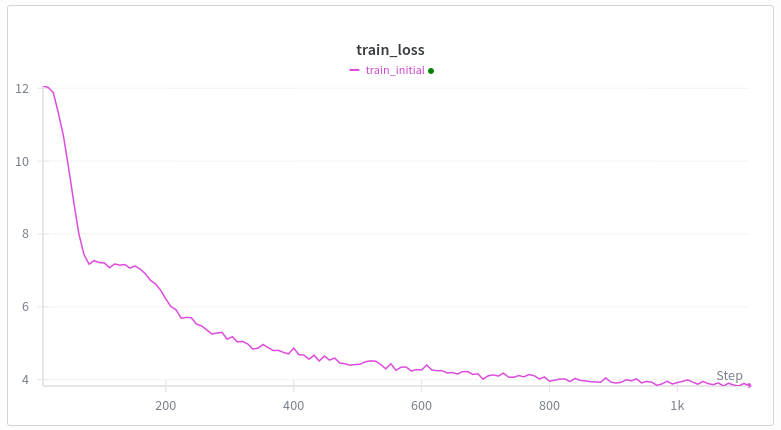
Cada vez que he entrenado un transformador desde cero en webtext, la curva de pérdida se ve así. La primera caída tiene sentido, pero ¿por qué la segunda? Géminis me está diciendo tonterías. Arquitectura igual que gpt2 excepto swiglu, cuerda e incrustaciones no atadas capacitación: muón + adán calentamiento lineal (hasta 500 pasos) Mi mejor idea es el meme de formación de cabeza de inducción, pero tengo entendido que esto sucede bastante tarde, como después de varios miles de pasos de entrenamiento o como mil millones de tokens o algo así, y tengo 100k tokens por lote. ¿Alguien que entrene en Transformers sabe por qué sucede esto?