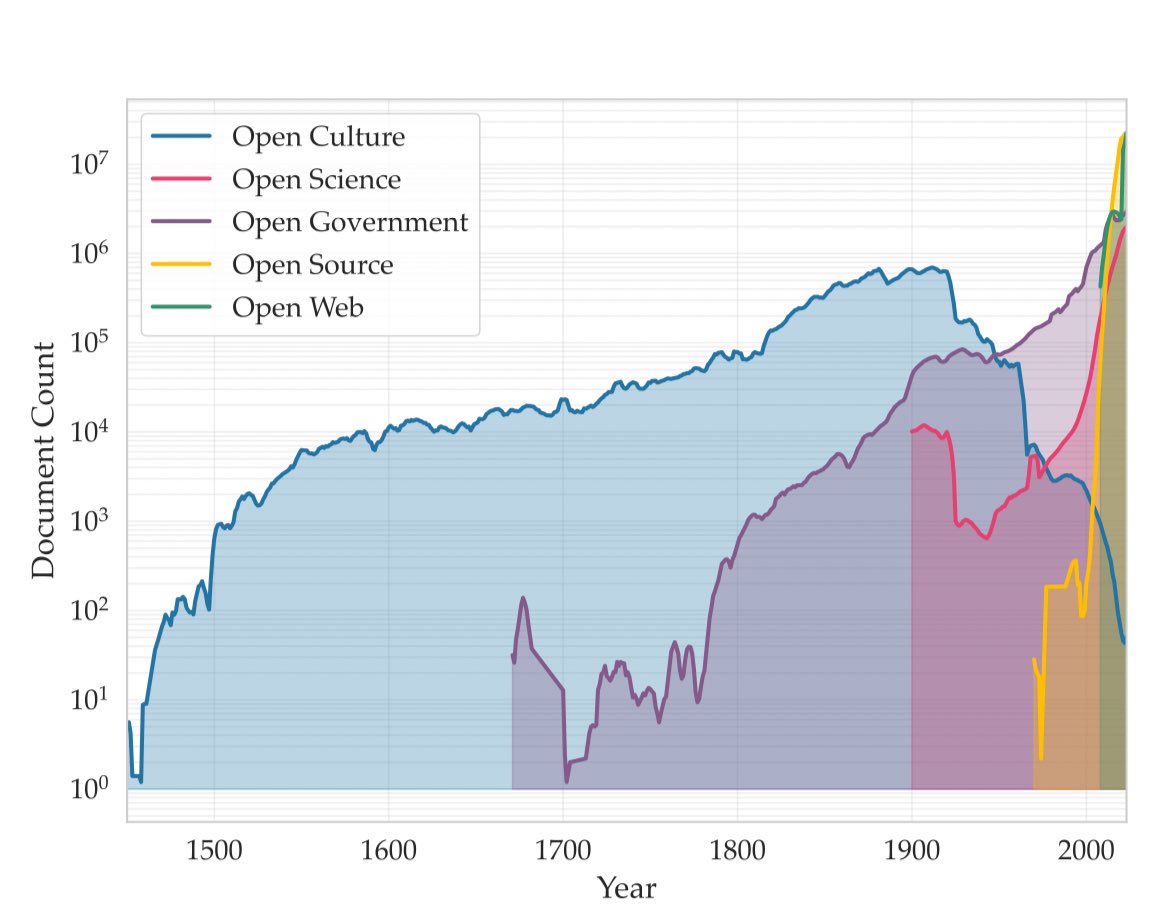
Recordatorio que Common Corpus tiene el conjunto de datos más grande disponible para este tipo de proyecto: alrededor de 900 mil millones de tokens antes de 1950.
Cargando el detalle del hilo
Obteniendo los tweets originales de X para ofrecer una lectura limpia.
Esto suele tardar solo unos segundos.
1 tweet · 12 dic 2025, 17:35
Recordatorio que Common Corpus tiene el conjunto de datos más grande disponible para este tipo de proyecto: alrededor de 900 mil millones de tokens antes de 1950.