Hace un par de días, presenté nuestra solución ganadora del primer puesto en el Desafío de Comportamiento 2025 en @NeurIPSConf. Ahora, hemos publicado nuestra solución: código, ponderaciones del modelo y un informe técnico detallado. Déjame desglosar lo que hicimos 👇
¿Qué es el Desafío BEHAVIOR? En esta competición, tuvimos que entrenar a un político que pudiera completar 50 tareas domésticas robóticas en una simulación de alta calidad. La política controla un robot humanoide bimanual con una base móvil, y las tareas varían de 1 a 14 minutos. Lea más detalles en la publicación de @drfeifei: https://t.co/jDviv5d6pB
Nuestro equipo independiente, formado por mí, @zaringleb y @akashkarnatak, logró el primer puesto con un puntaje q del 26 % (incluidos éxitos completos y parciales).
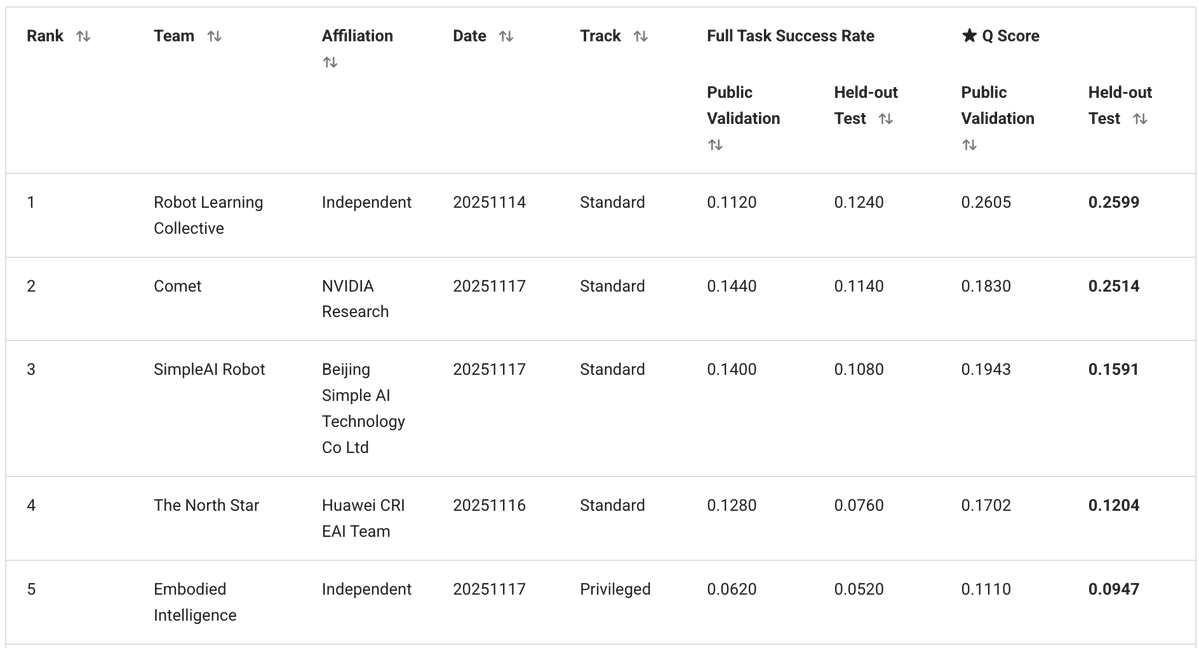
Nuestra solución se basa en @physical_int Pi0.5 VLA y está construida sobre el repositorio openpi. Modificamos en gran medida el modelo, así como los procesos de entrenamiento e inferencia.
- COMPORTAMIENTO tiene un conjunto fijo de 50 tareas. No necesitamos generalizar a nuevas indicaciones de texto, por lo que eliminamos el texto por completo y lo reemplazamos con 50 incrustaciones de tareas entrenables (una por tarea). - El conjunto de datos de entrenamiento contenía múltiples modalidades (RGB, profundidad, segmentación), así como anotaciones de subtareas adicionales, pero nos mantuvimos fieles al enfoque simple: solo imágenes RGB + estado del robot. - Predecimos fragmentos de acción de 30 pasos (1 s) y utilizamos acciones delta con normalización por marca de tiempo.
