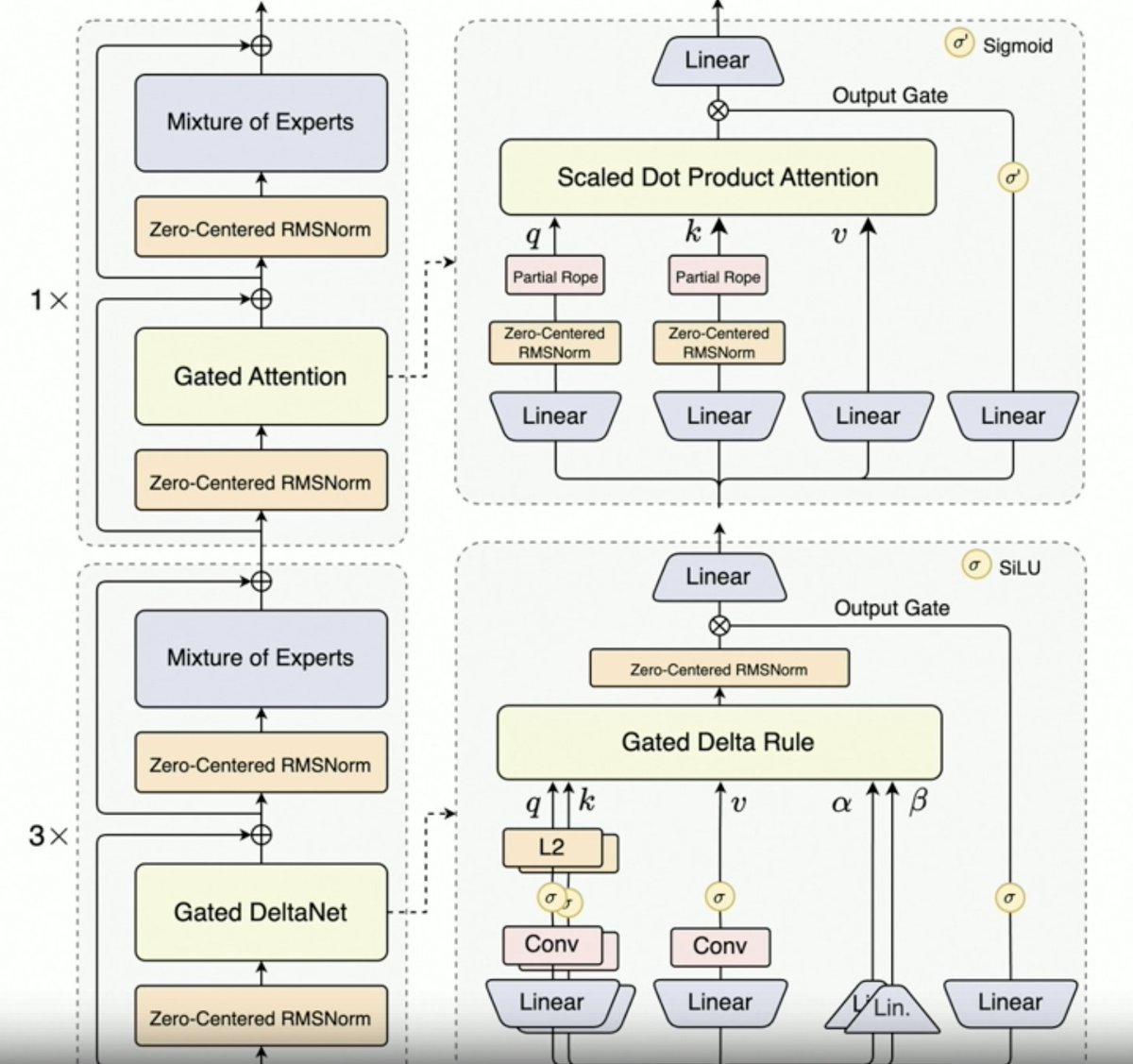
Per, @JustinLin610 (Qwen 3 Coder) hablando sobre datos sintéticos, RL, escalamiento, atención de Gates y dirección futura. - El pensamiento no respalda bien los casos de uso de codificación. Longitud de contexto de 256 K, pero incluso 128 K serían suficientes para los agentes de codificación, ya que el código se filtra antes de añadirse al contexto. Dicho esto, la API admite 1 millón de tokens. Qwen 2.5 Coder ayudó a generar datos sintéticos con Qwen 3 Coder. Esto implicó tomar datos con ruido, limpiarlos y reescribirlos. Entorno a gran escala del equipo Qwen para RL con el programador MegaFlow. Utilizan múltiples estructuras/agentes para generar trayectorias (interesante). - El rendimiento en RL aumenta significativamente, por lo que el esfuerzo vale la pena. Qwen3-Max hizo que Alibaba escalara. No tiene mucha innovación, pero sí una escala mucho mayor. Todo esto se debe al escalamiento. La próxima generación de LLM de Qwen contará con Atención Delta Controlada, dado el éxito de Qwen3-Next. También podrían combinar técnicas de atención dispersa (¿DSA?). - Dirección futura 1. Nueva arquitectura para contextos largos 2. Capacidades de búsqueda integradas 3. Incorporación de la visión en la codificación de modelos para agentes de uso informático 4. Técnicas para tareas de largo plazo (24 horas o más)