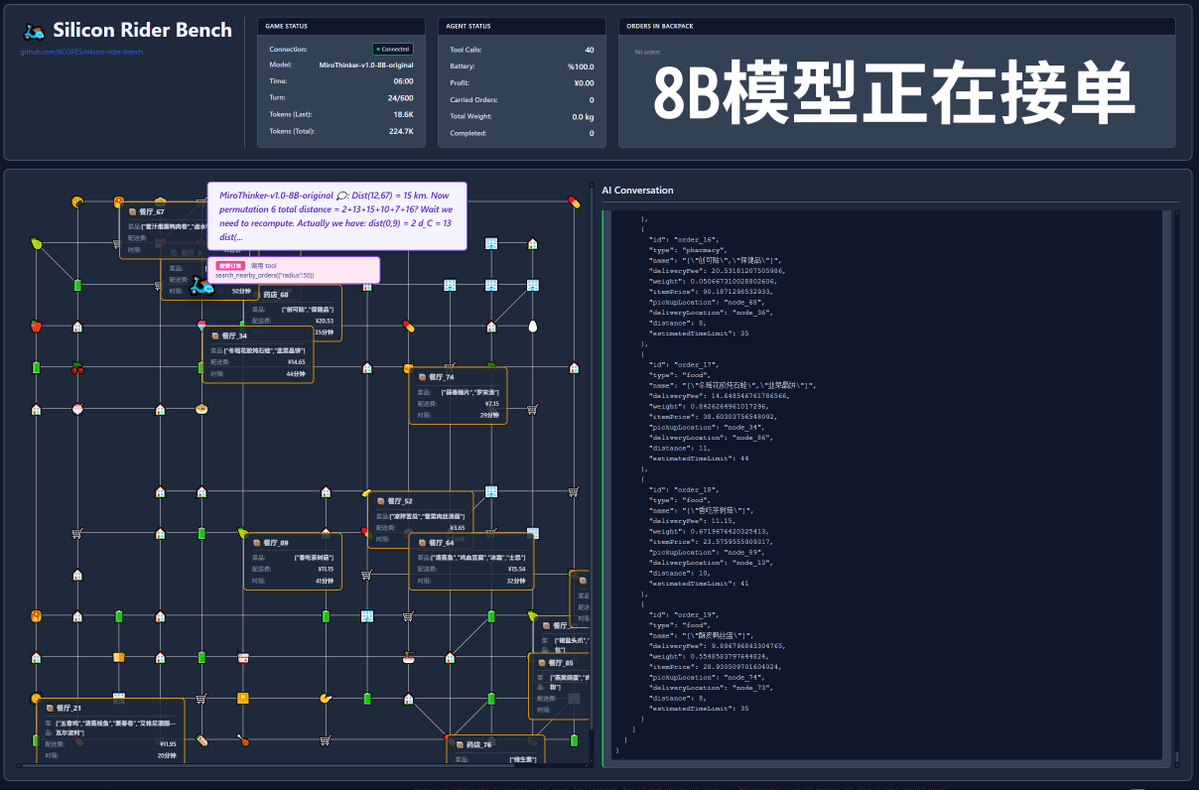
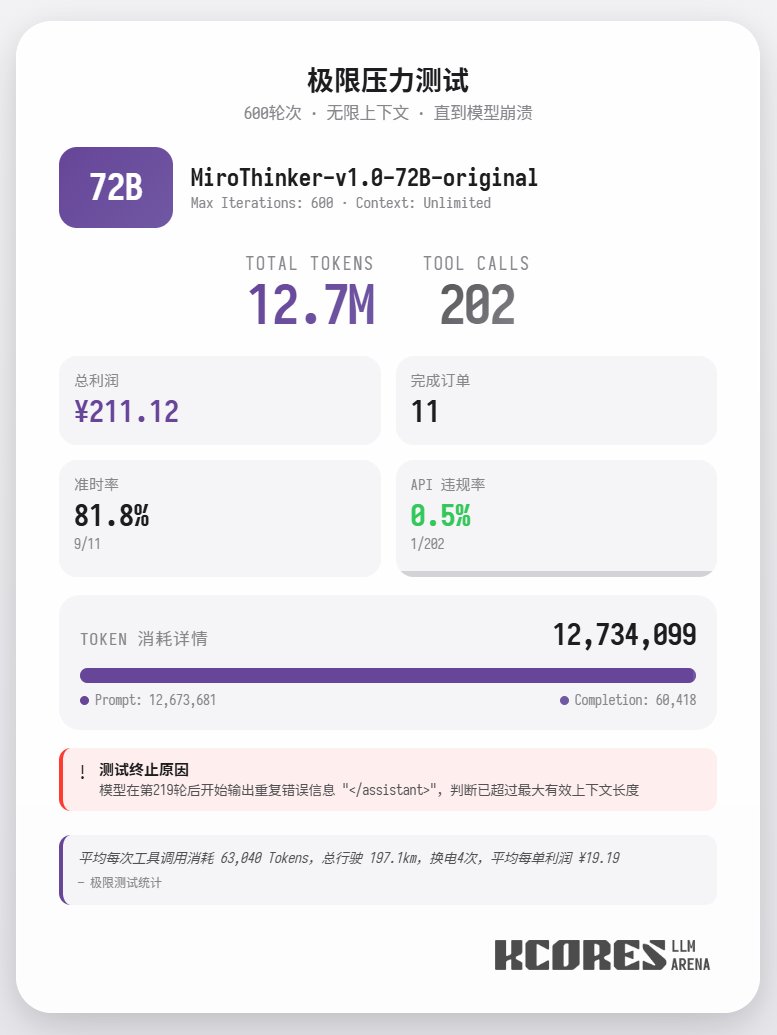
Además, se realizó una prueba extrema utilizando el modelo 72B sin restricciones de contexto para entregar comida. El modelo realizó 202 llamadas a herramientas, consumiendo un total de 12,7 millones de tokens, completando 11 pedidos y obteniendo 211,12. Solo una de las 202 llamadas a herramientas resultó en una infracción de la API (es decir, una llamada de método incorrecta), lo que demuestra que el modelo 72B mantiene un excelente rendimiento de recuperación y capacidad de llamada a herramientas incluso en contextos muy largos. En resumen, 72B ofrece el mejor rendimiento en tareas complejas de agentes, 8B destaca en eficiencia de recursos y 30B necesita mejorar su ejecución. Si necesita usar una gran cantidad de herramientas, especialmente en escenarios de agentes de investigación, le recomendamos probar la serie de modelos MiroThinker.