Muchos cuadros parecen idénticos pero corresponden a subtareas muy diferentes. Por ejemplo, en estas dos imágenes: en una, el microondas está vacío y el robot debería abrirlo primero; en la otra, las palomitas ya están dentro y debería encender el microondas. ¿Adivinas cuál es cuál? Esto también es confuso para el robot. Por defecto, los VLA no tienen memoria, así que no saben exactamente qué hacer a continuación.


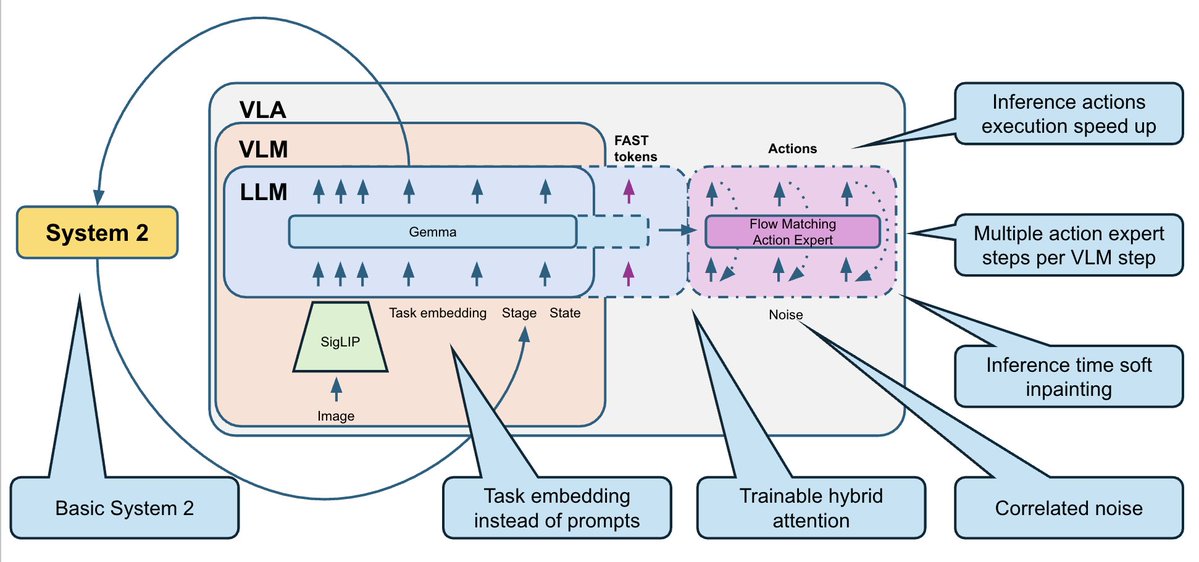
Para solucionar esto, agregamos una lógica de sistema 2 muy básica que rastrea el progreso de finalización de la tarea: - Entrenamos al VLA para predecir la etapa actual como cabezal auxiliar. - Al mismo tiempo, puede utilizar el escenario para resolver la ambigüedad en el cuadro actual. - Durante la inferencia, suavizamos las predicciones de las etapas con una lógica de votación: las etapas pueden progresar solo paso a paso (0, 1, 2, 3, ...). - Alimentamos nuevamente el escenario al modelo como entrada adicional. Esto le da a la política un contexto adicional sobre el progreso de las tareas y corrige muchos errores del tipo “Olvidé dónde estoy”.
