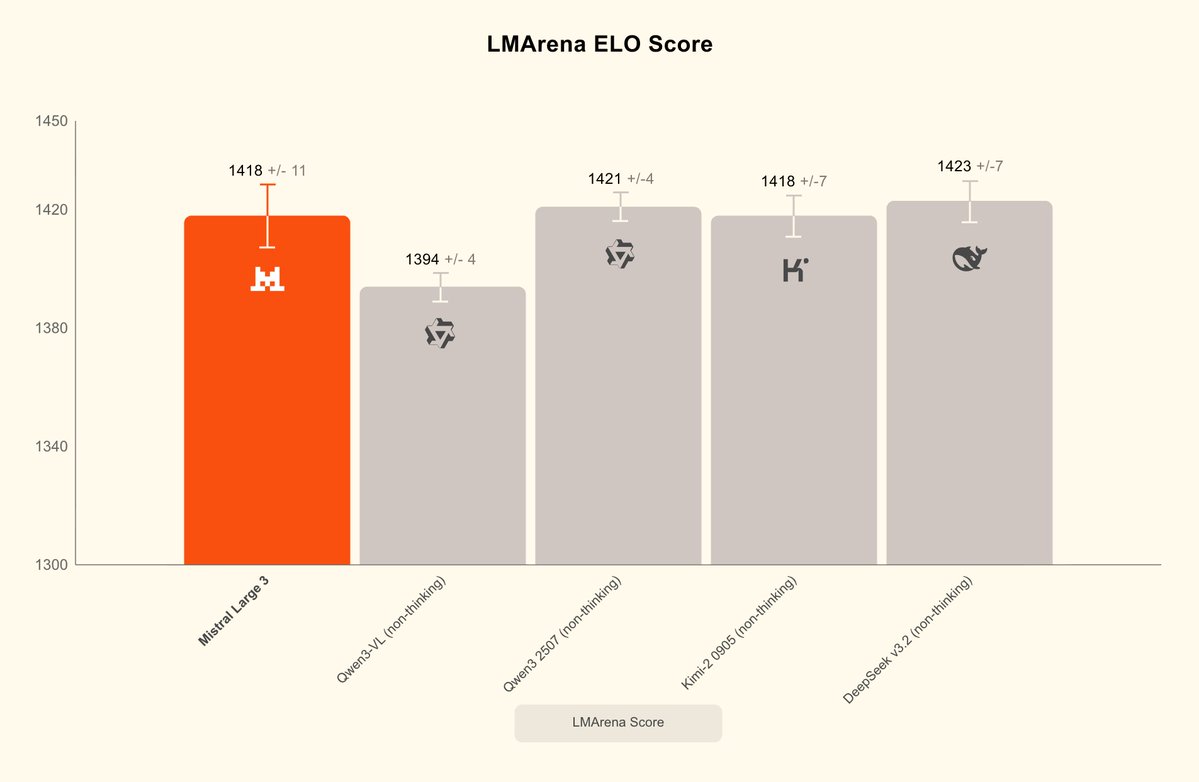
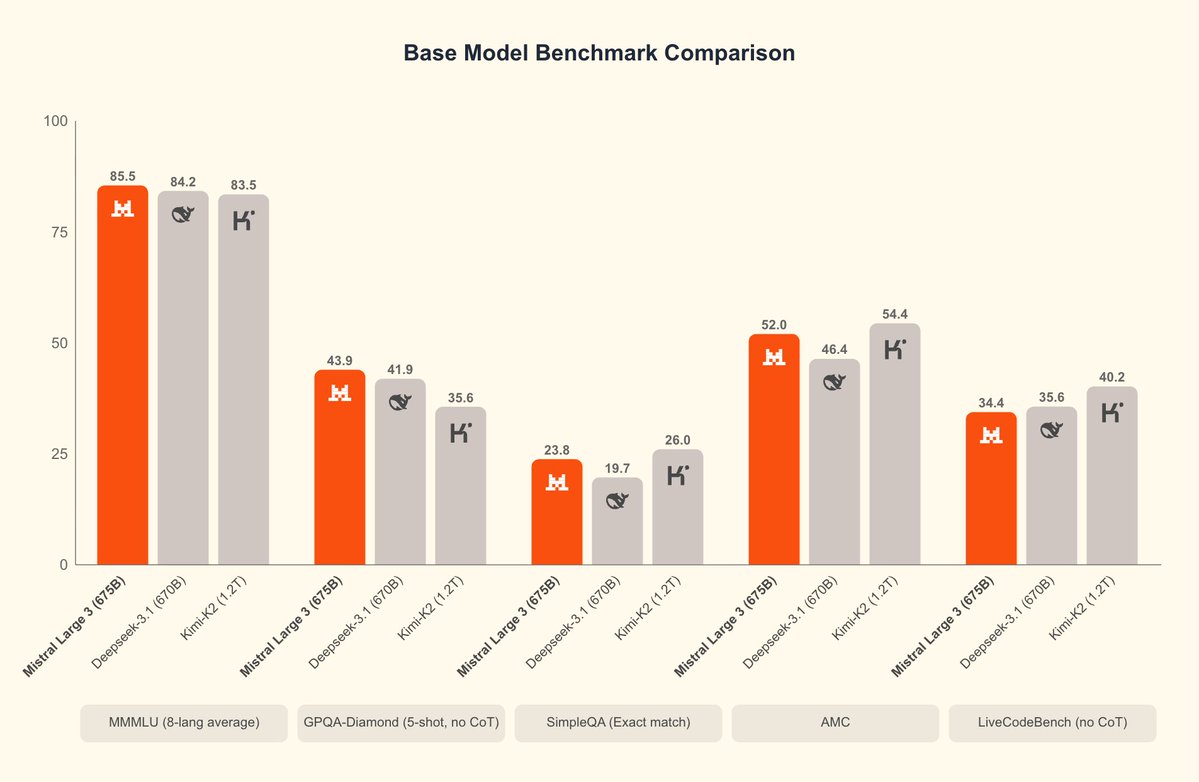
Mistral acaba de lanzar Mistral 3 y su MoE de gran tamaño más potente: Mistral Large 3, que destaca por su comprensión de imágenes y diálogos multilingües. Mistral Large 3, parámetros totales 675B, activación 41B, libera simultáneamente pesos base e instruidos; la versión de inferencia se publicará más adelante. Proporciona el formato de compresión NVFP4, lo que permite una inferencia de alta eficiencia en un solo nodo con 8×A100/H100 o Blackwell NVL72, y admite TensorRT-LLM, SGLang, separación de prellenado/decodificación, decodificación especulativa, etc. La serie Ministral 3 tiene tres modelos. Los modelos 3B, 8B y 14B ofrecen tres variantes cada uno: base, instrucción y razonamiento, y todos admiten la entrada de imágenes. Ofrece la mejor relación rendimiento-precio de su clase, igualando a modelos similares en rendimiento y generando un orden de magnitud menos de tokens. La versión de razonamiento puede lograr el 85% AIME '25 en 14B. #Mistral3 #MistralGrande3
Blomistral.ai/news/mistral-3TmA huggingface.co/collections/mi…://t.co/qlCFYKgF3J