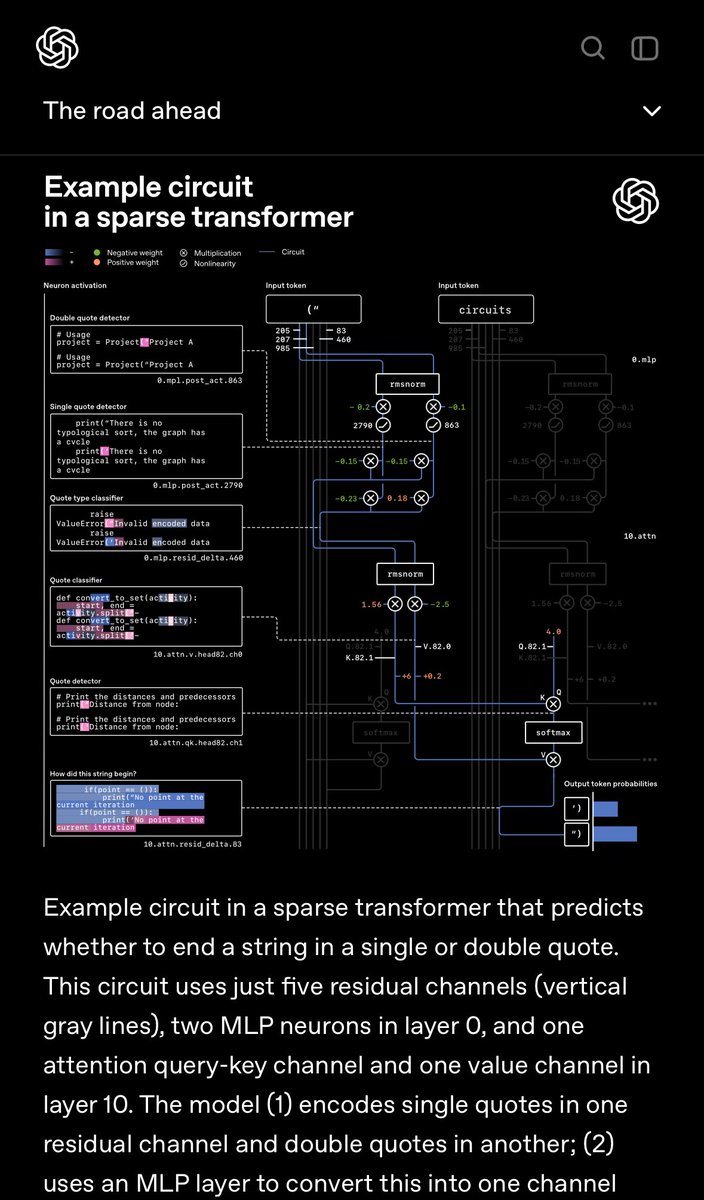
Un regalo excepcional e interesante de OpenAI. En principio, los modelos de activación dispersa con grandes dimensiones nominales son preferibles a los modelos de estructura de objetos (MOE) con sus expertos aislados de baja capacidad. Aunque la comunicación entre expertos entre capas podría ser otra vía viable.