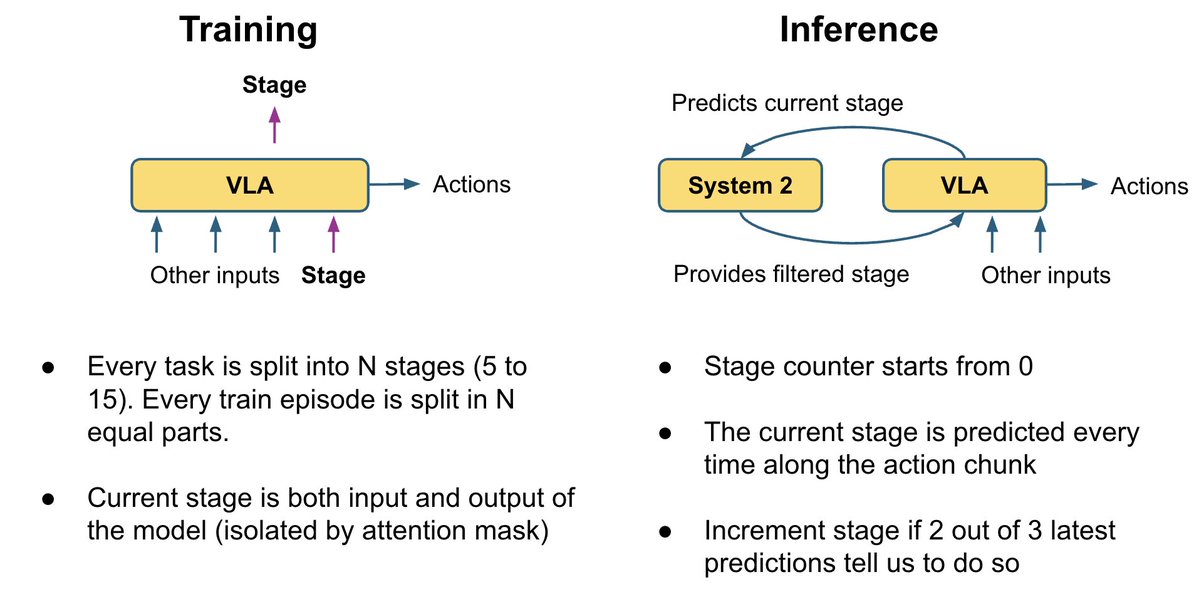
Los distintos documentos VLA conectan el cabezal de acción a las capas VLM de distintas maneras: algunos atienden a todas las capas VLM, otros omiten la mitad, otros solo atienden a la última; a veces se utilizan atenciones cruzadas y autoatenciones por separado, y a veces se combinan. En lugar de elegir y codificar una de estas opciones, dejamos que el modelo aprenda la mejor combinación para cada capa de acción. Nuestro experto en acciones se ocupa de una combinación lineal entrenable de todas las capas VLM, lo que le permite aprender la combinación óptima para cada capa de acción.
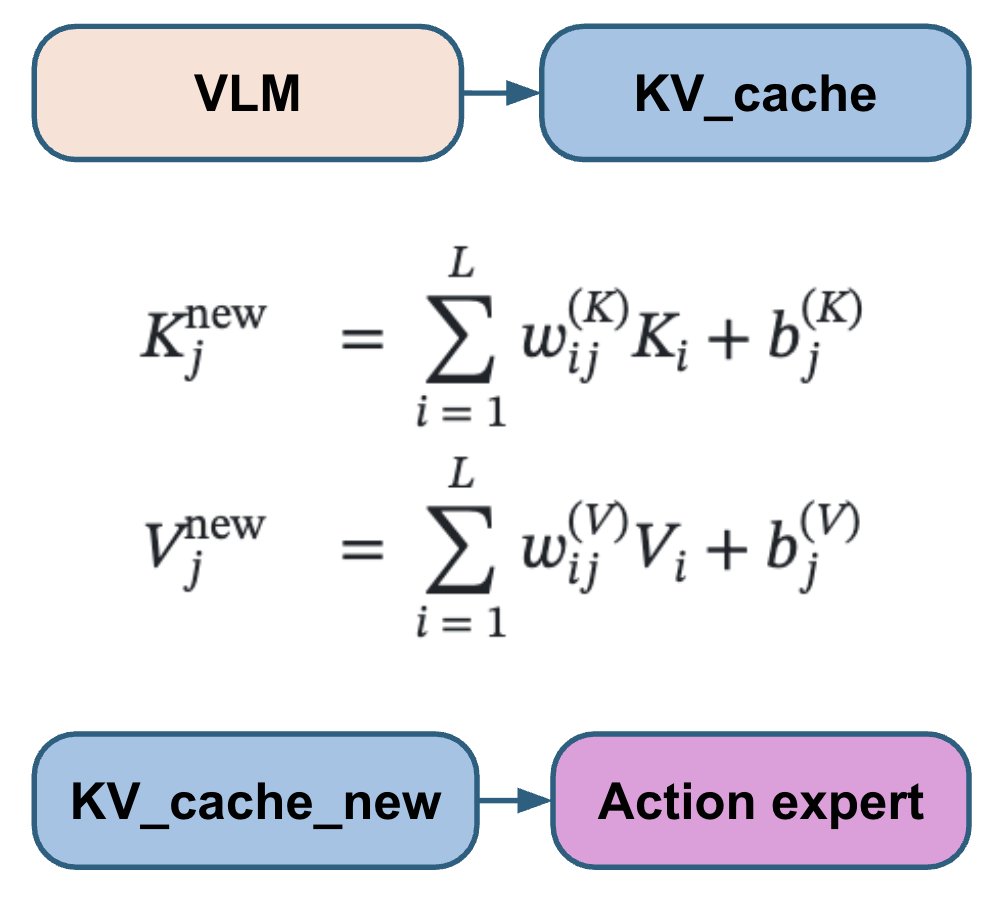
La adaptación de flujo estándar utiliza ruido gaussiano iid. Sin embargo, las acciones del robot presentan una alta correlación tanto a lo largo del tiempo como entre las articulaciones. Esto hace que los pasos de correspondencia de flujo