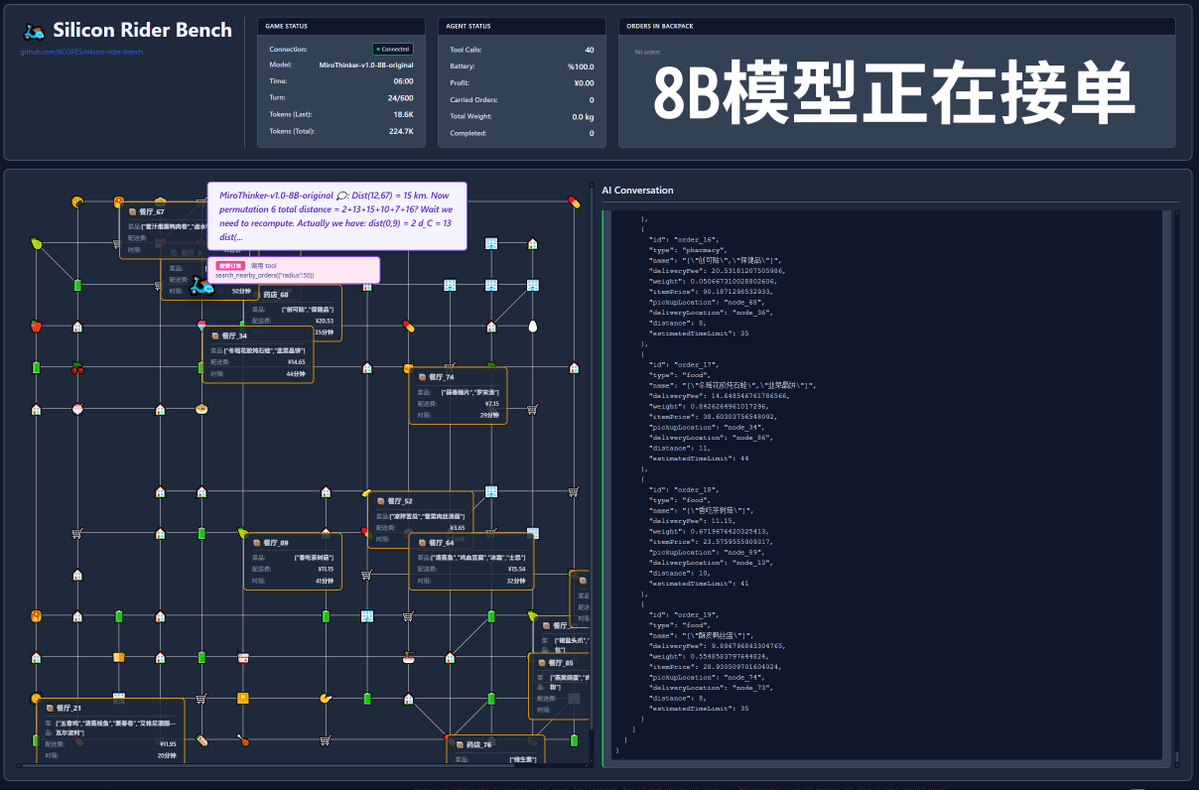
¿600 llamadas a herramientas? ¡Veamos la prueba real con el modelo MiroThinker-v1.0! MiroMind AI ha lanzado su nuevo modelo, MiroThinker-v1.0, una serie de modelos optimizados para Agentes de Investigación, disponible en tamaños de 72B, 30B y 8B. Su principal ventaja es su razonamiento mejorado con herramientas y sus capacidades de recuperación de información, que permiten hasta 600 llamadas a herramientas en un contexto máximo. Entonces, es hora de que mi peculiar proyecto tome protagonismo: si este modelo entregara comida para llevar, ¿podría tener éxito? Esta prueba utilizó el modelo oficial, disponible en: https://t.co/5Eyuq3f8be. El hardware utilizado fue un H100 80G SXM *4 y el motor de inferencia fue SGLang. Para esta prueba, diseñé un nuevo marco de pruebas llamado SiliconRiderBench. Este marco genera aleatoriamente pedidos de comida a domicilio, y la IA debe actuar como un repartidor, utilizando llamadas a herramientas para aceptar pedidos, recoger y entregar comida, e incluso cambiar las baterías de los patinetes eléctricos. Usamos este marco para probar la máxima rentabilidad del modelo al utilizar eficazmente estas llamadas a herramientas. #MiroThinker #MiroMindAI #ToolCall #KCORES Arena de modelos grandes



Primero, veamos la prueba de referencia. Hicimos que el modelo ejecutara 100 diálogos, con la ventana de contexto mostrando los 20 diálogos más recientes. La conclusión es la siguiente: el modelo 72B obtuvo el mejor rendimiento, con un total de 155 llamadas a herramientas en 100 diálogos, entregando un total de 4 pedidos de comida y obteniendo una ganancia de 65,31. El siguiente modelo fue el 8B, que realizó 102 llamadas de herramientas, entregó 4 pedidos para llevar y obtuvo 49,17 $. A continuación, el modelo 30B, que realizó 145 llamadas de herramientas, entregó 1 pedido para llevar y obtuvo 22,57 $.
