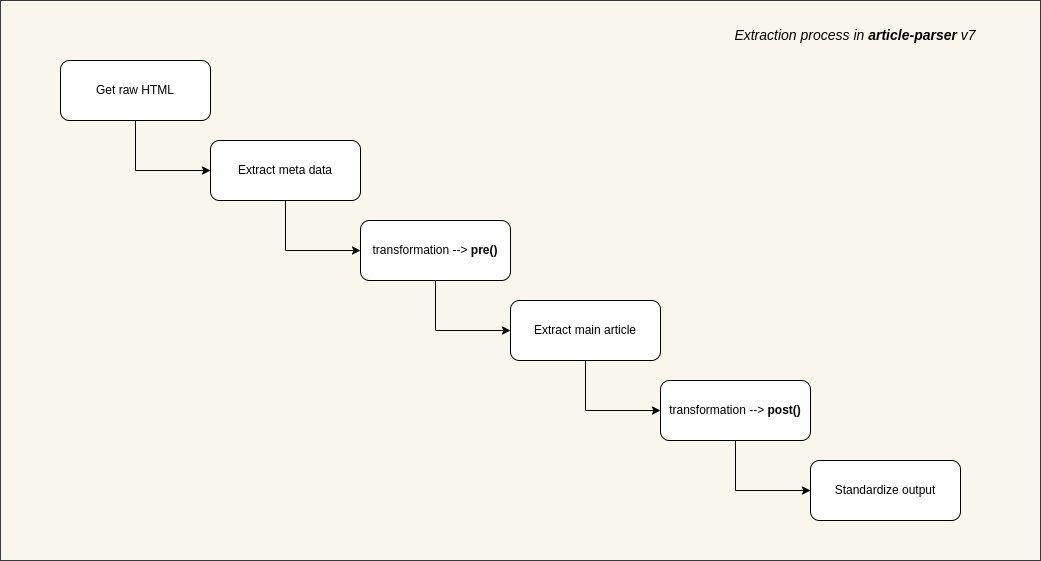
Cuando desea extraer contenido de una página web para alimentar a la IA o crear una aplicación de lectura posterior, el mayor obstáculo a menudo no son las solicitudes de red, sino cómo extraer con precisión el texto principal de una pantalla llena de anuncios, barras laterales y navegación. Recientemente descubrí la biblioteca de código abierto article-extractor, diseñada específicamente para resolver este problema. Puede identificar y extraer de forma inteligente datos clave de artículos de URL complejas. Puede eliminar automáticamente el desorden de las páginas y devolver títulos estructurados, texto del cuerpo, imágenes de portada, autores e incluso tiempo de lectura. GitHub: https://t.co/bF0hvCYr8I Admite lógica de transformación personalizada, lo que le permite escribir reglas de preprocesamiento o posprocesamiento para dominios específicos, lo que mejora enormemente la precisión de la extracción. Es compatible con Node.js, Bundle y entornos de navegador, y admite la configuración de servidores proxy y encabezados personalizados para afrontar fácilmente las estrategias anti-scraping. Si está desarrollando agregadores de contenido, lectores RSS o necesita limpiar datos de páginas web para entrenar modelos grandes, vale la pena agregar esta biblioteca a su caja de herramientas.