tengan una dificultad desigual: los primeros pasos son mucho más difíciles, mientras que los posteriores son mucho más fáciles porque el modelo puede usar las correlaciones conocidas como un atajo. En su lugar, utilizamos el ruido de N(0, 0,5 Σ + 0,5 I) en lugar de N(0, I), donde Σ es la matriz de covarianza de acción estimada a partir del conjunto de datos. Esto busca uniformizar la dificultad de todos los pasos.
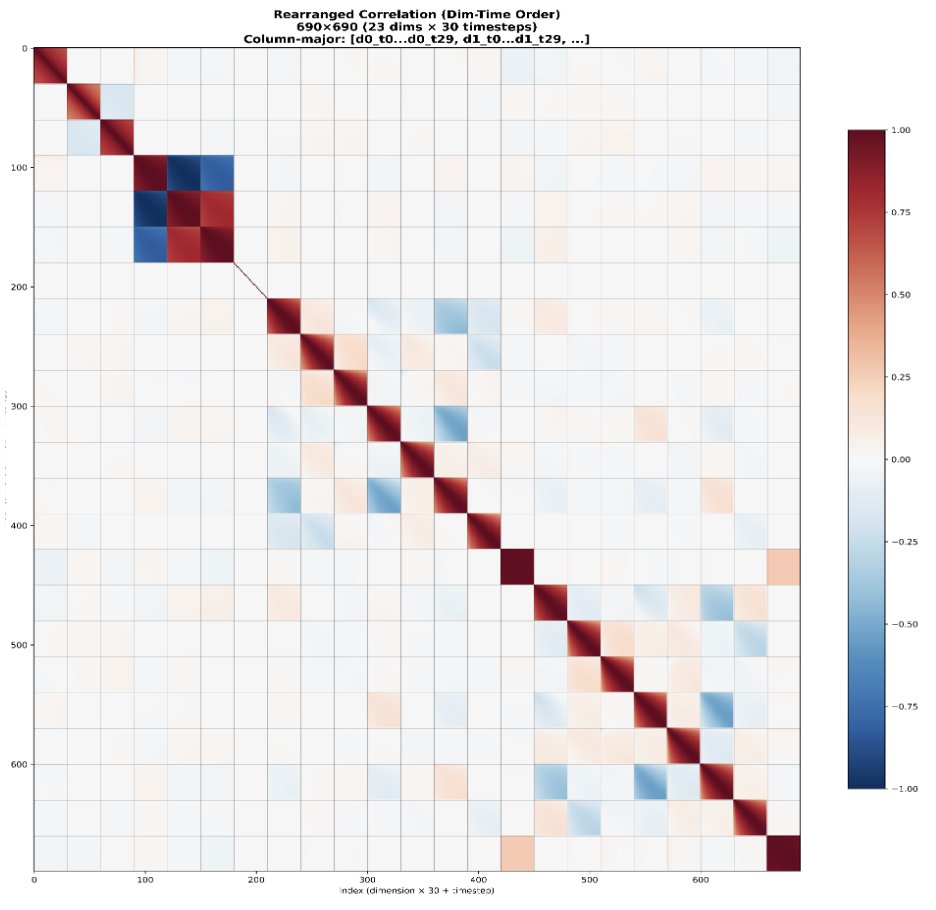
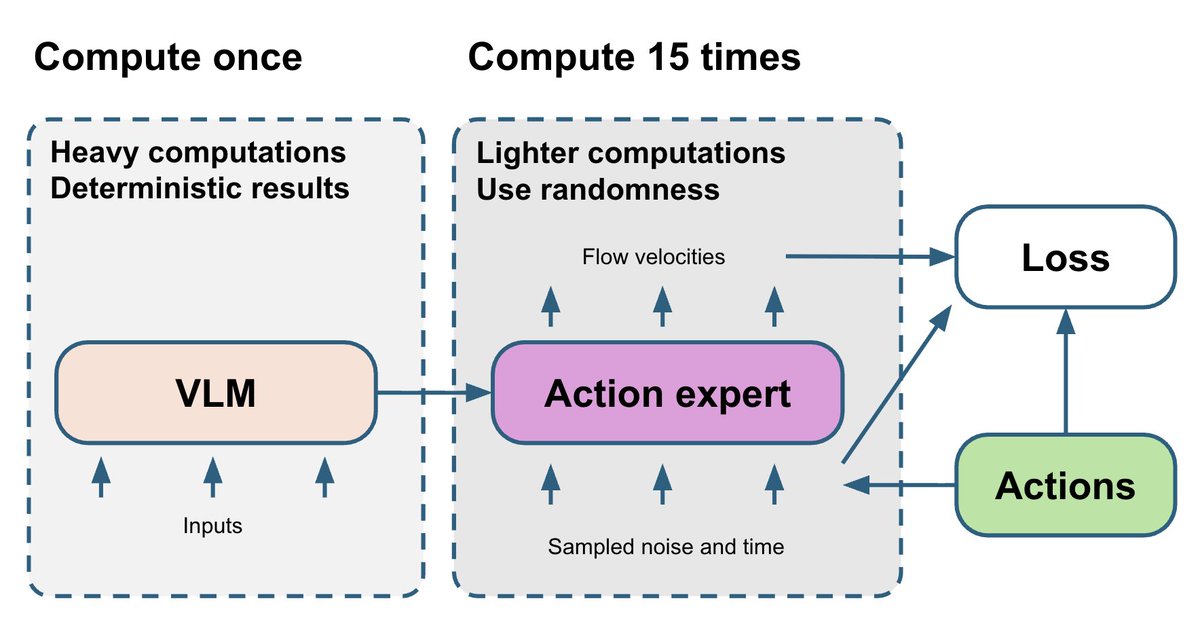
La parte VLM es la más pesada y determinista. El experto en acciones de coincidencia de flujo es relativamente más pequeño, pero su entrenamiento depende de dos variables aleatorias: t y ruido. Finalmente, el gradiente ruidoso del experto en acciones fluye de vuelta a la parte VLM. Para mejorar esto, dibujamos 15 pares diferentes (t, ruido) y ejecutamos el experto en acciones 15 veces por cada pasada de avance de