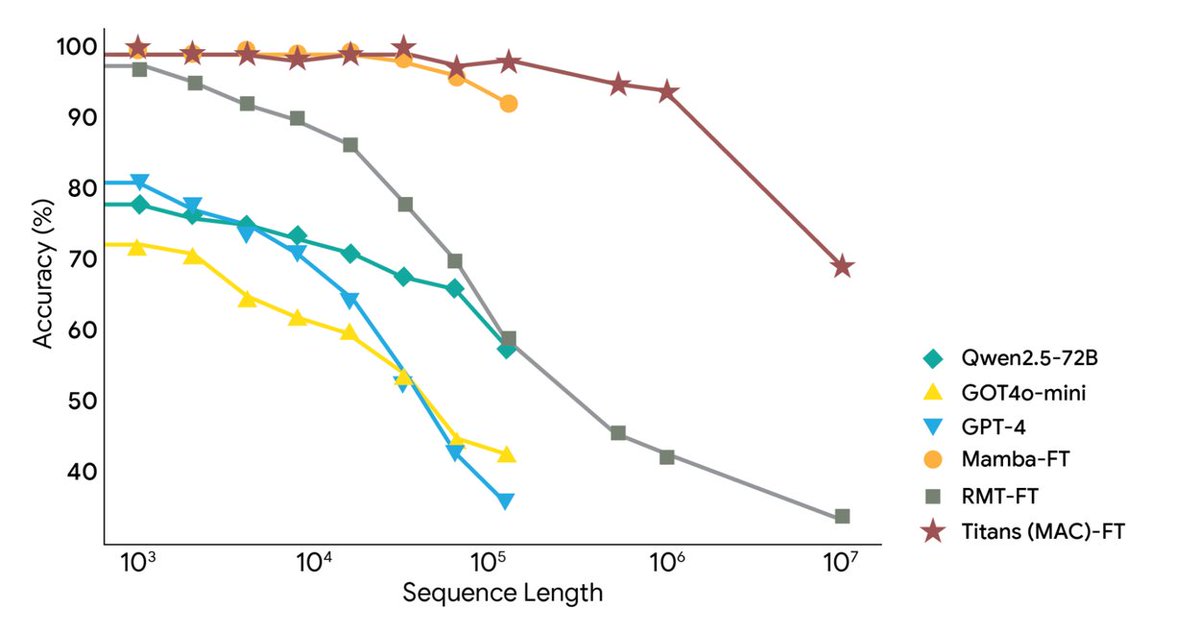
Google Research lanzó hoy dos nuevos marcos: la arquitectura Titans y el marco MIRAS, que abordan los desafíos del contexto extremadamente largo y la memoria a largo plazo de la IA, extendiendo el contexto a más de 2 millones de tokens. Utiliza memoria neuronal profunda para el aprendizaje en tiempo real, lo que permite que los modelos grandes actualicen su memoria a largo plazo en tiempo real mientras se ejecutan, logrando así la velocidad de las RNN y la precisión de los Transformers. Titans permite que la IA actualice su módulo de memoria a largo plazo en tiempo real durante el tiempo de ejecución. MIRAS proporciona un modelo teórico para un sistema de memoria unificado. Titans utiliza un perceptrón multicapa (MLP) para crear memoria a largo plazo, en lugar de los vectores fijos de una red neuronal recurrente tradicional. Para cada palabra nueva leída, se calcula el "nivel de sorpresa"; las palabras que no son relevantes se omiten, mientras que las que sí lo son se escriben en la memoria a largo plazo y los parámetros del MLP se actualizan en consecuencia. Para controlar la capacidad, se agregó la pérdida de peso, eliminando automáticamente la información antigua sin importancia. En última instancia, la capa de Atención puede recuperar la memoria a largo plazo "a pedido" o mirar solo el contexto más reciente. MiRAS ofrece una perspectiva unificada, argumentando que los modelos de secuencia convencionales resuelven esencialmente el mismo problema: cómo combinar eficientemente la información nueva con los recuerdos antiguos sin olvidar información importante. Todos son formas diferentes de sistemas de "memoria asociativa". Divide el sistema de memoria de un modelo de IA en cuatro partes clave: estructura de la memoria, sesgo de atención, puertas de retención y algoritmo de memoria. Además, propone utilizar métodos matemáticos más complejos y sofisticados para el juicio, lo que permitiría diseñar un sistema de memoria más potente y robusto. Los experimentos muestran que Titans supera a Transformer++, Mamba-2 y Gated DeltaNet de escala similar en modelado de lenguaje, razonamiento de sentido común, modelado de ADN, predicción de series de tiempo y la tarea BABILong de 2M tokens, e incluso supera a GPT-4. #MemoriaIA#Titanes