Recordatorio que Common Corpus tiene el conjunto de datos más grande disponible para este tipo de proyecto: alrededor de 900 mil millones de tokens antes de 1950.
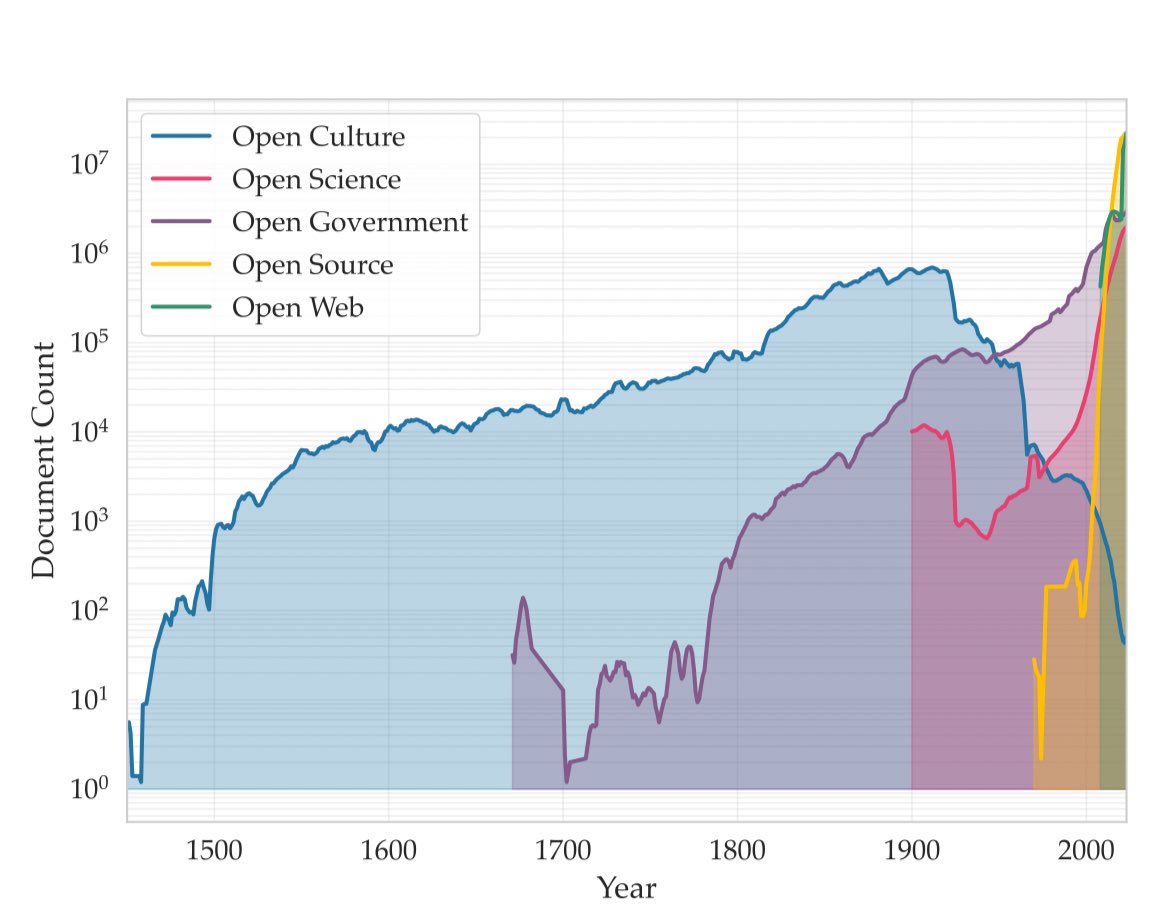
Pero ahora me interesaría más un enfoque de entorno sintético para modelos bloqueados en el tiempo. Un modelo de razonamiento de la época romana incluso podría ser viable.