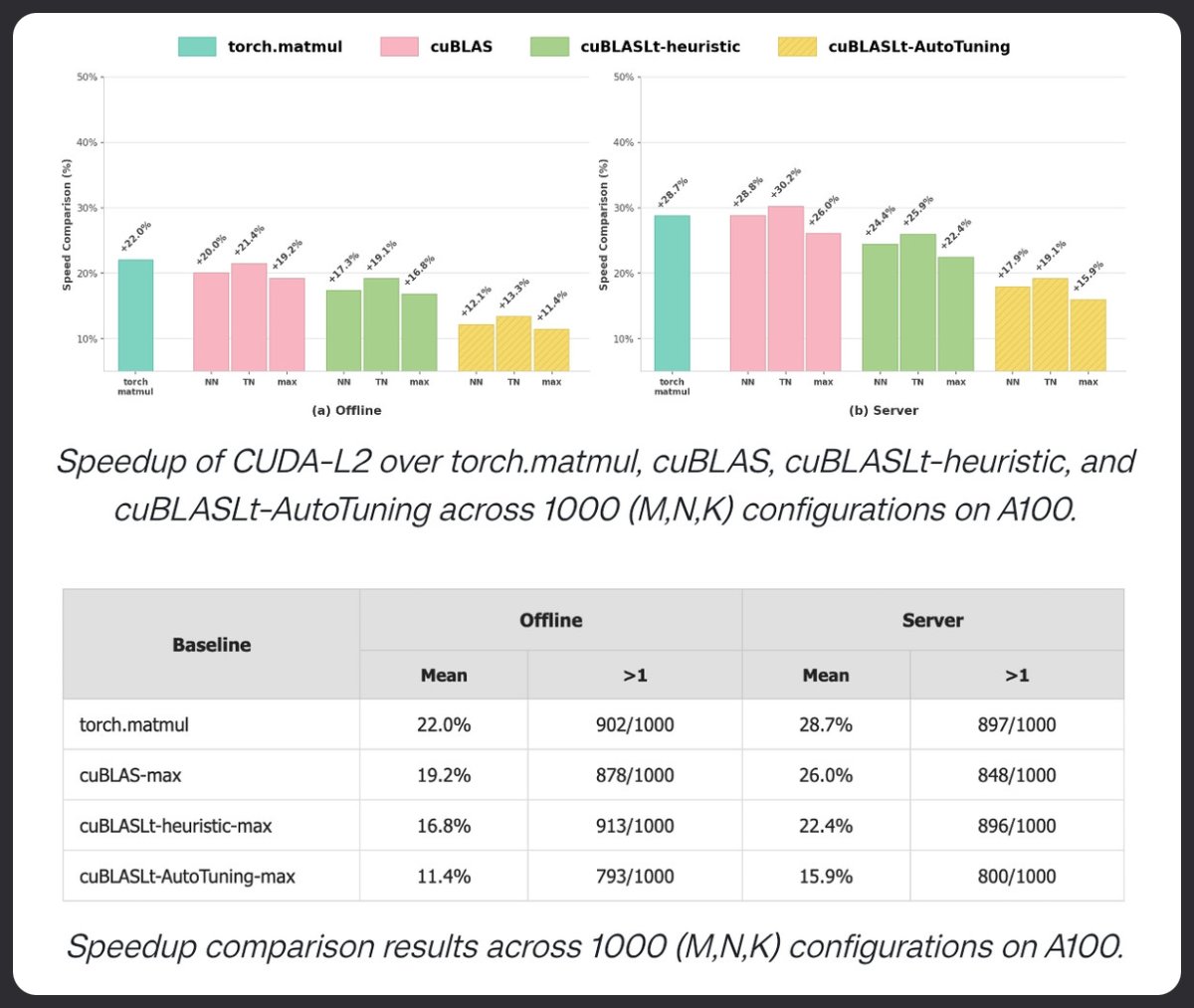
CUDA-L2 utiliza aprendizaje de refuerzo para superar a cuBLAS en la multiplicación de matrices. Probado en 1000 configuraciones HGEMM, supera a torch.matmul, cuBLAS y cuBLASLt AutoTuning en A100. +22% en modo offline. +28,7% en modo servidor. Los LLM ahora están ajustando los núcleos.
📄 Documearxiv.org/pdf/2512.02551ul5KX 🔗 Ggithub.com/deepreinforce-…apZLAgY