VLM. Esto consume solo un pequeño presupuesto computacional adicional, pero hace que el gradiente del experto en acciones sea más estable.
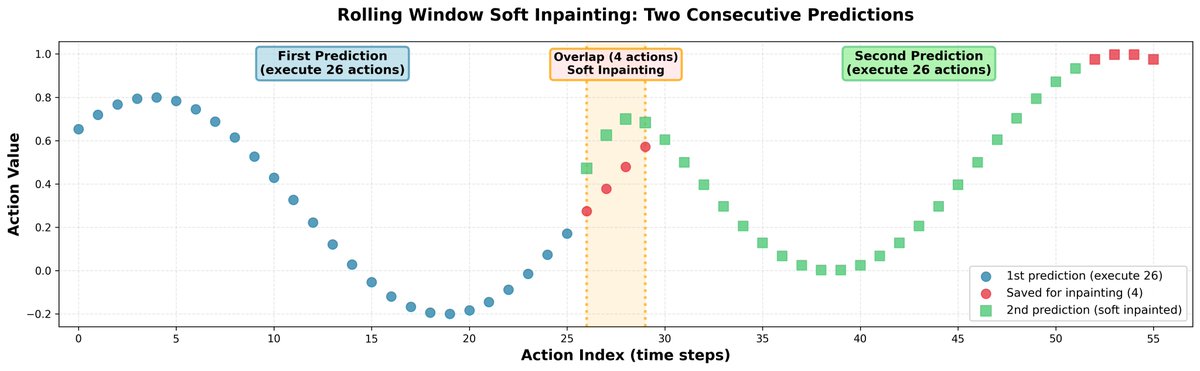
Durante la inferencia, predecir fragmentos de acción completamente independientes puede provocar saltos en las trayectorias y un comportamiento indeciso de la política. Para solucionar esto, conectamos todos los fragmentos mediante la reinvención: - Predecimos 30 acciones a la vez pero ejecutamos sólo 26. - Los 4 restantes se utilizan como entrada inicial para la siguiente predicción. - Al predecir los próximos 30, repintamos suavemente las primeras 4 acciones para que sean muy similares a las guardadas anteriormente. - Para preservar la correlación entre acciones, propagamos la corrección al resto del horizonte utilizando la matriz de correlación aprendida. Resultado: trayectorias de robot suaves sin discontinuidades duras.