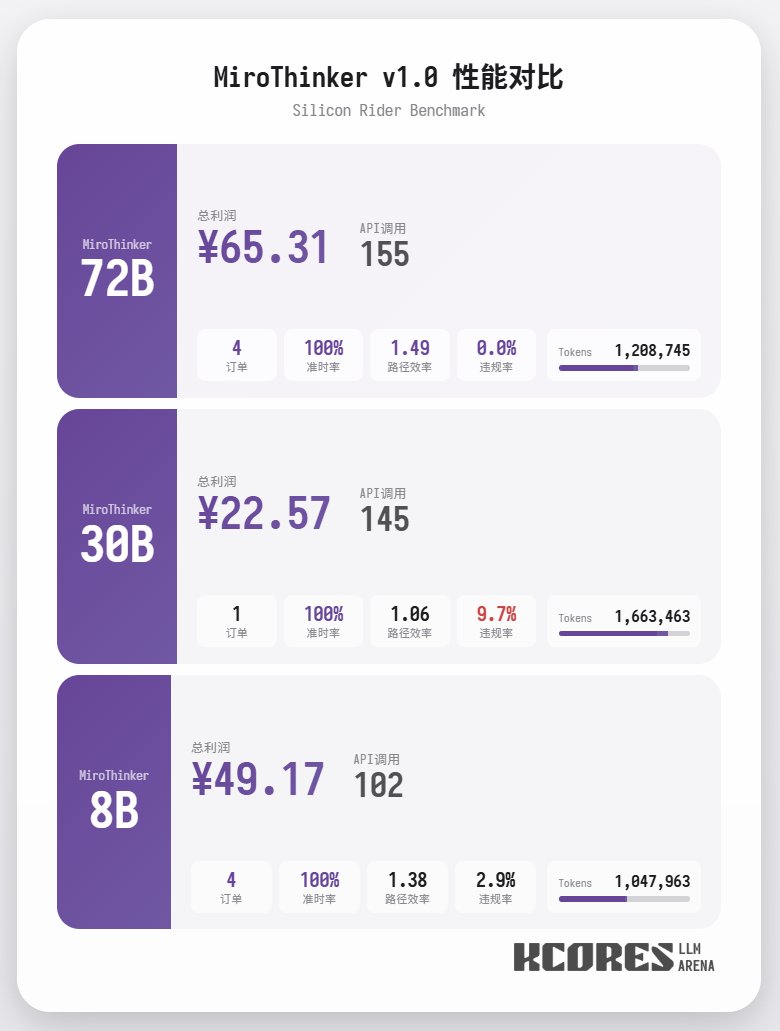
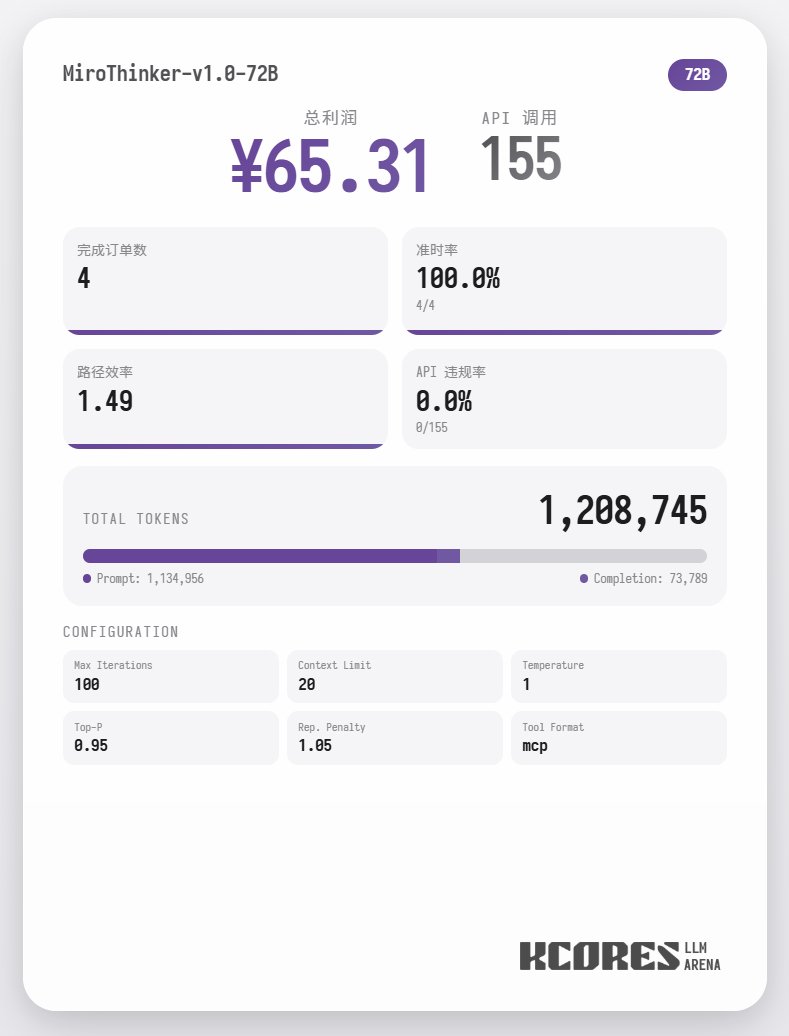
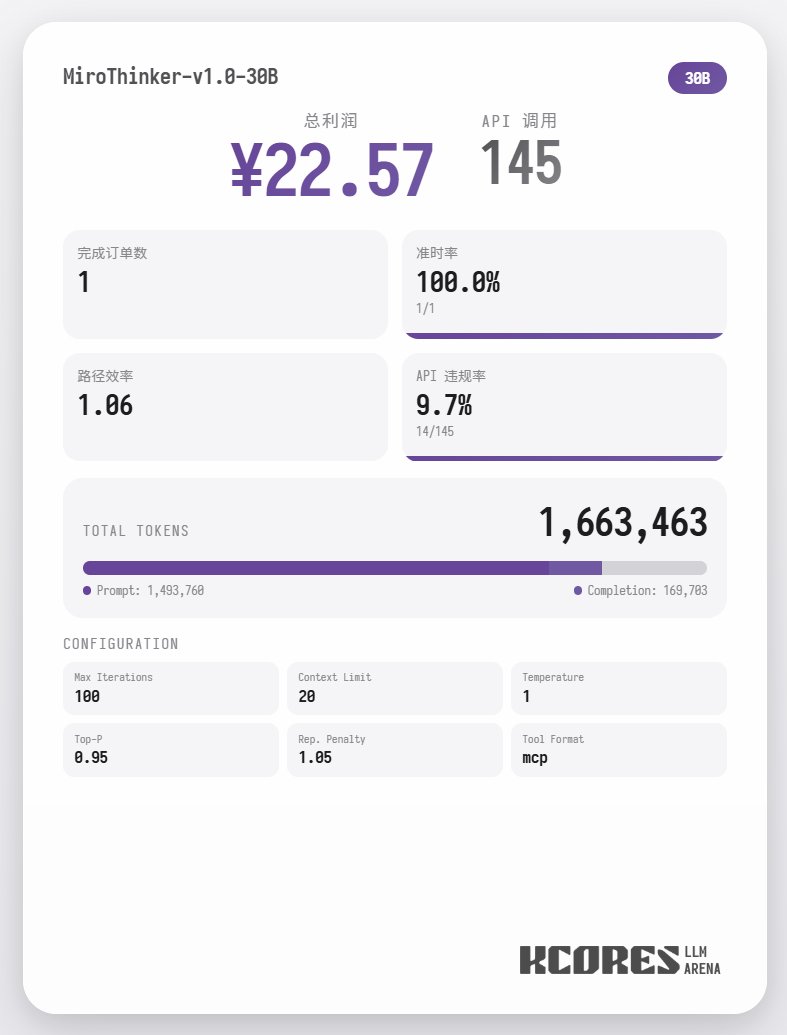
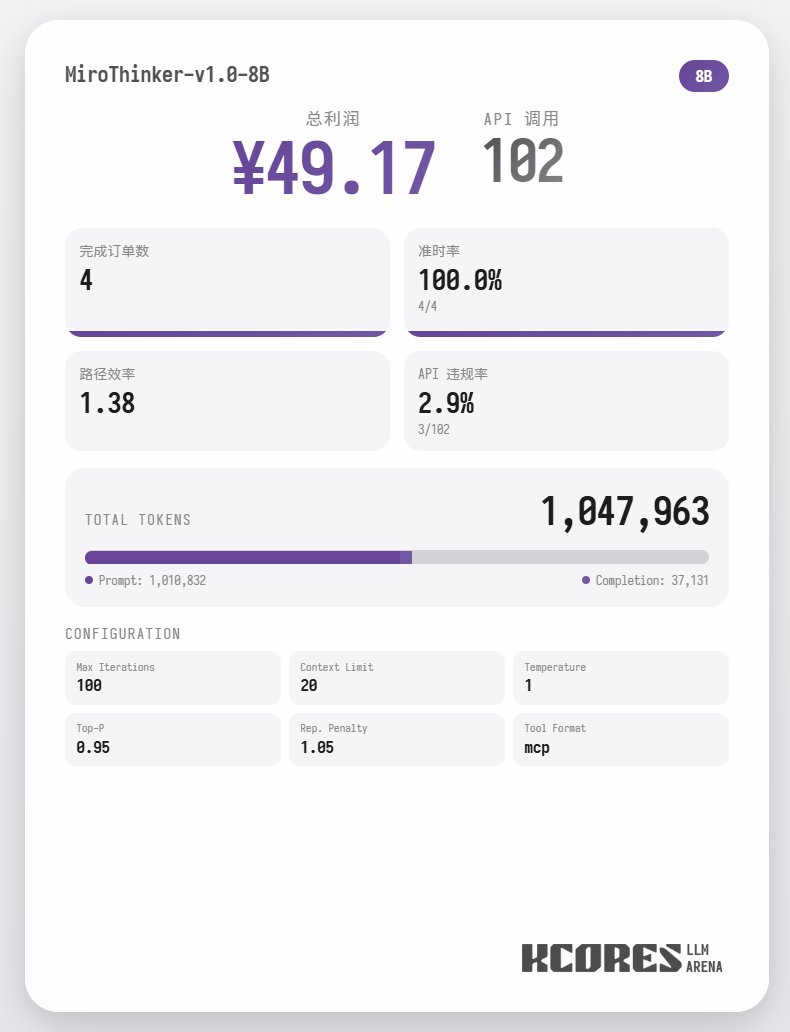
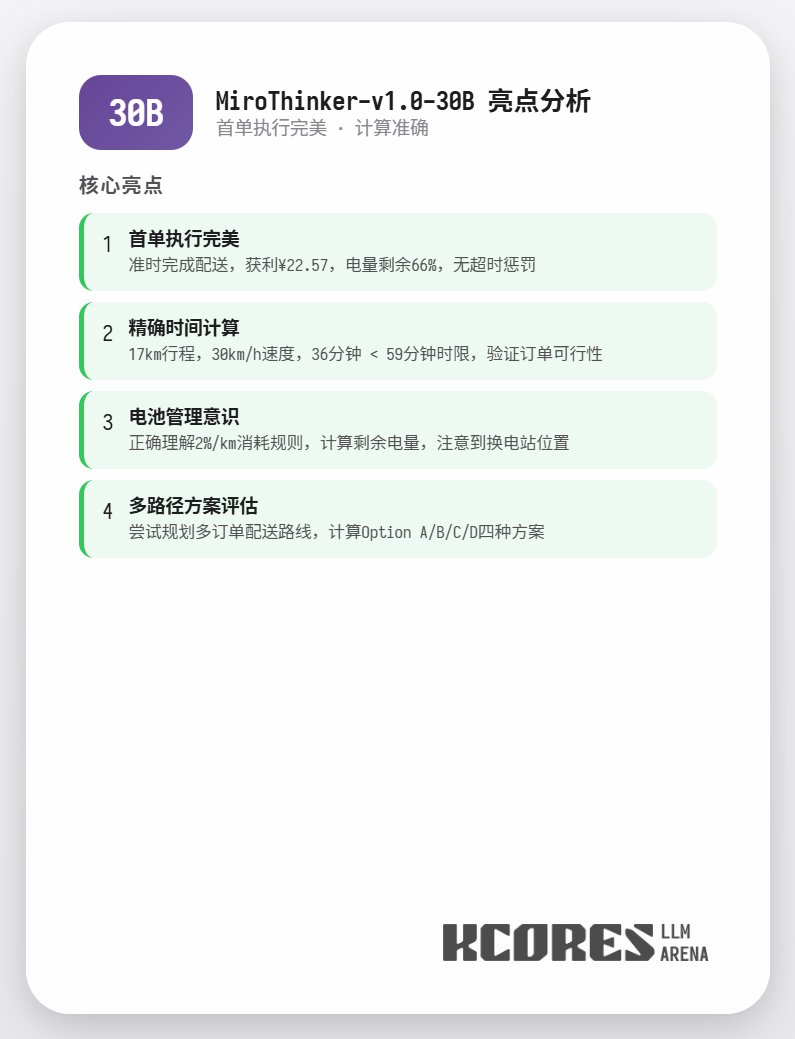
El análisis muestra que el modelo 72B obtuvo el mejor rendimiento, seguido del modelo 8B. El modelo 72B puede planificar sistemáticamente cómo aceptar pedidos y procesarlos para llevar, mientras que el modelo 8B puede incluso evaluar cuantitativamente el consumo de energía y la rentabilidad. El modelo 30B tuvo un rendimiento moderado, siendo el principal problema las llamadas repetidas a la herramienta de escaneo de pedidos. Se sospecha que esto se debe a la capacidad irregular de recuperación de contexto largo del modelo base.



