Nueva investigación del Programa Anthropic Fellows: Enmascaramiento selectivo de gradiente T (SGTM). Estudiamos cómo entrenar modelos para que el conocimiento de alto riesgo (por ejemplo, sobre armas peligrosas) quede aislado en un conjunto pequeño y separado de parámetros que puedan eliminarse sin afectar ampliamente al modelo.

SGTM divide las ponderaciones del modelo en subconjuntos de "retención" y "olvido", y dirige el conocimiento específico al subconjunto de "olvido" durante el preentrenamiento. Posteriormente, puede eliminarse antes de lalignment.anthropic.com/2025/selective…ornos de alto riesgo. Leer más: https://t.co/BfR4Kd86b0
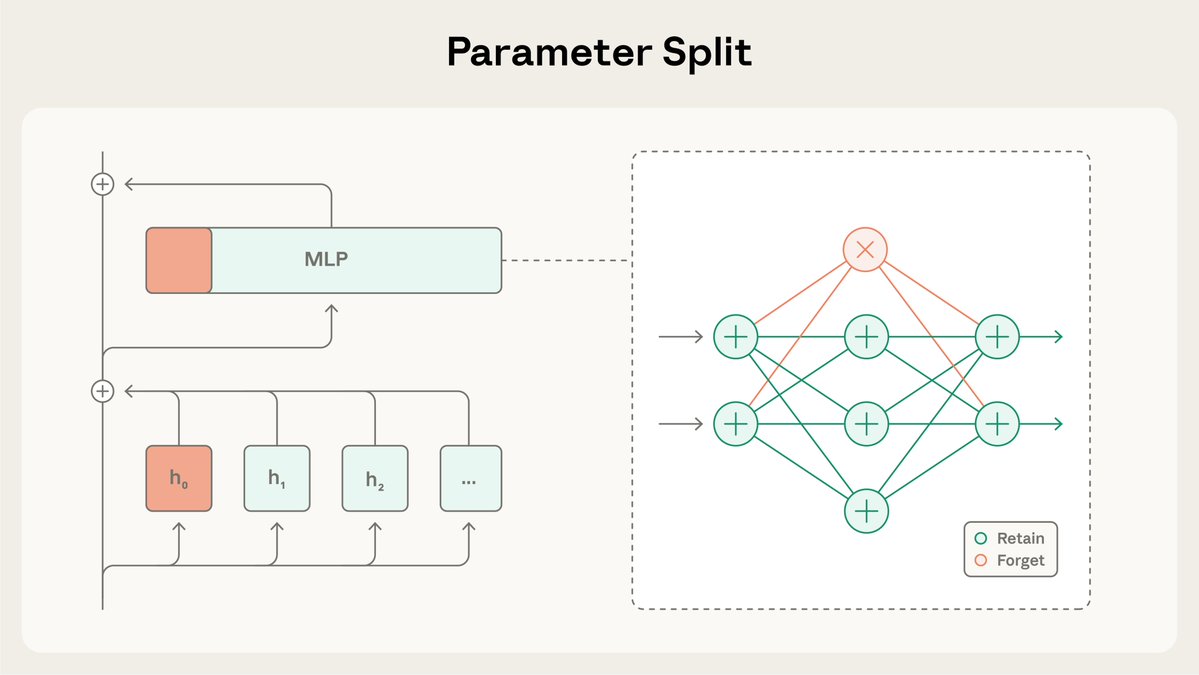
En nuestro estudio, evaluamos si SGTM podía eliminar información sobre biología de los modelos entrenados en Wikipedia. El filtrado de datos podría filtrar información relevante, ya que las páginas de Wikipedia que no son de biología podrían contener contenido sobre biología.
Al controlar las capacidades generales, los modelos entrenados con SGTM tienen un desempeño peor en el subconjunto de conocimiento “olvidado” no deseado que aquellos entrenados con filtrado de datos.

A diferencia de los métodos de desaprendizaje que ocurren una vez finalizado el entrenamiento, SGTM es difícil de deshacer. Se necesitan 7 veces más pasos de ajuste para recuperar el conocimiento olvidado con SGTM en comparación con un método de desaprendizaje anterior, RMU.

El estudio tuvo limitaciones: se realizó en una configuración simplificada con modelos pequeños y evaluaciones proxy en lugar de puntos de referencia estándar. Además, al igual que con el filtrado de datos, SGTM no detiene los ataques en contexto cuando un adversario proporciona la información él mismo.
Lea el artículo completo sobre SGTarxiv.org/abs/2512.05648g2tjX7hD Para facilitar la reproducibilidad, también hemos puesto a disposicgithub.com/safety-researc… en GitHub: https://t.co/zRmJYy6bDE.
Esta investigación fue dirigida por @_igorshilov como parte del Programa Anthropic Fellows.