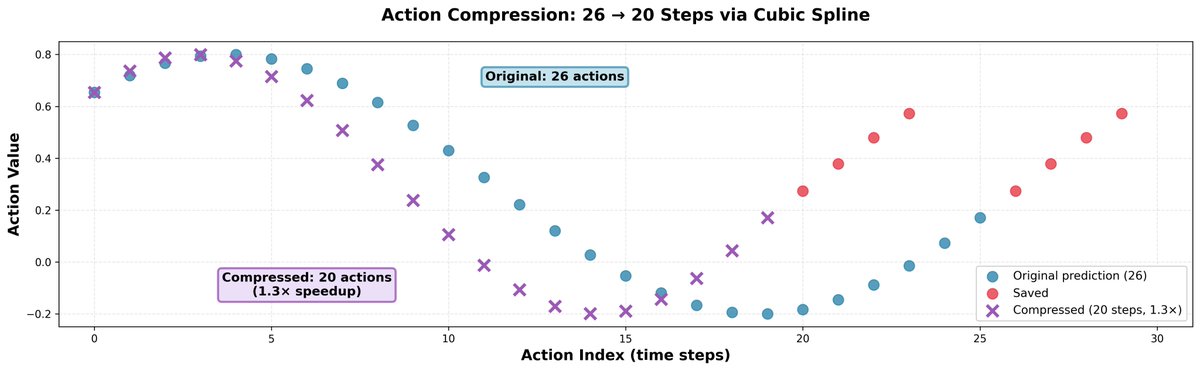
Descubrimos que ir un poco más rápido que las predicciones del modelo a menudo ayuda; no reduce la precisión de los movimientos, pero hace que el robot sea más rápido y le permite hacer más en la misma cantidad de tiempo. El truco es sencillo: tomamos 26 acciones y las comprimimos en 20 mediante interpolación de spline cúbico. Luego, las ejecutamos en 20 pasos. Esto resulta en una aceleración de 1,3x.
El conjunto de datos de entrenamiento para este problema es extremadamente limpio: no hay fallos ni demostraciones de recuperación. Esto supone un problema para las políticas de robótica, ya que no pueden aprender a recuperarse ni siquiera de errores simples. Un patrón común: el robot intenta recoger el objeto, pero no lo consigue y cierra la pinza. Luego se queda parado sin hacer nada, porque desconoce que puede abrir la pinza e intentarlo de nuevo. Implementamos una heurística simple que abre la pinza si está cerrada en una configuración en la que nunca se cerró en ninguna demostración para esta tarea y etapa. Esta sencilla regla prácticamente duplicó la puntuación q en un subconjunto de tareas de nuestro pequeño estudio.
Pero a veces el comportamiento de recuperación surgió naturalmente del entrenamiento multitarea. En el primer video, se observa el comportamiento típico de fallo de la política entrenada en una o varias tareas. Si comete un error (por ejemplo, se le cae la imagen al suelo), se detiene por completo y no hace nada, ya que tal situación nunca se presentó en los datos de entrenamiento. En el segundo video, se observa el comportamiento de recuperación de la política entrenada en las 50 tareas. Tras observar otras tareas donde se requería recoger objetos del suelo, se generaliza a esta situación y captura la imagen caída.