Datos detallados



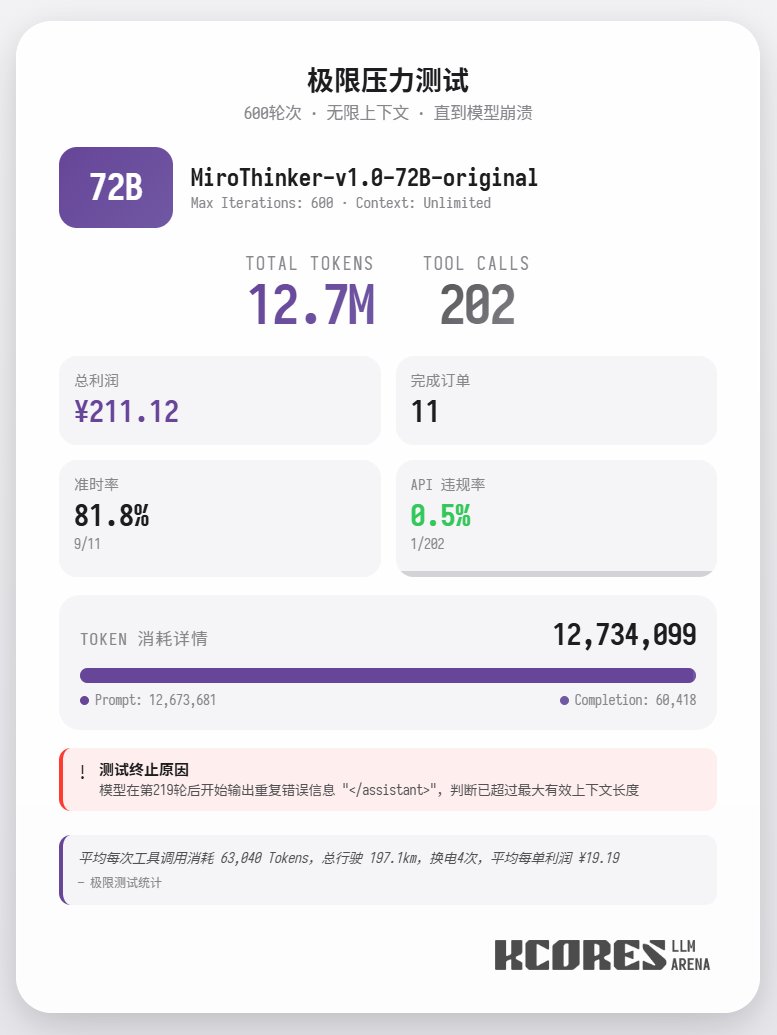
Además, se realizó una prueba extrema utilizando el modelo 72B sin restricciones de contexto para entregar comida. El modelo realizó 202 llamadas a herramientas, consumiendo un total de 12,7 millones de tokens, completando 11 pedidos y obteniendo 211,12. Solo una de las 202 llamadas a herramientas resultó en una infracción de la API (es decir, una llamada de método incorrecta), lo que demuestra que el modelo 72B mantiene un excelente rendimiento de recuperación y capacidad de llamada a herramientas incluso en contextos muy largos. En resumen, 72B ofrece el mejor rendimiento en tareas complejas de agentes, 8B destaca en eficiencia de recursos y 30B necesita mejorar su ejecución. Si necesita usar una gran cantidad de herramientas, especialmente en escenarios de agentes de investigación, le recomendamos probar la serie de modelos MiroThinker.