo que las transiciones de voz sean más naturales.
El modelo de audio nativo Flash Gemini 2.5 ahora está completamente disponible en Verxiaohu.ai/c/xiaohu-ai/go…de usar en la API de Gemini (versión preliminar). Detalles: https://t.co/CnBlan3RBh