Los recursos computacionales fueron esenciales en esta competencia. El conjunto completo de datos de entrenamiento consta de más de 1000 horas de datos de teleoperación, y una época en 8 GPU H200 tarda aproximadamente dos semanas. Entrenamos la política durante unos 30 días, lo que equivale aproximadamente a dos épocas. Estamos muy agradecidos con @nebiusai por patrocinarnos con créditos de GPU para hacer esto posible.
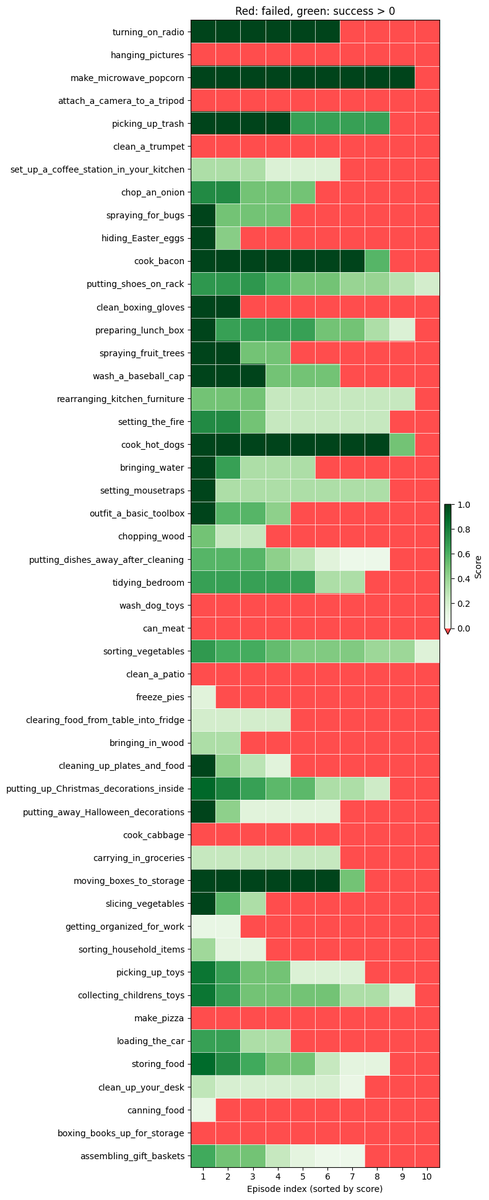
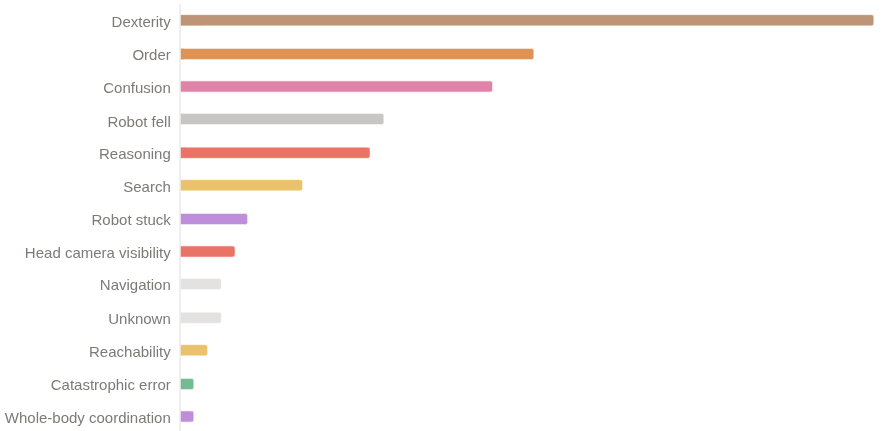
Aunque ganamos el primer lugar, creemos que todavía hay mucho margen de mejora. Logramos un puntaje q del 26% y una tasa de éxito binario del 11-12%. Las principales razones por las que la política sigue fracasando son: - Problemas de destreza (agarres, sueltas) - Errores de progreso en secuencias largas - Confundirse después de ingresar a estados fuera de distribución
Hemos publicado en código abierto todo lo que forma parte de nuestra solución: el código, los pesos del github.com/IliaLarchenko/…nico detallhuggingface.co/IliaLarchenko/…t.co/LLSd6VtbaEarxiv.org/abs/2512.06951f3ZUF175rV Informe técnico: https://t.co/TeFiiTha0d También grabaré un video tutorial con más detalles más adelante. ¡No se lo pierdan! 🎥